
Scaling Grab's Data Lake: Our journey to Apache Iceberg adoption
As Grab's Data Lake grew to petabytes, the limitations of Hive Parquet became clear, from catalog latency and small files to manual partition management. This blog shares our journey adopting Apache Iceberg as our default table format: why we chose it, how we rolled it out at scale, the tooling we built along the way, and the lessons we learned.
More articles

Migrating Counter Service storage: Design choices and learnings

Scaling out Distroless adoption With AI
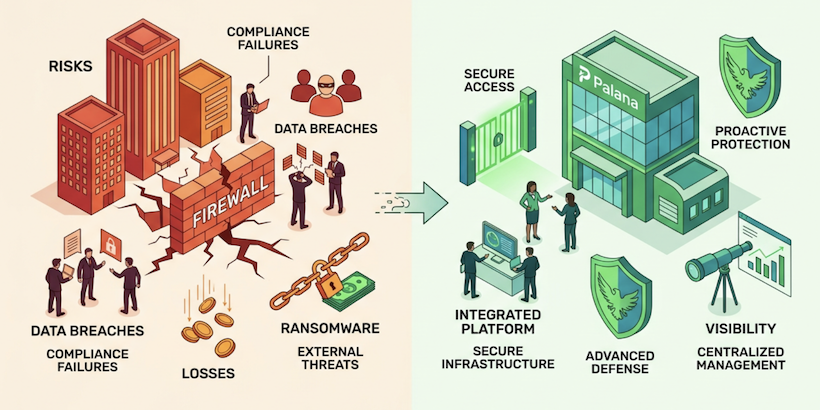
Palana (Part 2): Architecting isolation, identity, and auditability for AI agents

Palana (Part 1): Why Grab built a secure platform for autonomous AI Agents

From decentralized Docs-as-Code to a centralized repository: Evolving Grab's documentation strategy

The Hugo evolution: Engineering Grab's unified, one-click data ingestion platform with Apache Flink

Scaling developer experience: How we improved Android Studio in a large monorepo

Enhancing Flink deployment with shadow testing
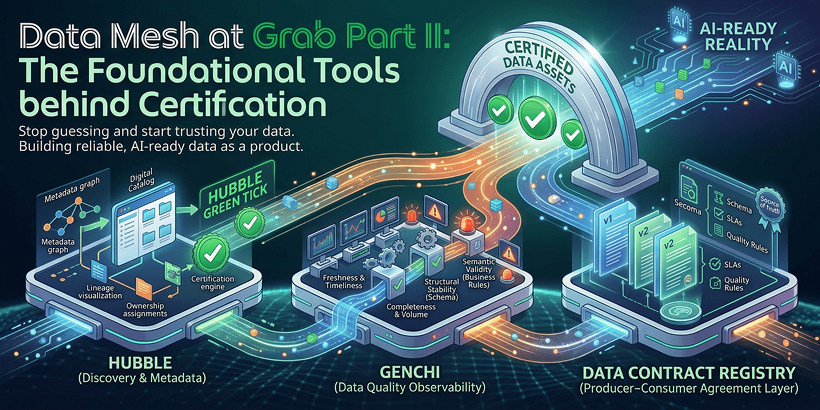
Data Mesh at Grab (Part II): The foundational tools behind certification
Articles
Scaling Grab's Data Lake: Our journey to Apache Iceberg adoption
Migrating Counter Service storage: Design choices and learnings
Scaling out Distroless adoption With AI
Palana (Part 2): Architecting isolation, identity, and auditability for AI agents
Palana (Part 1): Why Grab built a secure platform for autonomous AI Agents
From decentralized Docs-as-Code to a centralized repository: Evolving Grab's documentation strategy
The Hugo evolution: Engineering Grab's unified, one-click data ingestion platform with Apache Flink
Scaling developer experience: How we improved Android Studio in a large monorepo
Enhancing Flink deployment with shadow testing
Data Mesh at Grab (Part II): The foundational tools behind certification
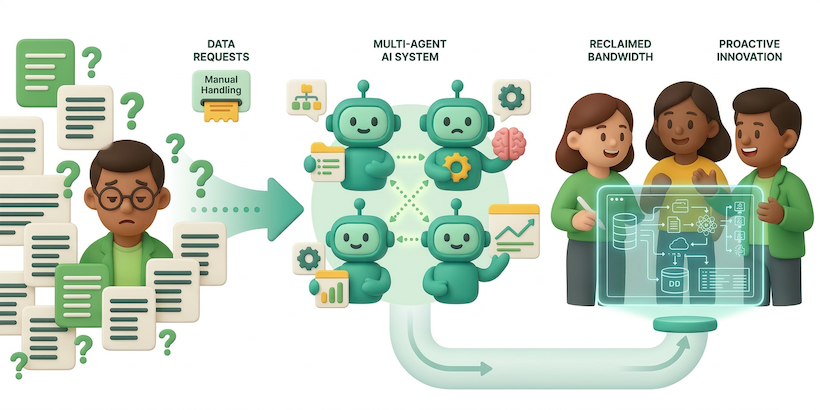
From firefighting to building: How AI agents restored our team’s core productivity

Enabling R8 optimization at scale with AI-assisted debugging

Reclaiming Terabytes: Optimizing Android image caching with TLRU

Cursor at Grab: Adoption and impact

Docker lazy loading at Grab: Accelerating container startup times

From deployment slop to production reality: How BriX bridges the gap with enterprise-grade AI infrastructure

Demystifying user journeys: Revolutionizing troubleshooting with auto tracking
How Grab is accelerating growth with real-time personalization using Customer Data Platform scenarios

A Decade of Defense: Celebrating Grab's 10th Year Bug Bounty Program

Real-time data quality monitoring: Kafka stream contracts with syntactic and semantic test

