
Catwalk: Serving Machine Learning Models at Scale
Introduction
Grab’s unwavering ambition is to be the best superapp in Southeast Asia that adds value to the every day for our consumers. In order to achieve that, the consumer experience must be flawless for each and every Grab service. Let’s take our frequently used ride-hailing service as an example. We want fair pricing for both drivers and passengers, accurate estimation of ETAs, effective detection of fraudulent activities, and ensured ride safety for our consumers. The key to perfecting these consumer journeys is artificial intelligence (AI).
Grab has a tremendous amount of data that we can leverage to solve complex problems such as fraudulent user activity, and to provide our consumers personalised experiences on our products. One of the tools we are using to make sense of this data is machine learning (ML).
As Grab made giant strides towards increasingly using machine learning across the organization, more and more teams were organically building model serving solutions for their own use cases. Unfortunately, these model serving solutions required data scientists to understand the infrastructure underlying them. Moreover, there was a lot of overlap in the effort it took to build these model serving solutions.
That’s why we came up with Catwalk: an easy-to-use, self-serve, machine learning model serving platform for everyone at Grab.
Goals
To determine what we wanted Catwalk to do, we first looked at the typical workflow of our target audience - data scientists at Grab:
- Build a trained model to solve a problem.
- Deploy the model to their project’s particular serving solution. If this involves writing to a database, then the data scientists need to programmatically obtain the outputs, and write them to the database. If this involves running the model on a server, the data scientists require a deep understanding of how the server scales and works internally to ensure that the model behaves as expected.
- Use the deployed model to serve users, and obtain feedback such as user interaction data. Retrain the model using this data to make it more accurate.
- Deploy the retrained model as a new version.
- Use monitoring and logging to check the performance of the new version. If the new version is misbehaving, revert back to the old version so that production traffic is not affected. Otherwise run an AB test between the new version and the previous one.
We discovered an obvious pain point - the process of deploying models requires additional effort and attention, which results in data scientists being distracted from their problem at hand. Apart from that, having many data scientists build and maintain their own serving solutions meant there was a lot of duplicated effort. With Grab increasingly adopting machine learning, this was a state of affairs that could not be allowed to continue.
To address the problems, we came up with Catwalk with goals to:
- Abstract away the complexities and expose a minimal interface for data scientists
- Prevent duplication of effort by creating an ML model serving platform for everyone in Grab
- Create a highly performant, highly available, model versioning supported ML model serving platform and integrate it with existing monitoring systems at Grab
- Shorten time to market by making model deployment self-service
What is Catwalk?
In a nutshell, Catwalk is a platform where we run Tensorflow Serving containers on a Kubernetes cluster integrated with the observability stack used at Grab.
In the next sections, we are going to explain the two main components in Catwalk - Tensorflow Serving and Kubernetes, and how they help us obtain our outlined goals.
What is Tensorflow Serving?
Tensorflow Serving is an open-source ML model serving project by Google. In Google’s own words, “Tensorflow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments. It makes it easy to deploy new algorithms and experiments, while keeping the same server architecture and APIs. Tensorflow Serving provides out-of-the-box integration with Tensorflow models, but can be easily extended to serve other types of models and data.”
Why Tensorflow Serving?
There are a number of ML model serving platforms in the market right now. We chose Tensorflow Serving because of these three reasons, ordered by priority:
- Highly performant. It has proven performance handling tens of millions of inferences per second at Google according to their website.
- Highly available. It has a model versioning system to make sure there is always a healthy version being served while loading a new version into its memory
- Actively maintained by the developer community and backed by Google
Even though, by default, Tensorflow Serving only supports models built with Tensorflow, this is not a constraint though, because Grab is actively moving toward using Tensorflow.
How are we using Tensorflow Serving?
In this section, we will explain how we are using Tensorflow Serving and how it helps abstract away complexities for data scientists.
Here are the steps showing how we are using Tensorflow Serving to serve a trained model:
- Data scientists export the model using tf.saved_model API and drop it to an S3 models bucket. The exported model is a folder containing model files that can be loaded to Tensorflow Serving.
- Data scientists are granted permission to manage their folder.
- We run Tensorflow Serving and point it to load the model files directly from the S3 models bucket. Tensorflow Serving supports loading models directly from S3 out of the box. The model is served!
