 Data Science
·
Engineering
Data Science
·
Engineering
Data First, SLA Always





Introducing Trailblazer, the Data Engineering team’s solution to implementing change data capture of all upstream databases. In this article, we introduce the reason why we needed to move away from periodic batch ingestion towards a real time solution and show how we achieved this through an end to end streaming pipeline.
Context
Our mission as Grab’s Data Engineering team is to fulfil 100% of SLAs for data availability to our downstream users. Our 40 person team is responsible for providing accurate and reliable data to data analysts and data scientists so that they can produce actionable reports that will help Grab’s leadership team make data-driven decisions. We maintain data for a variety of business intelligence tools such as Tableau, Presto and Holistics as well as predictive algorithms for all of Grab.
We ingest data from multiple upstream sources, such as relational databases, Kafka or third party applications such as Salesforce or Zendesk. The majority of these source data exists in MySQL and we run ETL pipelines to mirror any updates into our data lake. These pipelines are triggered on an hourly or daily basis and are powered by an in-house Loader application which performs Spark batch ingestion and loading of data from source to sink.
Problems with the Loader application started to surface when Grab’s data exceeded the petabyte threshold. As such for larger tables, the most practical method to ingest data was to perform ETL only on rows that were updated within a specified timeframe. This is akin to issuing the query
SELECT * FROM table WHERE updated >= [start_time] AND updated < [end_time]
Now imagine two situations. One, firing this query to a huge table without an updated field. Two, firing the same query to the huge table, this time without indexes on the updated field. In the first scenario, the query will never work and we can never perform incremental ingestion on the table based on a timed window. The second scenario carries the dangers of creating high CPU load to replicate the database that we are querying from. Neither has an ideal outcome.
One other problem that we identified was the unpredictability of growth in data volume. Tables smaller than one gigabyte were ingested by fully scanning the table and overwriting the data in the data lake. This worked out well for us until the table size increased exponentially, at which point our Spark jobs failed due to JDBC timeouts. If we were only dealing with a handful of tables, this issue could have been addressed by switching our data ingestion strategy from full scan to a timed window.
When assessing the issue, we discovered that there were hundreds of tables running under the full scan strategy, all of them potentially crashing our data system, all time bombs silently waiting to explode.
The team urgently needed a new approach to ETL. Our Loader application was highly coupled to upstream table characteristics. We needed to find solutions that were truly scalable, which meant decoupling our pipelines from the upstream.
Change Data Capture (CDC)
Much like event sourcing, any log change to the database is captured and streamed out for downstream applications to consume. This process is lightweight since any row level update to the table is instantly captured by a real time processor, avoiding the need for large chunked queries on the table. In addition, CDC works regardless of upstream table definition, so we do not need to worry about missing updated columns impacting our data migration process.
Binary Logs (binlogs) are the CDC agents of MySQL. All updates, insertions or deletions performed on the table are captured as a series of logged events containing the past state of the row and it’s newly modified state. Check out the binlogs reference to find out more.
In order to persist all binlogs generated upstream, our team created a Spark Structured Streaming application called Trailblazer. Trailblazer streams all MySQL binlogs to our data lake. These binlogs serve as a foundation for us to build Presto tables for data auditing and help to remove the direct dependency of our batch ETL jobs to the source MySQL.
Trailblazer is an amalgamation of various data streaming stacks. Binlogs are captured by Debezium which runs on Kafka connect clusters. All binlogs are sent to our Kafka cluster, which is managed by the Data Engineering Infrastructure team and are streamed out to a real time bucket via a Spark structured streaming application. Hourly or daily ETL compaction jobs ingests the change logs from the real time bucket to materialise tables for downstream users to consume.