SpellVault’s evolution: Beyond LLM apps, towards the agentic future

Grab's Mac Cloud Exit supercharges macOS CI/CD
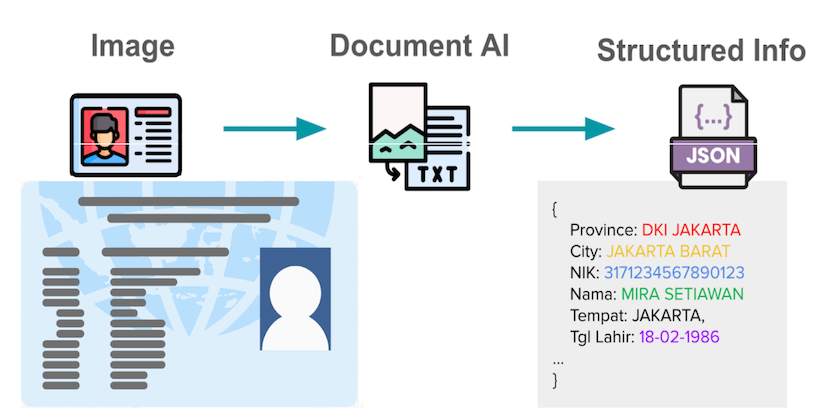
How we built a custom vision LLM to improve document processing at Grab

Machine-learning predictive autoscaling for Flink

Modernising Grab’s model serving platform with NVIDIA Triton Inference Server

Highly concurrent in-memory counter in GoLang
User foundation models for Grab

Powering Partner Gateway metrics with Apache Pinot

Taming the monorepo beast: Our journey to a leaner, faster GitLab repo

Data mesh at Grab part I: Building trust through certification

The evolution of Grab's machine learning feature store

Grab's service mesh evolution: From Consul to Istio
DispatchGym: Grab’s reinforcement learning research framework

Counter Service: How we rewrote it in Rust

The complete stream processing journey on FlinkSQL

Effortless enterprise authentication at Grab: Dex in action

From failure to success: The birth of GrabGPT, Grab’s internal ChatGPT

Streamlining RiskOps with the SOP agent framework

Introducing the SOP-driven LLM agent frameworks

Evaluating performance impact of removing Redis-cache from a Scylla-backed service

Facilitating Docs-as-Code implementation for users unfamiliar with Markdown

Improving Hugo stability and addressing oncall challenges through automation

Building a Spark observability product with StarRocks: Real-time and historical performance analysis

TechDocs at Grab: Cultivating a culture of quality documentation

Grab AI Gateway: Connecting Grabbers to multiple GenAI providers

Embracing passwordless authentication with Grab’s Passkey
Turbocharging GrabUnlimited with Temporal

How we seamlessly migrated high volume real-time streaming traffic from one service to another with zero data loss and duplication

Supercharging LLM application development with LLM-Kit

How we reduced initialisation time of Product Configuration Management SDK

Metasense V2: Enhancing, improving and productionisation of LLM powered data governance
How we reduced peak memory and CPU usage of the product configuration management SDK

LLM-assisted vector similarity search
Leveraging RAG-powered LLMs for analytical tasks

Evolution of Catwalk: Model serving platform at Grab

Enabling conversational data discovery with LLMs at Grab

Bringing Grab’s Live Activity to Android: Enhancing user experience through custom notifications

Unveiling the process: The creation of our powerful campaign builder

Chimera Sandbox: A scalable experimentation and development platform for Notebook services

How we improved translation experience with cost efficiency

LLM-powered data classification for data entities at scale

Profile-guided optimisation (PGO) on Grab services

How we evaluated the business impact of marketing campaigns

No version left behind: Our epic journey of GitLab upgrades

Ensuring data reliability and observability in risk systems

Grab Experiment Decision Engine - a Unified Toolkit for Experimentation

Iris - Turning observations into actionable insights for enhanced decision making

Android App Size at Scale with Project Bonsai

Enabling near real-time data analytics on the data lake

The journey of building a comprehensive attribution platform

Managing dynamic marketplace content at scale: Grab's approach to content moderation

Rethinking Stream Processing: Data Exploration

Kafka on Kubernetes: Reloaded for fault tolerance

Championing CyberSecurity: Grab's bug bounty programme in 2023

Sliding window rate limits in distributed systems

An elegant platform

Road localisation in GrabMaps

Graph modelling guidelines

Scaling marketing for merchants with targeted and intelligent promos

Stepping up marketing for advertisers: Scalable lookalike audience
Building hyperlocal GrabMaps

Streamlining Grab's Segmentation Platform with faster creation and lower latency

Unsupervised graph anomaly detection - Catching new fraudulent behaviours

Zero traffic cost for Kafka consumers

Go module proxy at Grab

PII masking for privacy-grade machine learning

Performance bottlenecks of Go application on Kubernetes with non-integer (floating) CPU allocation

How we improved our iOS CI infrastructure with observability tools

2.3x faster using the Go plugin to replace Lua virtual machine

Safer deployment of streaming applications

Message Center - Redesigning the messaging experience on the Grab superapp

Evolution of quality at Grab

How OVO determined the right technology stack for their web-based projects

Migrating from Role to Attribute-based Access Control

Securing GitOps pipelines

New zoom freezing feature for Geohash plugin

Graph service platform

Zero trust with Kafka

How KartaCam powers GrabMaps

Graph for fraud detection

Query expansion based on user behaviour

Using mobile sensor data to encourage safer driving

Automatic rule backtesting with large quantities of data

How we store and process millions of orders daily

How we automated FAQ responses at Grab

Graph Networks - 10X investigation with Graph Visualisations

How facial recognition technology keeps you safe

Graph concepts and applications

Automated Experiment Analysis - Making experimental analysis scalable

Search architecture revamp

Embracing a Docs-as-Code approach

Graph Networks - Striking fraud syndicates in the dark

How we reduced our CI YAML files from 1800 lines to 50 lines

How Kafka Connect helps move data seamlessly

Supporting large campaigns at scale

How telematics helps Grab to improve safety

Real-time data ingestion in Grab

Abacus - Issuing points for multiple sources

Exposing a Kafka Cluster via a VPC Endpoint Service
How Grab built a scalable, high-performance ad server

Biometric authentication - Why do we need it?