- Data scientists come up with a retrained model. They export and upload it to their model folder.
- As Tensorflow Serving keeps watching the S3 models bucket for new models, it automatically loads the retrained model and serves. Depending on the model configuration, it can either gracefully replace the running model version with a newer version or serve multiple versions at the same time.
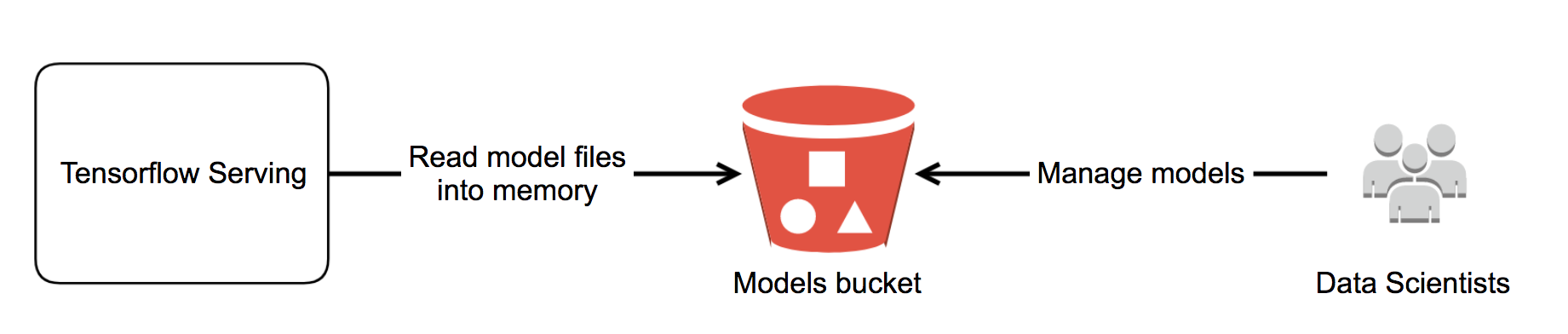
The only interface to data scientists is a path to their model folder in the S3 models bucket. To update their model, they upload exported models to their folder and the models will automatically be served. The complexities are gone. We’ve achieved one of the goals!
Well, not really…
Imagine you are going to run Tensorflow Serving to serve one model in a cloud provider, which means you need a compute resource from a cloud provider to run it. Running it on one box doesn’t provide high availability, so you need another box running the same model. Auto scaling is also needed in order to scale out based on the traffic. On top of these many boxes lies a load balancer. The load balancer evenly spreads incoming traffic to all the boxes, thus ensuring that there is a single point of entry for any clients, which can be abstracted away from the horizontal scaling. The load balancer also exposes an HTTP endpoint to external users. As a result, we form a Tensorflow Serving cluster that is ready to serve.
Next, imagine you have more models to deploy. You have three options
- Load the models into the existing cluster - having one cluster serve all models.
- Spin up a new cluster to serve each model - having multiple clusters, one cluster serves one model.
- Combination of 1 and 2 - having multiple clusters, one cluster serves a few models.
The first option would not scale, because it’s just not possible to load all models into one cluster as the cluster has limited resources.
The second option will definitely work but it doesn’t sound like an effective process, as you need to create a set of resources every time you have a new model to deploy. Additionally, how do you optimise the usage of resources, e.g., there might be unutilised resources in your clusters that could potentially be shared by the rest.
The third option looks promising, you can manually choose the cluster to deploy each of your new models into so that all the clusters’ resource utilisation is optimal. The problem is you have to manually manage it. Managing 100 models using 25 clusters can be a challenging task. Furthermore, running multiple models in a cluster can also cause a problem as different models usually have different resource utilisation patterns and can interfere with each other. For example, one model might use up all the CPU and the other model won’t be able to serve anymore.
Wouldn’t it be better if we had a system that automatically orchestrates model deployments based on resource utilisation patterns and prevents them from interfering with each other? Fortunately, that is exactly what Kubernetes is meant to do!
So What is Kubernetes?
Kubernetes abstracts a cluster of physical/virtual hosts (such as EC2) into a cluster of logical hosts (pods in Kubernetes terms). It provides a container-centric management environment. It orchestrates computing, networking, and storage infrastructure on behalf of user workloads.