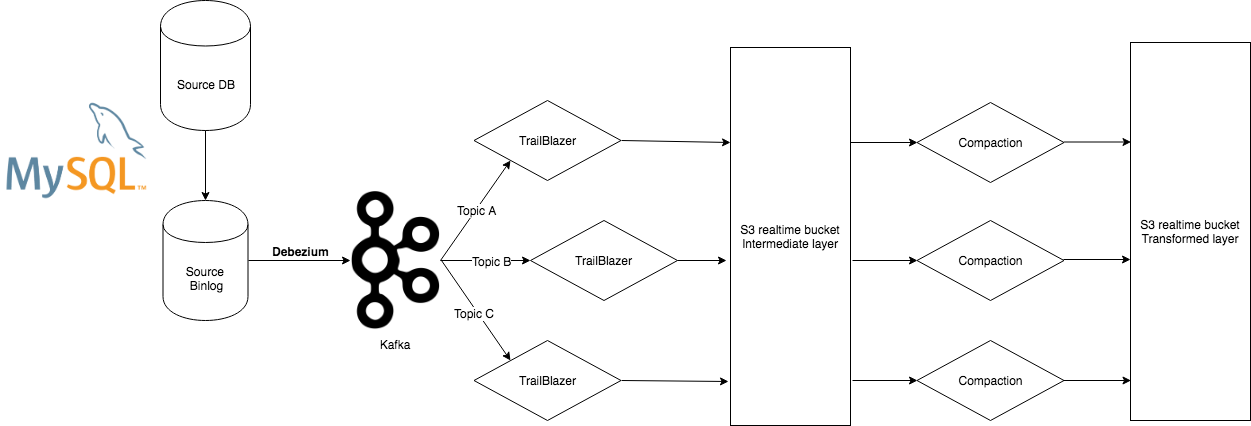 CDC in action where binlogs are streamed to Kafka via Debezium before being consumed by Trailblazer streaming & compaction services
CDC in action where binlogs are streamed to Kafka via Debezium before being consumed by Trailblazer streaming & compaction services
Some Statistics
To date, we are streaming hundreds of tables across 60 Spark streaming jobs and with the constant increase in Grab’s database instances, the numbers are expected to keep growing.
Designing Trailblazer Streams
We built our streaming application using Spark structured streaming 2.3. Structured streaming was designed to remove the technical aspects of provisioning streams. Developers can focus on perfecting business logic without worrying about fundamentals such as checkpoint management or reading and writing to data sources.
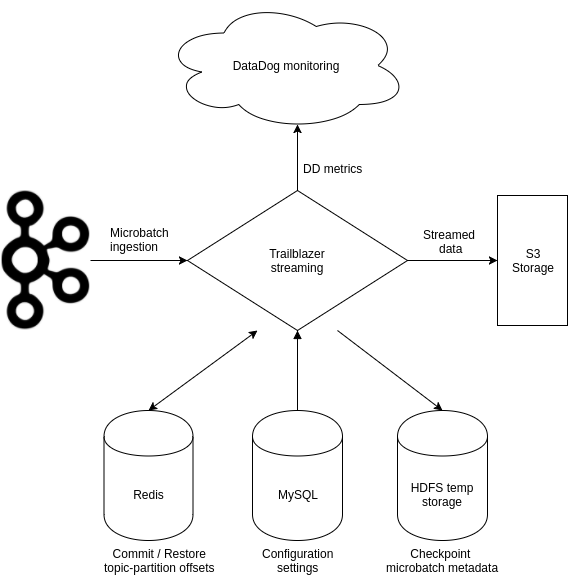 Key architecture for Trailblazer streaming
Key architecture for Trailblazer streaming
In the design phase, we made sure to follow several key principles that helped in managing our streams.
Checkpoints Have to be Externally Managed
Structured streaming manages checkpoints both in a local directory and in a ‘_metadata’ directory on S3 buckets, such that the state of the stream can be restored in the event of failure and restart.
This is all well and good, with two exceptions. First, changing the starting point of data ingestion meant ssh-ing into the machine and manipulating metadata, which could be extremely dangerous. Second, we could not assume cluster prevalence since clusters can die and be recreated with data erased from its local disk or the distributed file system.