Using real-world patterns to improve matching in theory and practice

Designing products and services based on Jobs to be Done

Search indexing optimisation

Automating Multi-Armed Bandit testing during feature rollout

How We Cut GrabFood.com’s Page JavaScript Asset Sizes by 3x

Protecting Personal Data in Grab's Imagery

Processing ETL tasks with Ratchet

App Modularisation at Scale

Reshaping Chat Support for Our Users

Debugging High Latency Due to Context Leaks

Building a Hyper Self-Service, Distributed Tracing and Feedback System for Rule & Machine Learning (ML) Predictions

Our Journey to Continuous Delivery at Grab (Part 2)

How We Improved Agent Chat Efficiency with Machine Learning

How Grab Leveraged Performance Marketing Automation to Improve Conversion Rates by 30%

One Small Step Closer to Containerising Service Binaries

Customer Support Workforce Routing

Serving Driver-partners Data at Scale Using Mirror Cache

The GrabMart Journey

Trident - Real-time Event Processing at Scale

Pharos - Searching Nearby Drivers on Road Network at Scale

Reflecting on the Five Years of Bug Bounty at Grab
How Grab is Blazing Through the Superapp Bazel Migration
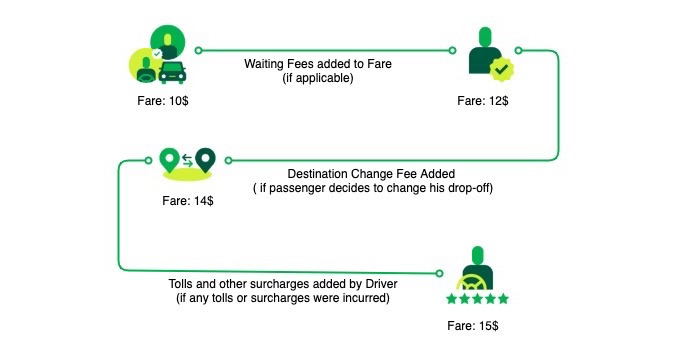
Democratising Fare Storage at Scale Using Event Sourcing

Keeping 170 Libraries Up to Date on a Large Scale Android App

Optimally Scaling Kafka Consumer Applications

Our Journey to Continuous Delivery at Grab (Part 1)
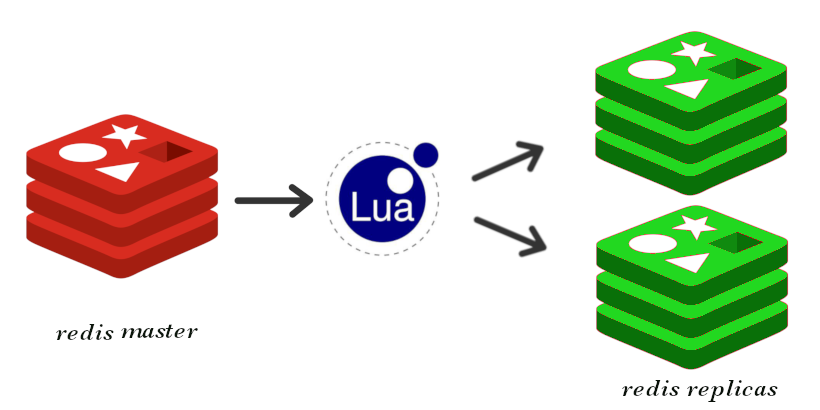
Uncovering the Truth Behind Lua and Redis Data Consistency

Securing and Managing Multi-cloud Presto Clusters with Grab’s DataGateway

Go Modules- A Guide for monorepos (Part 2)

The Journey of Deploying Apache Airflow at Grab

How We Built Our In-house Chat Platform for the Web
Go Modules- A Guide for monorepos (Part 1)
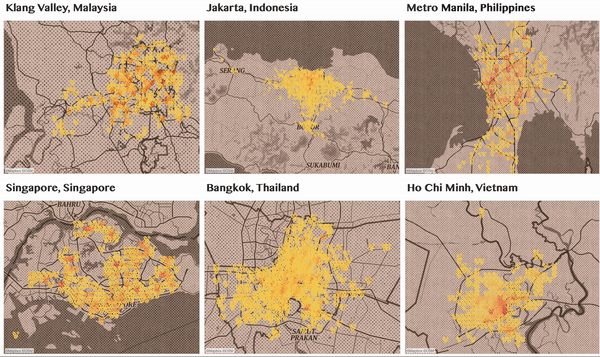
Does Southeast Asia Run on Coffee?
GrabChat Much? Talk Data to Me!

7 Fun Facts about Grab’s Driver-Partners in Singapore

Tackling UI Test Execution Time Imbalance for Xcode Parallel Testing
Returning 575 Terabytes of Storage Space to Our Users
Grab-Posisi - Southeast Asia’s First Comprehensive GPS Trajectory Dataset

How We Prevented App Performance Degradation from Sudden Ride Demand Spikes

Plumbing At Scale

Journey to a Faster Everyday Superapp Where Every Millisecond Counts
Marionette - Enabling E2E User-scenario Simulation

How We Implemented Domain-Driven Development in Golang

Driving Southeast Asia Forward Through People-Focused Design
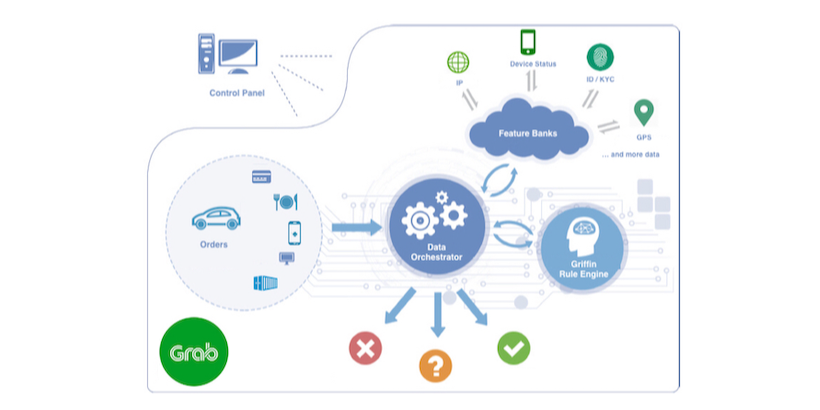
Griffin, an Anti-fraud Risk Rule Engine Making Billions of Predictions Daily

Using Grab’s Trust Counter Service to Detect Fraud Successfully

Being a Principal Engineer at Grab

Data First, SLA Always

Save Your Place with Grab!