Let’s look at some of the definitions of Kubernetes resources:
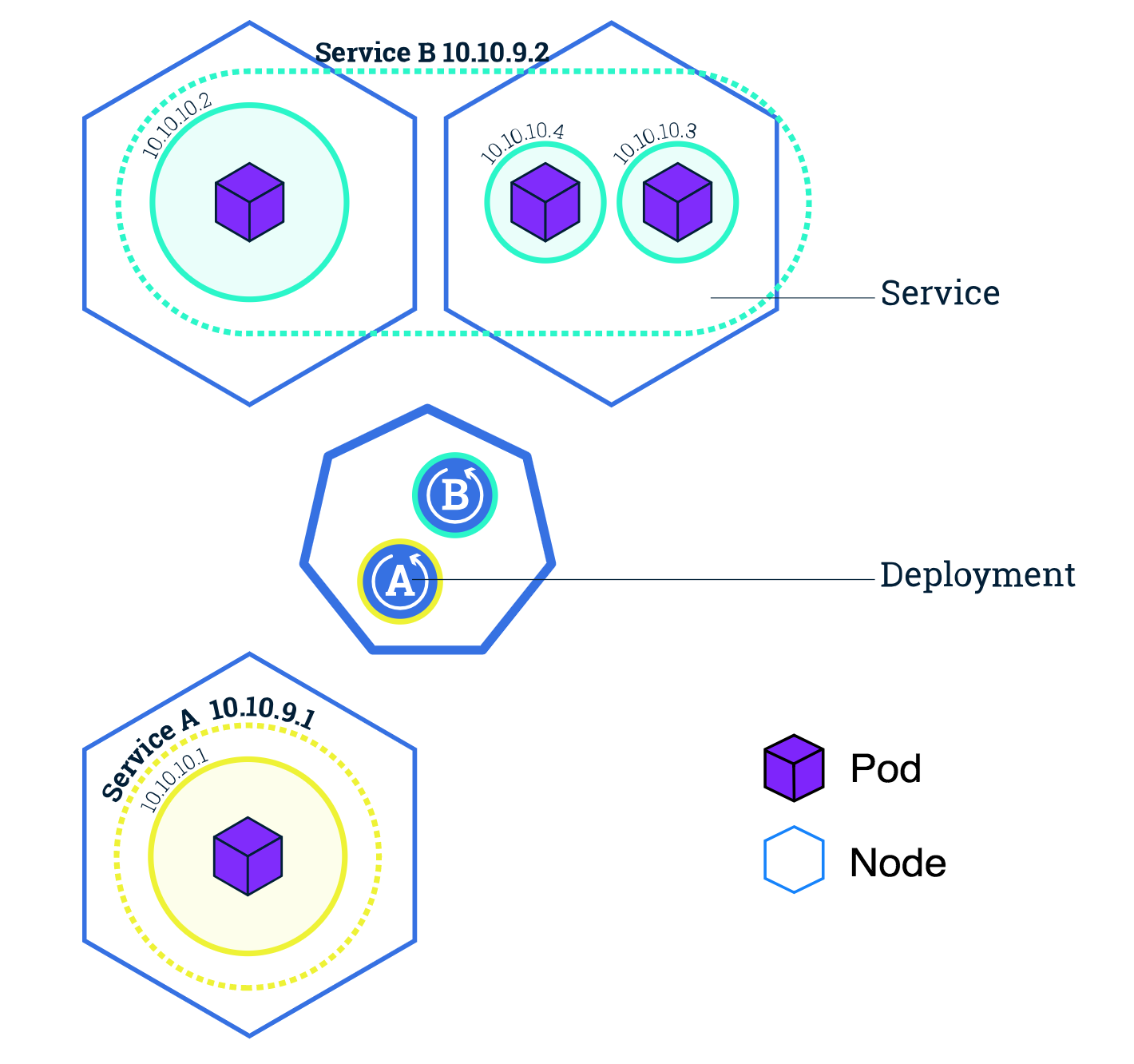
- Cluster - a cluster of nodes running Kubernetes.
- Node - a node inside a cluster.
- Deployment - a configuration to instruct Kubernetes the desired state of an application. It also takes care of rolling out an update (canary, percentage rollout, etc), rolling back and horizontal scaling.