Our solution was to do a work around at the application level. All checkpoints will be stored in temporary directories with the existing timestamp appended as path (eg /tmp/checkpoint/job_A/1560697200/… ). A linearly progressive timestamp guarantees that the same directory will never be reused by new instances of the stream. This explains why we never restore its state from local disk but instead, store all checkpoints in a highly available Redis cluster, with key as the Kafka topic and value as a JSON of partition : offset.
Key
debz-schema-A.schema_A.table_B
Value
{"11":19183566,"12":19295602,"13":18992606[[a]](#cmnt1)[[b]](#cmnt2)[[c]](#cmnt3)[[d]](#cmnt4)[[e]](#cmnt5)[[f]](#cmnt6),"14":19269499,"15":19197199,"16":19060873,"17":19237853,"18":19107959,"19":19188181,"0":19193976,"1":19072585,"2":19205764,"3":19122454,"4":19231068,"5":19301523,"6":19287447,"7":19418871,"8":19152003,"9":19112431,"10":19151479}
Fortunately, structured streaming provides the StreamQueryListener class which we can use to register checkpoints after the completion of each microbatch.
Streams Must Handle 0, 1 or 1 Million Data
Scalability is at the heart of all well-designed applications. Spark streaming jobs are built for scalability in the face of varying data volumes.
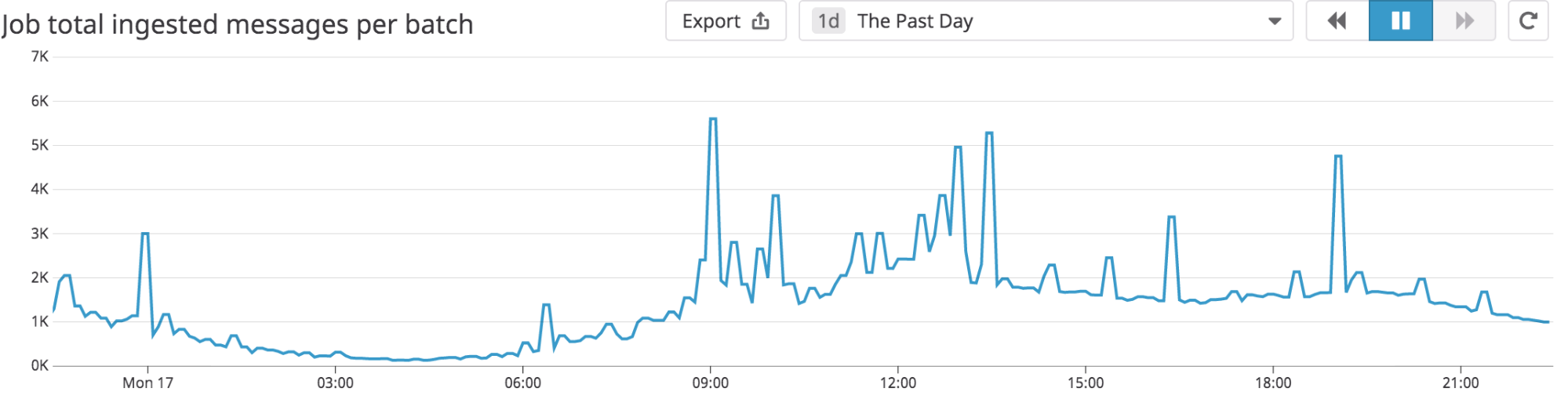 In general, the rate of messages input to Kafka is cyclical across 24 hrs. Streaming jobs should be robust enough to handle data loads during peak hours of the day without breaching microbatch timing
In general, the rate of messages input to Kafka is cyclical across 24 hrs. Streaming jobs should be robust enough to handle data loads during peak hours of the day without breaching microbatch timing
There are a few settings that we can configure to influence the degree of scalability for a streaming app:
- spark.dynamicAllocation.enabled=true gives spark autonomy to provision / revoke executors to suit the workload
- spark.dynamicAllocation.maxExecutors controls the maximum job parallelism
- maxOffsetsPerTrigger controls the maximum number of messages ingested from Kafka per microbatch
- trigger controls the duration between microbatchs and is a property of the DataStreamWriter class
Data as Key Health Indicator
Scaling the number of streaming jobs without prior collection of performance metrics is a bad idea. There is a high chance that you will discover a dead stream when checking your stream hours after initialisation. I’ll cite Murphy’s law as proof.
