-
 Engineering
EngineeringCrowdsourced taxonomy verification: A feedback-driven framework for refining knowledge graph relationships via online search interactions
Knowledge graphs power modern search and recommendation systems, but automated construction methods can introduce semantic inaccuracies. This framework verifies KG relationships in real time by injecting candidate edges into live search results and using user feedback to validate semantic truth. -
 Engineering · Design
Engineering · DesignAgent platform (Part 1): How we help Grab build and run AI agents at scale
Explains how Grab turned repeated operational pain points into reusable platform primitives that help teams build, test, and run agents faster and more safely. It shows why the hard part of agent development isn't the reasoning loop itself, but everything around it from auth, secrets, environment config, observability, evals, MCP integration, and service-to-service connectivity. -
 Engineering
EngineeringScaling Grab's Data Lake: Our journey to Apache Iceberg adoption
As Grab's Data Lake grew to petabytes, the limitations of Hive Parquet became clear, from catalog latency and small files to manual partition management. This blog shares our journey adopting Apache Iceberg as our default table format: why we chose it, how we rolled it out at scale, the tooling we built along the way, and the lessons we learned. -
 Engineering
EngineeringMigrating Counter Service storage: Design choices and learnings
Counter Service powers real-time fraud detection at massive scale, handling billions of requests daily. Learn how we migrated its underlying storage with zero downtime, redesigning the writer data model, incorporating clean data access layer separation on the reader side, building dual read-write path for traffic shadowing and data parity validation, and rolling out traffic gradually while verifying data integrity at every step -
 Engineering
EngineeringScaling out Distroless adoption With AI
Grab is moving hundreds of services to Distroless images to cut CVEs but only if workloads still run cleanly. Learn how medium tests became the migration gate, where the scaffolding toil stalled the campaign, and how an agentic workflow (skills, MCP, guardrails) generated tests and Docker changes at fleet scale; with humans still approving every MR. -
 Engineering
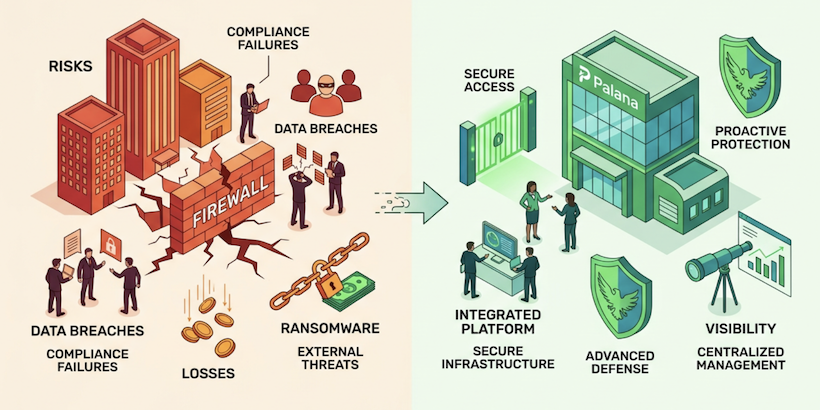
EngineeringPalana (Part 2): Architecting isolation, identity, and auditability for AI agents
How do you actually build a secure execution environment for artificial intelligence (AI) agents? In Part 2, we dive deep into Palana's architecture. Learn how Grab handles proxy-mediated secrets, large language model (LLM) routing, and strict network access under the hood. We also share our operational learnings on managing agent lifecycles, enforcing strict boundaries, and making useful AI autonomy safe and boring to operate. -
 Engineering
EngineeringPalana (Part 1): Why Grab built a secure platform for autonomous AI Agents
Artificial intelligence (AI) agents are evolving from chat interfaces into autonomous workloads, bringing new security risks. In Part 1, discover why Grab built Palana, a Kubernetes-native platform designed to run AI agents safely. We explore the core design principles behind treating isolation as the unit of trust and how Palana enables secure, self-service developer environments without compromising control. -
 Engineering
EngineeringFrom decentralized Docs-as-Code to a centralized repository: Evolving Grab's documentation strategy
Building on Grab's Docs-as-Code approach, we reflect on our documentation journey, uncovering the benefits, challenges, and limitations along the way. Learn why we made the shift, what we gained in search and quality assurance, and when each approach works best. -