- Pod - a single processing unit. In our case, Tensorflow Serving will be running as a container in a pod. Pod can have CPU/memory limits defined.
- Service - an abstraction layer that abstracts out a group of pods and exposes the application to clients.
- Ingress - a collection of routing rules that govern how external users access services running in a cluster.
- Ingress Controller - a controller responsible for reading the ingress information and processing that data accordingly such as creating a cloud-provider load balancer or spinning up a new pod as a load balancer using the rules defined in the ingress resource.
Essentially, we deploy resources to instruct Kubernetes the desired state of our application and Kubernetes will make sure that it is always the case.
How are we using Kubernetes?
In this section, we will walk you through how we deploy Tensorflow Serving in Kubernetes cluster and how it makes managing model deployments very convenient.
We used a managed Kubernetes service, to create a Kubernetes cluster and manually provisioned compute resources as nodes. As a result, we have a Kubernetes cluster with nodes that are ready to run applications.
An application to serve one model consists of:
- Two or more Tensorflow Serving pods that serves a model with an autoscaler to scale pods based on resource consumption
- A load balancer to evenly spread incoming traffic to pods
- An exposed HTTP endpoint to external users
In order to deploy the application, we need to:
- Deploy a deployment resource specifying
- Number of pods of Tensorflow Serving
- An S3 url for Tensorflow Serving to load model files
- Deploy a service resource to expose it
- Deploy an ingress resource to define an HTTP endpoint url
Kubernetes then allocates Tensorflow Serving pods to the cluster with the number of pods according to the value defined in deployment resource. Pods can be allocated to any node inside the cluster, Kubernetes makes sure that the node it allocates a pod into has sufficient resources that the pod needs. In case there is no node that has sufficient resources, we can easily scale out the cluster by adding new nodes into it.