No More Forgetting to Input ERP Charges - Hello Automated ERP!

How We Built a Logging Stack at Grab
Making Grab’s Everyday App Super

Catwalk: Serving Machine Learning Models at Scale

React Native in GrabPay

Connecting the Invisibles to Design Seamless Experiences

Tourists on GrabChat!

Bubble Tea Craze on GrabFood!

Why You Should Organise an Immersion Trip for Your Next Project

Preventing Pipeline Calls from Crashing Redis Clusters

Guiding You Door-to-Door via Our Superapp!

Loki, a Dynamic Mock Server for HTTP/TCP Testing

How We Harnessed the Wisdom of Crowds to Improve Restaurant Location Accuracy

Designing Resilient Systems Beyond Retries (Part 3): Architecture Patterns and Chaos Engineering

Designing Resilient Systems Beyond Retries (Part 2): Bulkheading, Load Balancing, and Fallbacks

Designing Resilient Systems Beyond Retries (Part 1): Rate-Limiting

Context Deadlines and How to Set Them

Recipe for Building a Widget: How We Helped to “Peak-Shift” Demand by Helping Passengers Understand Travel Trends

Structured Logging: The Best Friend You’ll Want When Things Go Wrong

How We Simplified Our Data Ingestion & Transformation Process
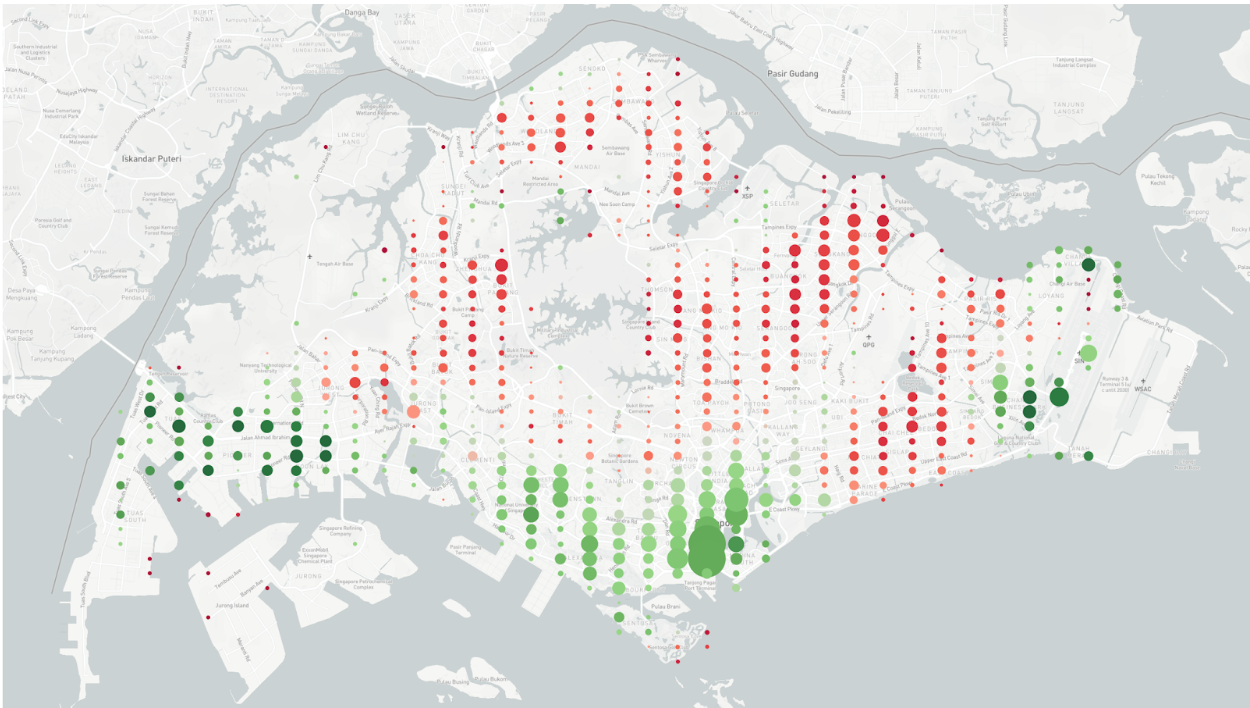
Understanding Supply & Demand in Ride-hailing Through the Lens of Data
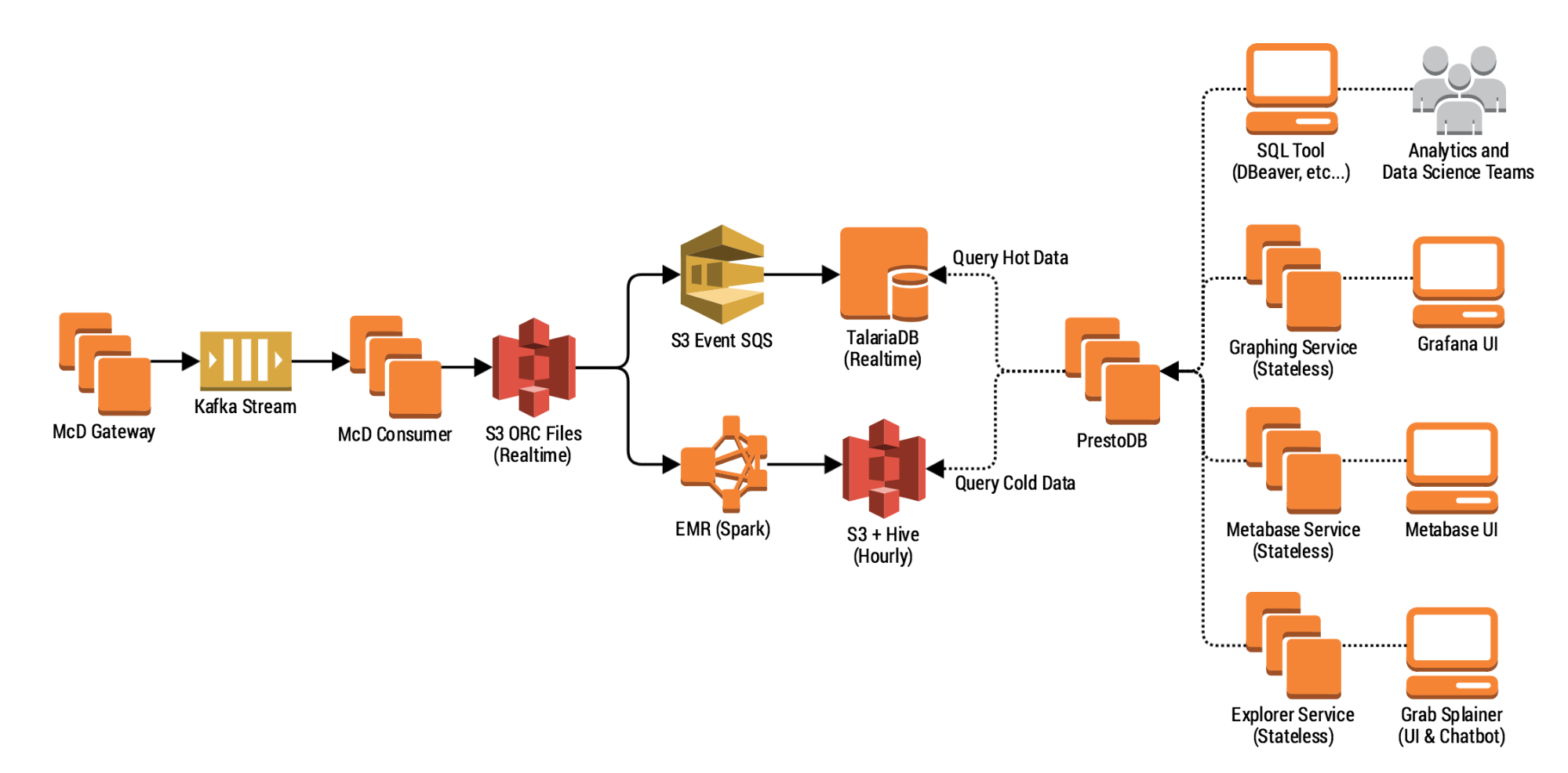
A Lean and Scalable Data Pipeline to Capture Large Scale Events and Support Experimentation Platform