Thus we vigilantly monitored our data streams. We used tools such as Datadog for metric monitoring, Slack for oncall issue reporting, PagerDuty for urgent cases and our inhouse data auditor as a service (DASH) for counts discrepancy reporting between streamed and source data. More details on monitoring will be discussed in the later part.
Streams are Ephemeral
Streams may die due to a hundred and one reasons so don’t blame yourself or your programming insecurities. Issues with upstream dependencies, such as a node within your Kafka cluster running out of disk space, could lead to partition unavailability which would crash the application. On one occasion, our streaming application was unable to resolve DNS when writing to AWS S3 storage. This amounted to multiple failures within our Spark job that eventually culminated in the termination of the stream.
In this case, allow the stream to shutdown gracefully, send out your alerts and have a mechanism in place to retry the failed stream. We run all streaming jobs on Airflow and any failure to the stream will automatically be retried through a new task issued by the scheduler.
If you have had experience with large scale management of streams, please leave a comment so we can continue this discussion!
Monitoring Data Streams
Here are some key features that were set up to monitor our streams.
Running : Active Jobs Ratio
The number of streaming jobs could increase in the future, thus becoming a challenge for the oncall team to track all jobs that are supposed to be up and running.
One proposal is to track the number of jobs in production against the number of jobs that are actually running. By querying MySQL tables, we can filter out all the jobs that are meant to be active. Since Trailblazer streams are spark-submit jobs managed by YARN, we can query YARN’s resource manager REST API to retrieve all the jobs that are running. We then construct a ratio of running : active jobs and report them to Datadog. If the ratio is not 1 for an extended duration, an alert will be issued for the oncall to take action.
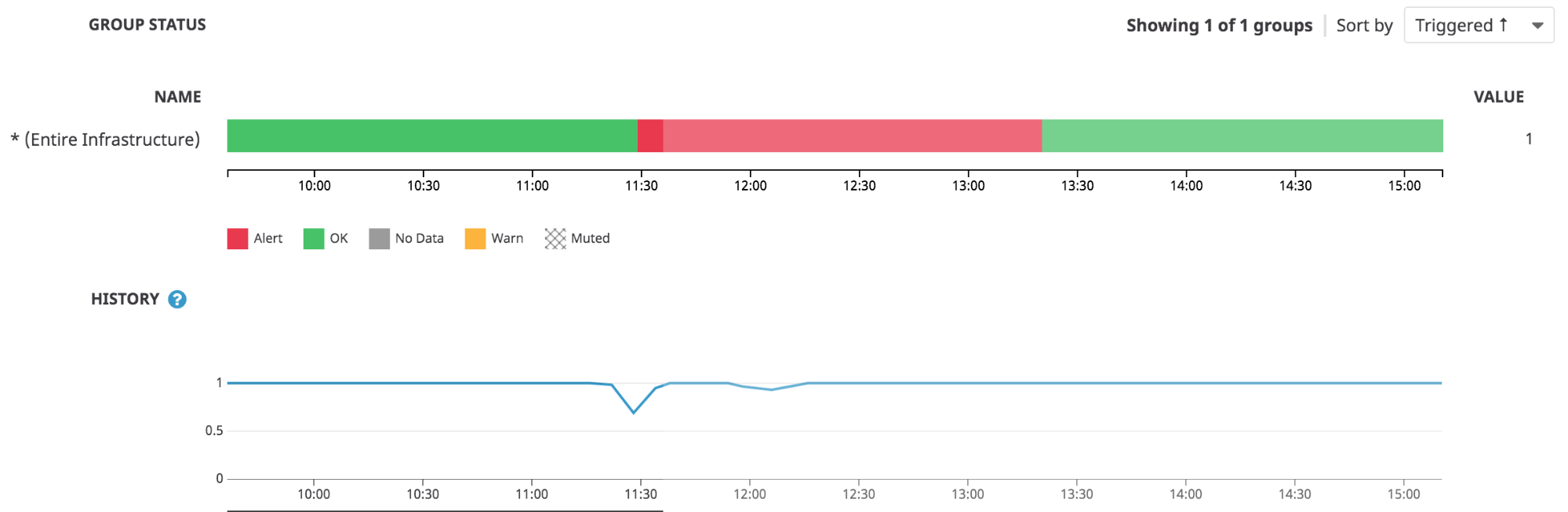 If the ratio of running : active jobs falls below 1 for a period of time, we will immediately trigger an alert
If the ratio of running : active jobs falls below 1 for a period of time, we will immediately trigger an alert
Microbatch Runtime
We define a 30 second window for each microbatch and track the actual runtime using metrics reported by the query listener. A runtime that exceeds the designated window is a potential indicator that the streaming job is deprived of resources and needs to be scaled up.
Job Liveliness
Each job reports its health by emitting a count of 1 heartbeat. This heartbeat is created at the end of every microbatch via a query listener. This process is useful in detecting stale jobs (jobs that are registered as RUNNING in YARN but are actually hung).
Kafka Offset Divergence
