 Engineering
·
Data Science
Engineering
·
Data Science
LLM-powered data classification for data entities at scale








Introduction
At Grab, we deal with PetaByte-level data and manage countless data entities ranging from database tables to Kafka message schemas. Understanding the data inside is crucial for us, as it not only streamlines the data access management to safeguard the data of our users, drivers and merchant-partners, but also improves the data discovery process for data analysts and scientists to easily find what they need.
The Caspian team (Data Engineering team) collaborated closely with the Data Governance team on automating governance-related metadata generation. We started with Personal Identifiable Information (PII) detection and built an orchestration service using a third-party classification service. With the advent of the Large Language Model (LLM), new possibilities dawned for metadata generation and sensitive data identification at Grab. This prompted the inception of the project, which aimed to integrate LLM classification into our existing service. In this blog, we share insights into the transformation from what used to be a tedious and painstaking process to a highly efficient system, and how it has empowered the teams across the organisation.
For ease of reference, here’s a list of terms we’ve used and their definitions:
- Data Entity: An entity representing a schema that contains rows/streams of data, for example, database tables, stream messages, data lake tables.
- Prediction: Refers to the model’s output given a data entity, unverified manually.
- Data Classification: The process of classifying a given data entity, which in the context of this blog, involves generating tags that represent sensitive data or Grab-specific types of data.
- Metadata Generation: The process of generating the metadata for a given data entity. In this blog, since we limit the metadata to the form of tags, we often use this term and data classification interchangeably.
- Sensitivity: Refers to the level of confidentiality of data. High sensitivity means that the data is highly confidential. The lowest level of sensitivity often refers to public-facing or publicly-available data.
Background
When we first approached the data classification problem, we aimed to solve something more specific - Personal Identifiable Information (PII) detection. Initially, to protect sensitive data from accidental leaks or misuse, Grab implemented manual processes and campaigns targeting data producers to tag schemas with sensitivity tiers. These tiers ranged from Tier 1, representing schemas with highly sensitive information, to Tier 4, indicating no sensitive information at all. As a result, half of all schemas were marked as Tier 1, enforcing the strictest access control measures.
The presence of a single Tier 1 table in a schema with hundreds of tables justifies classifying the entire schema as Tier 1. However, since Tier 1 data is rare, this implies that a large volume of non-Tier 1 tables, which ideally should be more accessible, have strict access controls.
Shifting access controls from the schema-level to the table-level could not be done safely due to the lack of table classification in the data lake. We could have conducted more manual classification campaigns for tables, however this was not feasible for two reasons:
- The volume, velocity, and variety of data had skyrocketed within the organisation, so it took significantly more time to classify at table level compared to schema level. Hence, a programmatic solution was needed to streamline the classification process, reducing the need for manual effort.
- App developers, despite being familiar with the business scope of their data, interpreted internal data classification policies and external data regulations differently, leading to inconsistencies in understanding.
A service called Gemini (named before Google announced the Gemini model!) was built internally to automate the tag generation process using a third party data classification service. Its purpose was to scan the data entities in batches and generate column/field level tags. These tags would then go through a review process by the data producers. The data governance team provided classification rules and used regex classifiers, alongside the third-party tool’s own machine learning classifiers, to discover sensitive information.
After the implementation of the initial version of Gemini, a few challenges remained.
- The third-party tool did not allow customisations of its machine learning classifiers, and the regex patterns produced too many false positives during our evaluation.
- Building in-house classifiers would require a dedicated data science team to train a customised model. They would need to invest a significant amount of time to understand data governance rules thoroughly and prepare datasets with manually labelled training data.
LLM came up on our radar following its recent “iPhone moment” with ChatGPT’s explosion onto the scene. It is trained using an extremely large corpus of text and contains trillions of parameters. It is capable of conducting natural language understanding tasks, writing code, and even analysing data based on requirements. The LLM naturally solves the mentioned pain points as it provides a natural language interface for data governance personnel. They can express governance requirements through text prompts, and the LLM can be customised effortlessly without code or model training.