Designing Resilient Systems: Circuit Breakers or Retries? (Part 2)
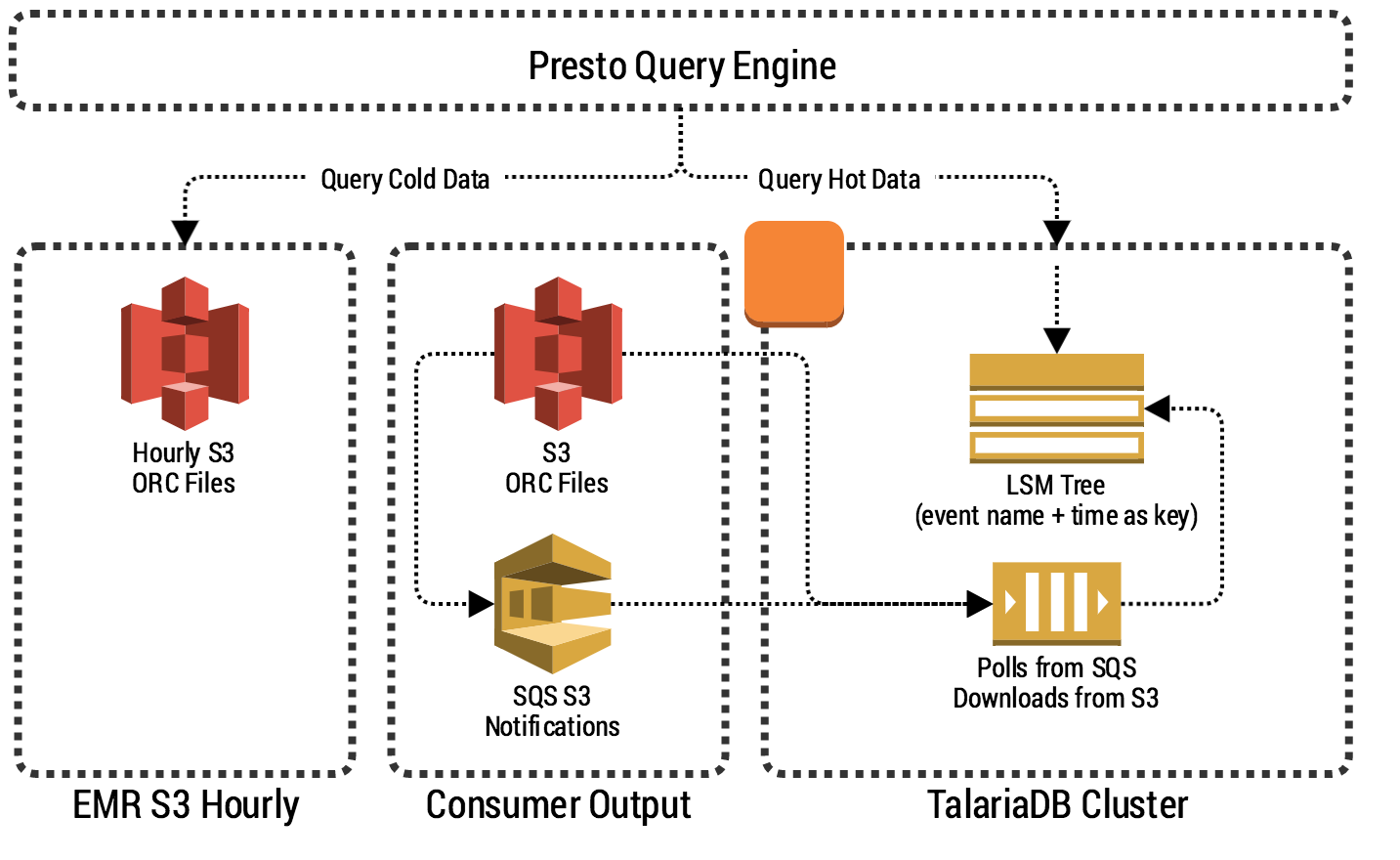
Querying Big Data in Real-time with Presto & Grab's TalariaDB