In order to ensure that the message output rate to the consumer exceeds the message input rate from the producer, we sum up all presently ingested topic-partition offsets and compare that value to the sum of all topic-partition end offsets in Kafka. We then add an alerting logic on top of these metrics to inform the oncall team if the difference between the two values grows too big.
It is important to track the offset divergence parameter as streams can be lagging. Should the rate of consumption fall below the rate of message production, we would run the risk of falling short of Kafka’s retention window, leading to data losses.
Hourly Data Checks
DASH runs hourly and serves as our first line of defence to detect any data quality issues within the streams. We issue queries to the source database and our streaming layer to confirm that the ID counts of data created within the last hour match.
DASH helps in the early detection of upstream issues. We have noticed cases where our Debezium connectors failed and our checker reported fewer data than expected since there were no incoming messages to Kafka.

 DASH matches and mismatches reported to Slack
DASH matches and mismatches reported to Slack
Materialising Tables Through Compaction
Having CDC data in our data lake does not conclude our responsibilities. Batched compaction allows us to apply all captured CDC, to be available as Presto tables for downstream consumption. The job is set to trigger hourly and process all changes to the database within the past hour. For example, changes to a record are visible in real-time, but the latest state of the record will not be reflected until the next time a batch job runs. We addressed several issues with streaming during this phase.
Deduplication of Data
Trailblazer was not built to deliver exactly once guarantees. We ensure that the issues regarding duplicated CDCs are addressed during compaction.
Availability of All Data Until a Certain Hour
We want to make sure that downstream pipelines use output data of the hourly batch job only when the pipeline has all records for that hour. In case there is an event that is processed late by streaming, the current pipeline will wait until the data is completed. In this case, we are consciously choosing consistency over availability for our downstream users. For example, missing a few insert booking records in peak hours due to consumer processing delay can generate the wrong downstream results leading to miscalculation in revenue. We want to start downstream processes only when the data for the hour or day is complete.
Need for the Latest State of Each Event
Our compaction job performs upserts on the data to ensure that our downstream users can consume records in their latest state.
Future Applications
Trailblazer is a milestone for the Data Engineering team as it represents our commitment to achieve large scale data streams to reduce latencies for our end users. Moving ahead, our team will be exploring how we can further optimise streaming jobs by analysing data trends over time and to build applications such as snapshot tables on top of the CDCs being streamed in our data lake.