Methodology
In this section, we dive into the implementation details of the data classification workflow. Please refer to the diagram below for a high-level overview:
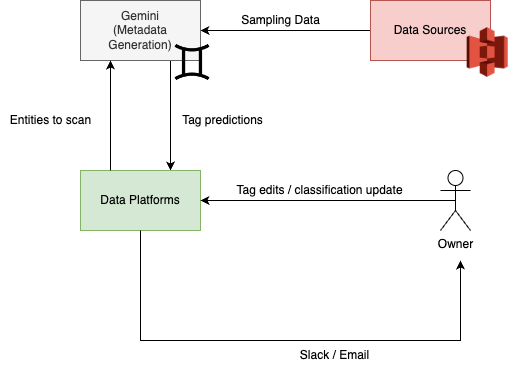
This diagram illustrates how data platforms, the metadata generation service (Gemini), and data owners work together to classify and verify metadata. Data platforms trigger scan requests to the Gemini service to initiate the tag classification process. After the tags are predicted, data platforms consume the predictions, and the data owners are notified to verify these tags.
Orchestration
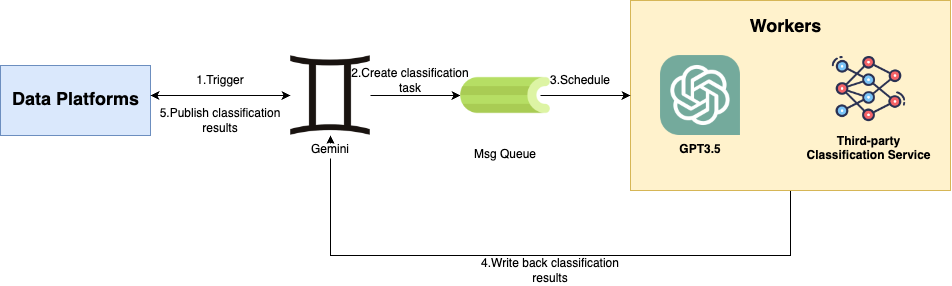
Our orchestration service, Gemini, manages the data classification requests from data platforms. From the diagram, the architecture contains the following components:
- Data platforms: These platforms are responsible for managing data entities and initiating data classification requests.
- Gemini: This orchestration service communicates with data platforms, schedules and groups data classification requests.
- Classification engines: There are two available engines (a third-party classification service and GPT3.5) for executing the classification jobs and return results. Since we are still in the process of evaluating two engines, both of the engines are working concurrently.
When the orchestration service receives requests, it helps aggregate the requests into reasonable mini-batches. Aggregation is achievable through the message queue at fixed intervals. In addition, a rate limiter is attached at the workflow level. It allows the service to call the Cloud Provider APIs with respective rates to prevent the potential throttling from the service providers.
Specific to LLM orchestration, there are two limits to be mindful of. The first one is the context length. The input length cannot surpass the context length, which was 4000 tokens for GPT3.5 at the time of development (or around 3000 words). The second one is the overall token limit (since both the input and output share the same token limit for a single request). Currently, all Azure OpenAI model deployments share the same quota under one account, which is set at 240K tokens per minute.
Classification
In this section, we focus on LLM-powered column-level tag classification. The tag classification process is defined as follows:
Given a data entity with a defined schema, we want to tag each field of the schema with metadata classifications that follow an internal classification scheme from the data governance team. For example, the field can be tagged as a <particular kind of business metric> or a <particular type of personally identifiable information (PII). These tags indicate that the field contains a business metric or PII.
We ask the language model to be a column tag generator and to assign the most appropriate tag to each column. Here we showcase an excerpt of the prompt we use:
You are a database column tag classifier, your job is to assign the most appropriate tag based on table name and column name. The database columns are from a company that provides ride-hailing, delivery, and financial services. Assign one tag per column. However not all columns can be tagged and these columns should be assigned <None>. You are precise, careful and do your best to make sure the tag assigned is the most appropriate.
The following is the list of tags to be assigned to a column. For each line, left hand side of the : is the tag and right hand side is the tag definition
…
<Personal.ID> : refers to government-provided identification numbers that can be used to uniquely identify a person and should be assigned to columns containing "NRIC", "Passport", "FIN", "License Plate", "Social Security" or similar. This tag should absolutely not be assigned to columns named "id", "merchant id", "passenger id", “driver id" or similar since these are not government-provided identification numbers. This tag should be very rarely assigned.