Designing Resilient Systems: Circuit Breakers or Retries? (Part 1)

Orchestrating Chaos Using Grab's Experimentation Platform
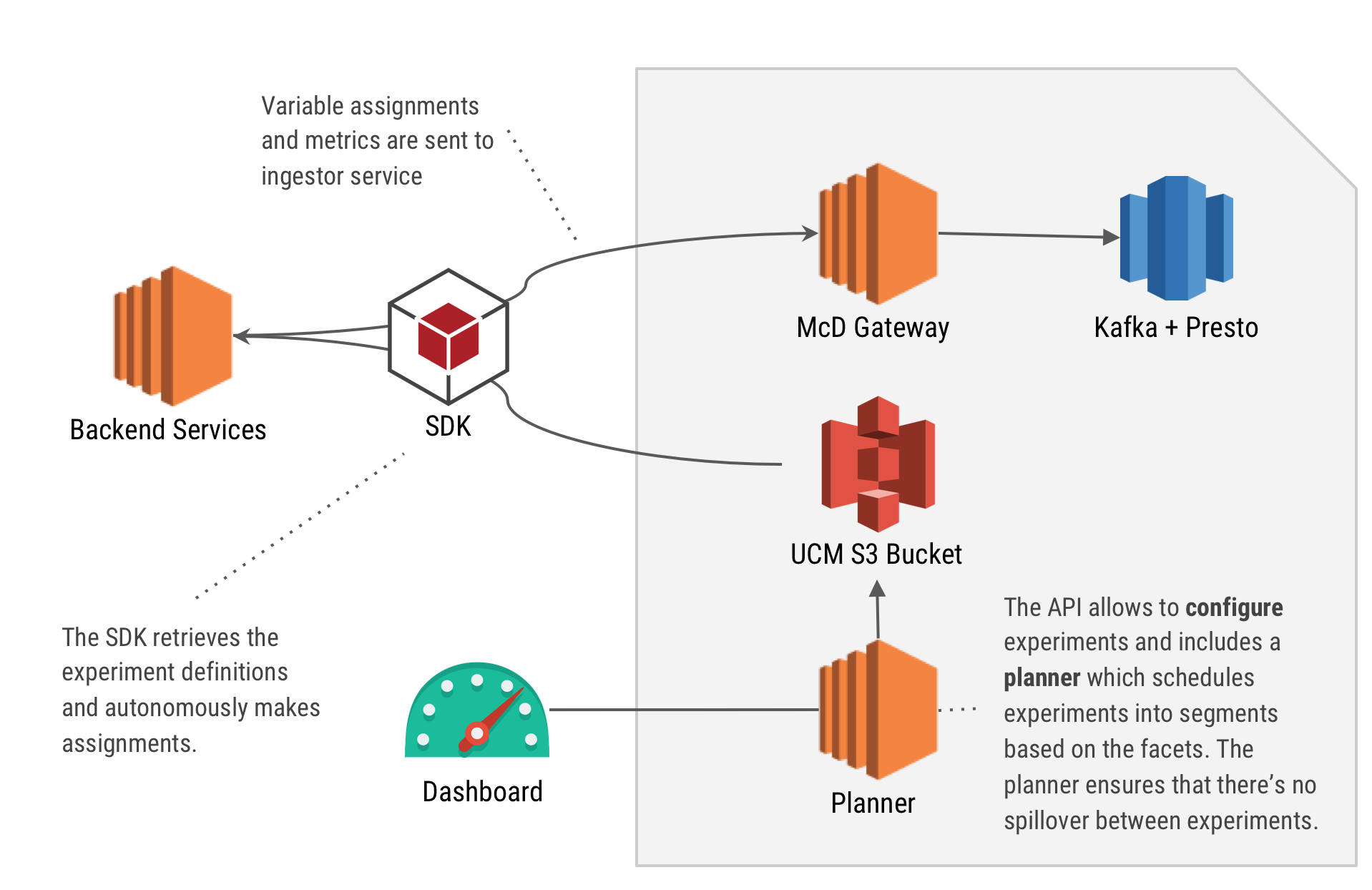
Reliable and Scalable Feature Toggles and A/B Testing SDK at Grab