In order for the rules defined inthe ingressresource to work, the cluster must have an ingress controller running, which is what guided our choice of the load balancer. What an ingress controller does is simple: it keeps checking the ingress resource, creates a load balancer and defines rules based on rules in the ingress resource. Once the load balancer is configured, it will be able to redirect incoming requests to the Tensorflow Serving pods.
That’s it! We have a scalable Tensorflow Serving application that serves a model through a load balancer! In order to serve another model, all we need to do is to deploy the same set of resources but with the model’s S3 url and HTTP endpoint.
To illustrate what is running inside the cluster, let’s see how it looks like when we deploy two applications: one for serving pricing model another one for serving fraud-check model. Each application is configured to have two Tensorflow Serving pods and exposed at /v1/models/model
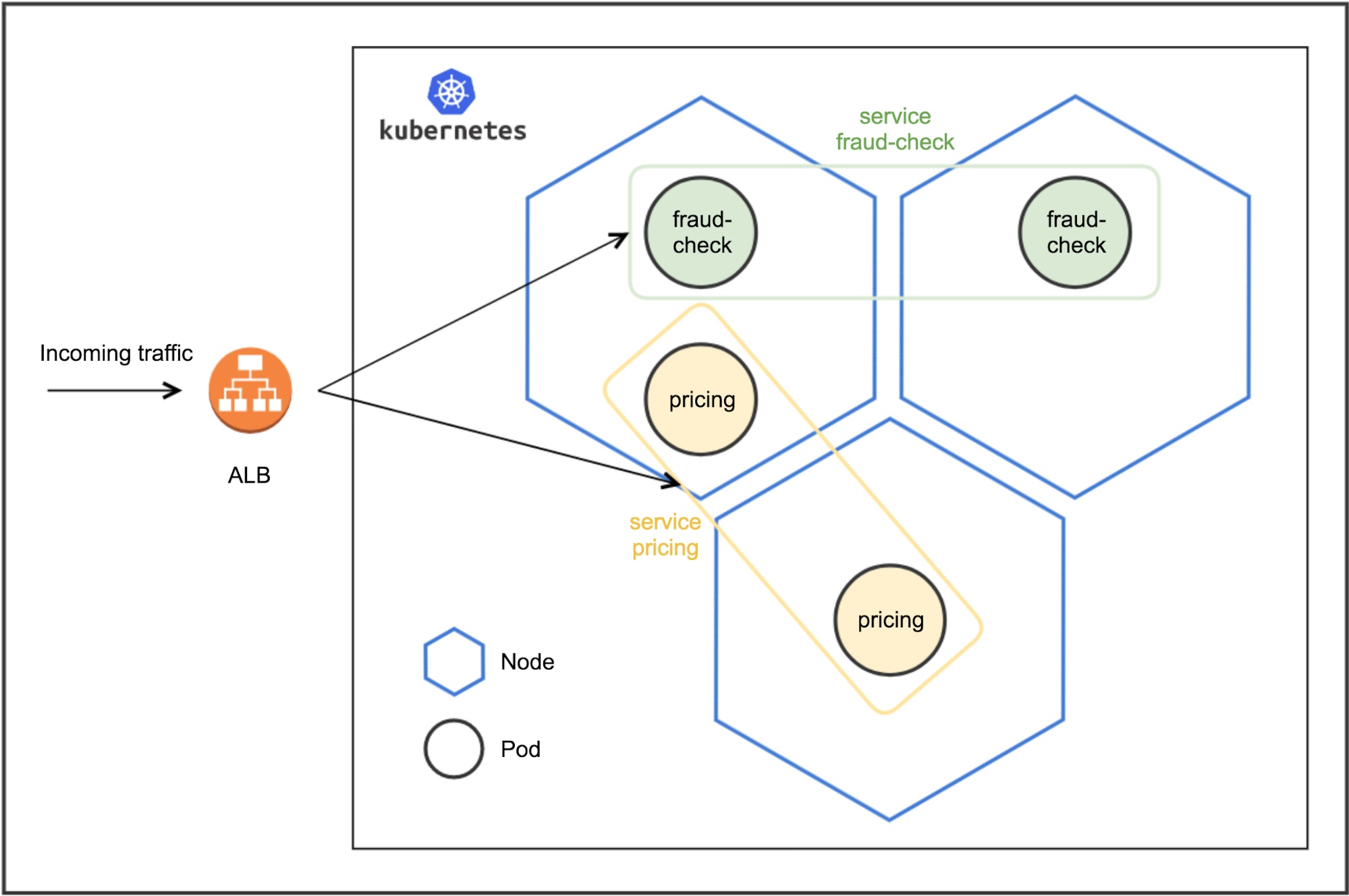
There are two Tensorflow Serving pods that serve fraud-check model and exposed through a load balancer. Same for the pricing model, the only differences are the model it is serving and the exposed HTTP endpoint url. The load balancer rules for pricing and fraud-check model look like this
| If | Then forward to |
|---|---|
| Path is /v1/models/pricing | pricing pod ip-1 |
| pricing pod ip-2 | |
| Path is /v1/models/fraud-check | fraud-check pod ip-1 |
| fraud-check pod ip-2 |
Stats and Logs
The last piece is how stats and logs work. Before getting to that, we need to introduce DaemonSet. According to the document, DaemonSet ensures that all (or some) nodes run a copy of a pod. As nodes are added to the cluster, pods are added to them. As nodes are removed from the cluster, those pods are garbage collected. Deleting a DaemonSet will clean up the pods it created.
We deployed datadog-agent and filebeat as a DaemonSet. As a result, we always have one datadog-agent pod and one filebeat pod in all nodes and they are accessible from Tensorflow Serving pods in the same node. Tensorflow Serving pods emit a stats event for every request to datadog-agent pod in the node it is running in.