<None> : should be used when none of the above can be assigned to a column.
…
Output Format is a valid json string, for example:
[{
"column_name": "",
"assigned_tag": ""
}]
Example question
`These columns belong to the "deliveries" table
1. merchant_id
2. status
3. delivery_time`
Example response
[{
"column_name": "merchant_id",
"assigned_tag": "<Personal.ID>"
},{
"column_name": "status",
"assigned_tag": "<None>"
},{
"column_name": "delivery_time",
"assigned_tag": "<None>"
}]
We also curated a tag library for LLM to classify. Here is an example:
| Column-level Tag | Definition |
|---|---|
| Personal.ID | Refers to external identification numbers that can be used to uniquely identify a person and should be assigned to columns containing "NRIC", "Passport", "FIN", "License Plate", "Social Security" or similar. |
| Personal.Name | Refers to the name or username of a person and should be assigned to columns containing "name", "username" or similar. |
| Personal.Contact_Info | Refers to the contact information of a person and should be assigned to columns containing "email", "phone", "address", "social media" or similar. |
| Geo.Geohash | Refers to a geohash and should be assigned to columns containing "geohash" or similar. |
| None | Should be used when none of the above can be assigned to a column. |
The output of the language model is typically in free text format, however, we want the output in a fixed format for downstream processing. Due to this nature, prompt engineering is a crucial component to make sure downstream workflows can process the LLM’s output.
Here are some of the techniques we found useful during our development:
- Articulate the requirements: The requirement of the task should be as clear as possible, LLM is only instructed to do what you ask it to do.
- Few-shot learning: By showing the example of interaction, models understand how they should respond.
- Schema Enforcement: Leveraging its ability of understanding code, we explicitly provide the DTO (Data Transfer Object) schema to the model so that it understands that its output must conform to it.
- Allow for confusion: In our prompt we specifically added a default tag – the LLM is instructed to output the default
<None>tag when it cannot make a decision or is confused.
Regarding classification accuracy, we found that it is surprisingly accurate with its great semantic understanding. For acknowledged tables, users on average change less than one tag. Also, during an internal survey done among data owners at Grab in September 2023, 80% reported that this new tagging process helped them in tagging their data entities.
Publish and verification
The predictions are published to the Kafka queue to downstream data platforms. The platforms inform respective users weekly to verify the classified tags to improve the model’s correctness and to enable iterative prompt improvement. Meanwhile, we plan to remove the verification mandate for users once the accuracy reaches a certain level.

Impact
Since the new system was rolled out, we have successfully integrated this with Grab’s metadata management platform and production database management platform. Within a month since its rollout, we have scanned more than 20,000 data entities, averaging around 300-400 entities per day.
Using a quick back-of-the-envelope calculation, we can see the significant time savings achieved through automated tagging. Assuming it takes a data owner approximately 2 minutes to classify each entity, we are saving approximately 360 man-days per year for the company. This allows our engineers and analysts to focus more on their core tasks of engineering and analysis rather than spending excessive time on data governance.
The classified tags pave the way for more use cases downstream. These tags, in combination with rules provided by data privacy office in Grab, enable us to determine the sensitivity tier of data entities, which in turn will be leveraged for enforcing the Attribute-based Access Control (ABAC) policies and enforcing Dynamic Data Masking for downstream queries. To learn more about the benefits of ABAC, readers can refer to another engineering blog posted earlier.
Cost wise, for the current load, it is extremely affordable contrary to common intuition. This affordability enables us to scale the solution to cover more data entities in the company.
What’s next?
Prompt improvement
We are currently exploring feeding sample data and user feedback to greatly increase accuracy. Meanwhile, we are experimenting on outputting the confidence level from LLM for its own classification. With confidence level output, we would only trouble users when the LLM is uncertain of its answers. Hopefully this can remove even more manual processes in the current workflow.
Prompt evaluation
To track the performance of the prompt given, we are building analytical pipelines to calculate the metrics of each version of the prompt. This will help the team better quantify the effectiveness of prompts and iterate better and faster.
Scaling out
We are also planning to scale out this solution to more data platforms to streamline governance-related metadata generation to more teams. The development of downstream applications using our metadata is also on the way. These exciting applications are from various domains such as security, data discovery, etc.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!