Mockers - Overcoming Testing Challenges at Grab

Journey of a Tourist via Grab

How We Designed the Quotas Microservice to Prevent Resource Abuse

Grab Senior Data Scientist Liuqin Yang Wins Beale-Orchard-Hays Prize
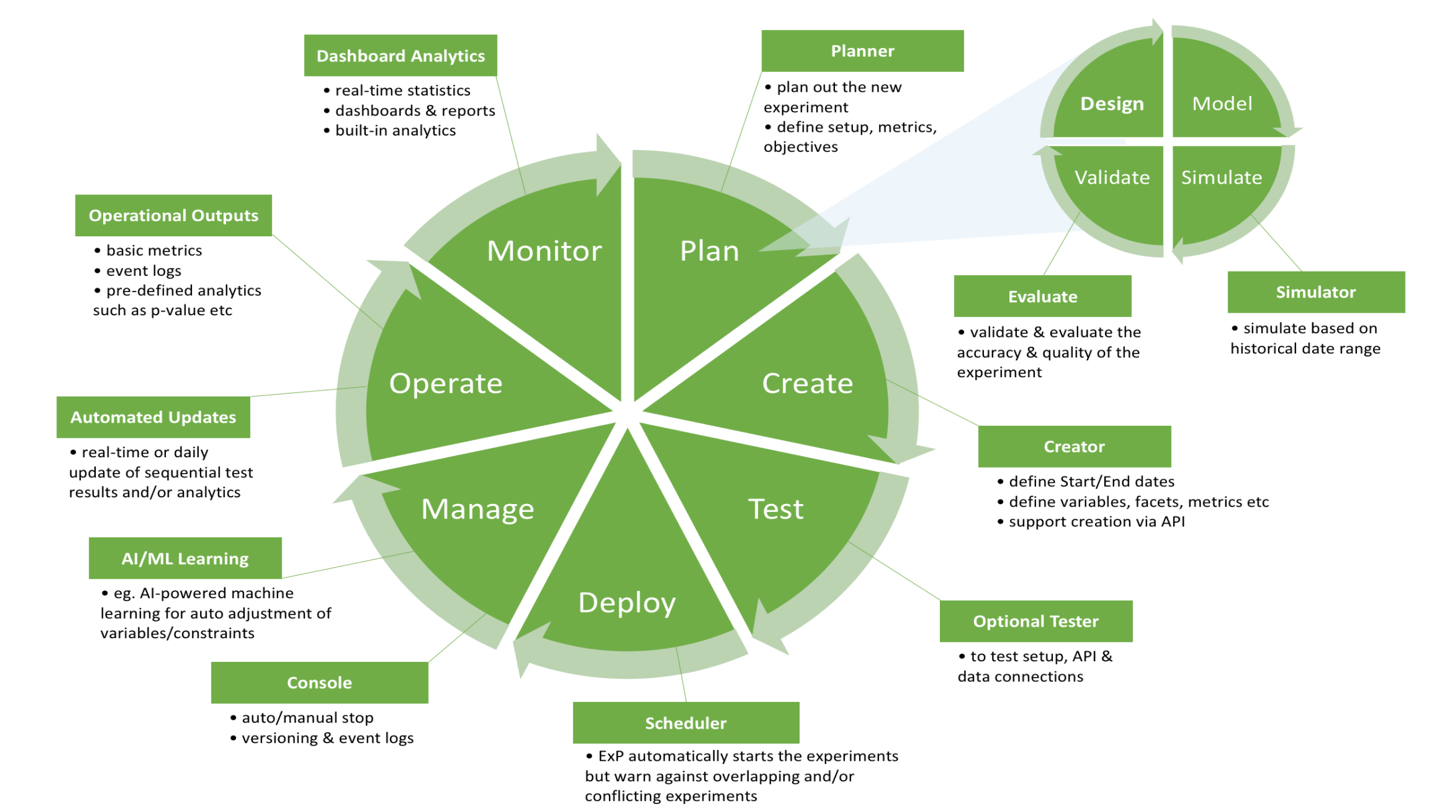
Building Grab’s Experimentation Platform

Introducing Grab-Kit: Distributed Service Design at Grab

How Grab Experimented with Chat to Drive Down Booking Cancellations

Deep Dive into Database Timeouts in Rails

Dealing with the Meltdown Patch at Grab

GrabShare at the Intelligent Transportation Engineering Conference
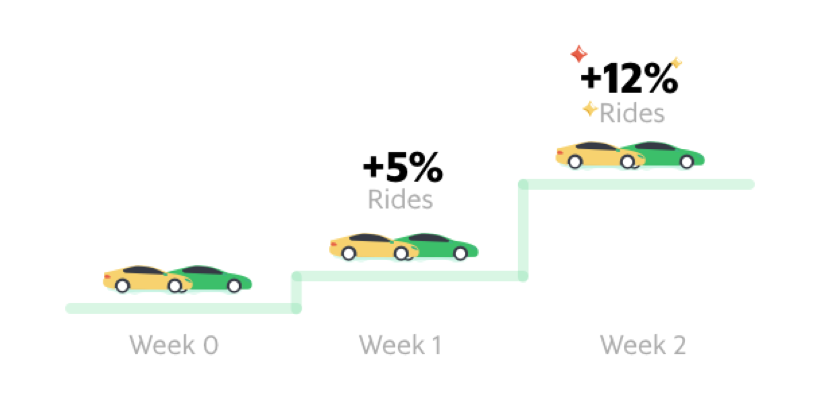
Grabbing Growth: A Growth Hacking Story
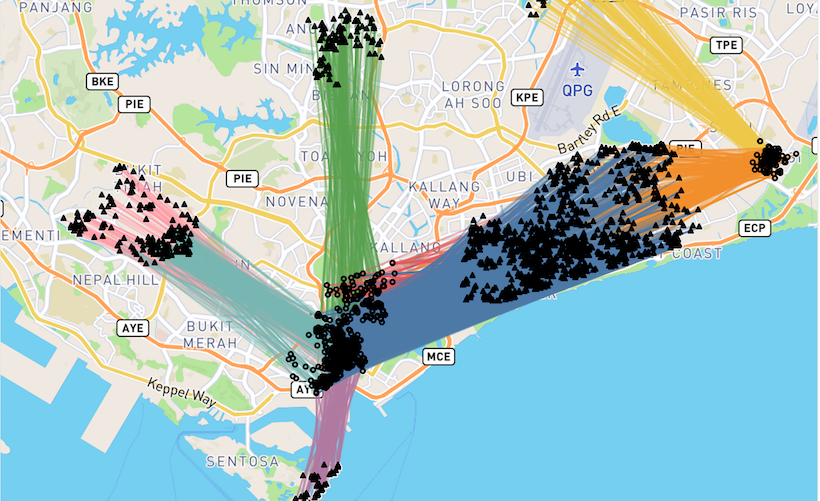
The Data and Science Behind GrabShare Part I: Verifying Potential and Developing the Algorithm