Here is a sample of DataDog stats:
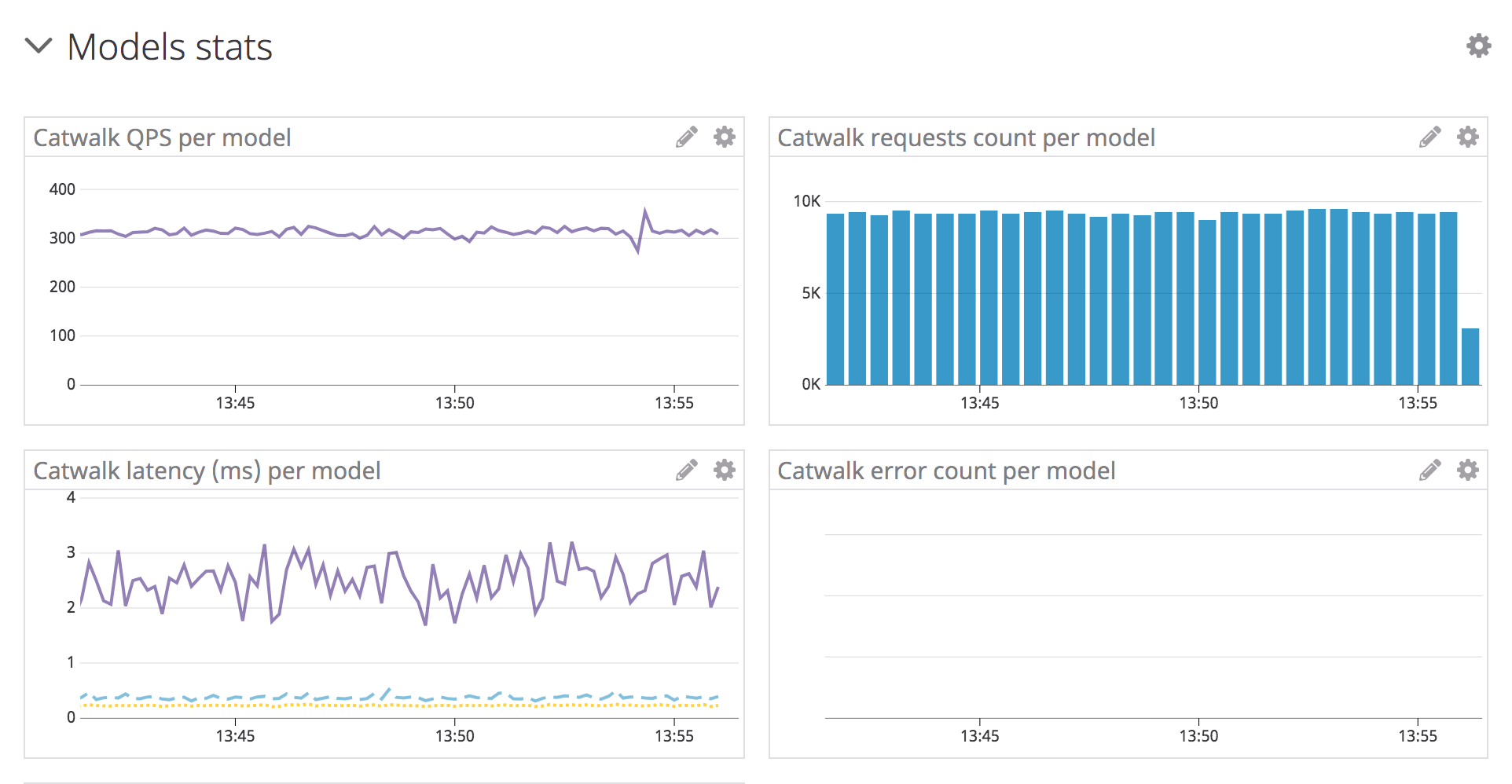
And logs that we put in place:
Benefits Gained from Catwalk
Catwalk has become the go-to, centralised system to serve machine learning models. Data scientists are not required to take care of the serving infrastructure hence they can focus on what matters the most: come up with models to solve consumer problems. They are only required to provide exported model files and estimation of expected traffic in order to prepare sufficient resources to run their model. In return, they are presented with an endpoint to make inference calls to their model, along with all necessary tools for monitoring and debugging. Updating the model version is self-service, and the model improvement cycle is much shorter than before. We used to count in days, we now count in minutes.
Future Plans
Improvement on Automation
Currently, the first deployment of any model will still need some manual task from the platform team. We aim to automate this process entirely. We’ll work with our awesome CI/CD team who is making the best use of Spinnaker.
Model Serving on Mobile Devices
As a platform, we are looking at setting standards for model serving across Grab. This includes model serving on mobile devices as well. Tensorflow Serving also provides a Lite version to be used on mobile devices. It is a whole new paradigm with vastly different tradeoffs for machine learning practitioners. We are quite excited to set some best practices in this area.
gRPC Support
Catwalk currently supports HTTP/1.1. We’ll hook Grab’s service discovery mechanism to open gRPC traffic, which TFS already supports.
If you are interested in building pipelines for machine learning related topics, and you share our vision of driving Southeast Asia forward, come join us!