The Art of Hiring Good Engineers

Migrating Existing Datastores

So You Need to Hire Good Engineers

Come and #hackallthethings at Grab
How We Scaled Our Cache and Got a Good Night's Sleep

Grab's Front End Study Guide
DNS Resolution in Go and Cgo

Driving Southeast Asia Forward with AWS
How to Go from a Quick Idea to an Essential Feature in Four Steps
Troubleshooting Unusual AWS ELB 5XX Error
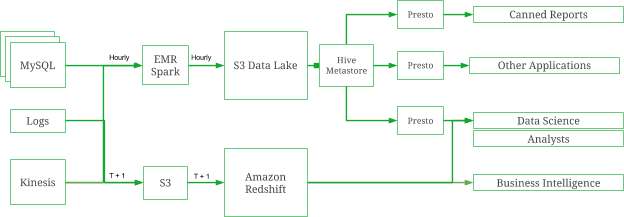
Scaling Like a Boss with Presto
Deep Dive into iOS Automation at Grab - Continuous Delivery
Deep Dive into iOS Automation at Grab - Integration Testing
A Key Expired in Redis, You Won't Believe What Happened Next

How Grab Hires Engineers in Singapore

Battling with Tech Giants for the World's Best Talent
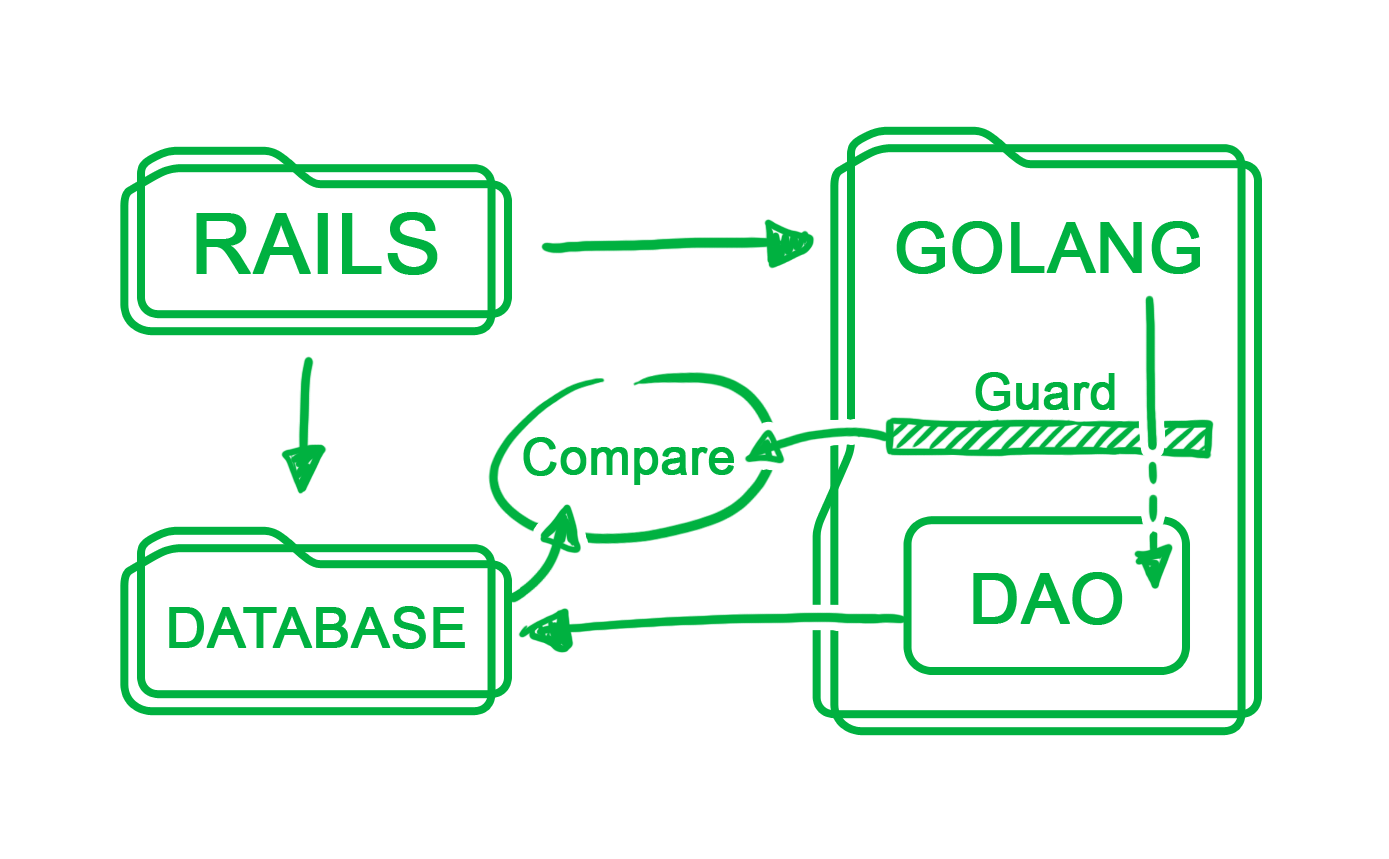
This Rocket Ain't Stopping - Achieving Zero Downtime for Rails to Golang API Migration

Grab Vietnam Careers Week
GrabPay Wins Best Fraud Prevention Innovation at the Florin Awards
Round-robin in Distributed Systems
Why Test the Design with Only 5 Users
Programmers Beware - UX is Not Just for Designers
Grab You Some Post-Mortem Reports
The Curious Case of the Phantom Instance
No articles match this topic.