 Engineering · Data
Engineering · DataThe Hugo evolution: Engineering Grab's unified, one-click data ingestion platform with Apache Flink
At Grab, we're transforming data ingestion and processing with Hugo, our self-service data platform. Now integrated with Apache Flink, Hugo empowers teams to build real-time data pipelines effortlessly. Discover how we've streamlined complex processes into a single, one-click experience that boosts productivity and enables rapid insights. Dive into our blog to explore this game-changing evolution! -
 Engineering · Android
Engineering · AndroidScaling developer experience: How we improved Android Studio in a large monorepo
Frustrated by 35-minute integrated development environment (IDE) syncs? In a large monorepo, slow builds were eroding productivity. Discover how we built a custom Focus plugin to slash sync times to under 2 minutes and drop memory usage from 10 GB to 2 GB. Learn how we leveraged Gradle and Bazel to reclaim developer flow without changing a single team's workflow. -
 Engineering · Data
Engineering · DataEnhancing Flink deployment with shadow testing
Discover how Grab's data streaming team has revolutionized Apache Flink deployments with Shadow Testing, ensuring seamless reliability for real-time applications. By deploying new versions alongside existing ones without disruption, we eliminate downtime and enhance application availability. Dive into our article to explore this innovative approach and how it boosts deployment confidence and efficiency. -
 Engineering
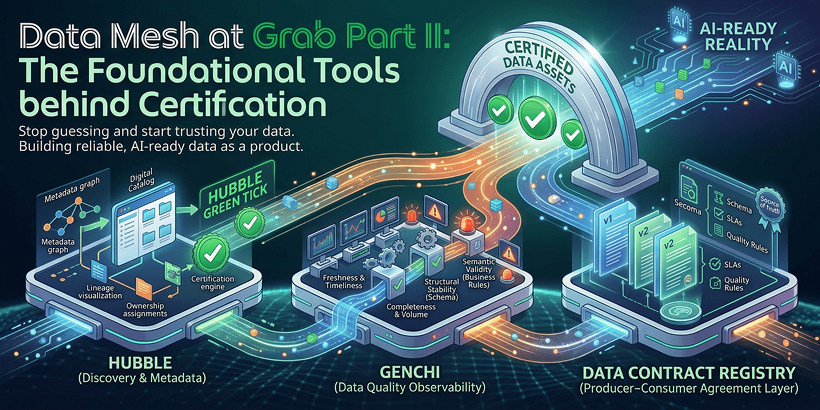
EngineeringData Mesh at Grab (Part II): The foundational tools behind certification
How does Grab manage quality across hundreds of thousands of data assets? Discover the foundational tools powering our Signals Marketplace. We dive into Hubble for discovery, Genchi for observability, and our Data Contract Registry to see how event-driven certification turns 'data as a product' into a reliable, AI-ready reality. Stop guessing and start trusting your data. -
 Engineering
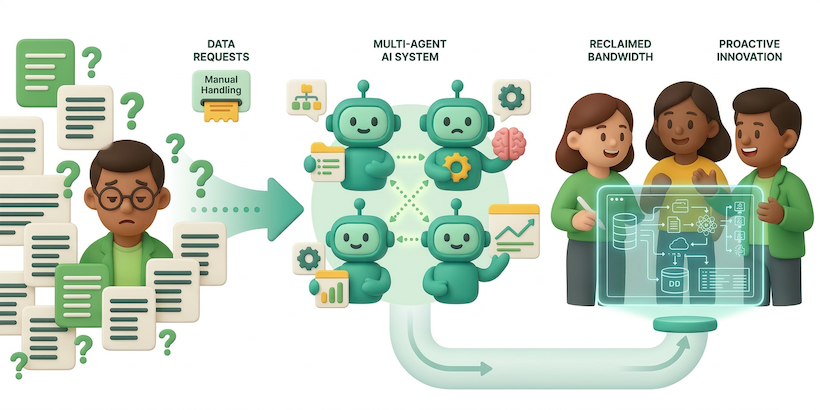
EngineeringFrom firefighting to building: How AI agents restored our team’s core productivity
The Analytics Data Warehouse (ADW) team at Grab supports over 1,000 users. These users support an extensive repository of more than 15,000 tables. To alleviate the time-consuming demands of repetitive tasks, the team implemented a multi-agent AI system. This system autonomously handles simpler inquiries and collaborates on more complex requests, reclaiming significant engineering bandwidth and unlocking hundreds of hours of productivity each month. -
 Engineering
EngineeringEnabling R8 optimization at scale with AI-assisted debugging
How Grab enabled R8 optimization for its Android app at scale, over 9 million lines of code and more than engineers. Read how we achieved 25% ANR reduction, 16% app size decrease, and 27% faster startup through AI-assisted debugging with MCP tools, pragmatic testing strategies, and optimized feedback loops -
 Engineering
EngineeringReclaiming Terabytes: Optimizing Android image caching with TLRU
In the quest to optimize app performance, managing the image cache was crucial. This blog takes us on a journey from a traditional Least Recently Used (LRU) cache to a Time-Aware Least Recently Used (TLRU) cache. This innovative approach reclaimed terabytes of storage across millions of devices while maintaining user experience and controlling server costs. Discover how Grab's TLRU implementation cleverly balances storage optimization and performance, offering a glimpse into the future of app development. -
 Engineering
EngineeringCursor at Grab: Adoption and impact
A look inside how we scaled AI-assisted coding across Grab, moving Cursor from pilot to daily use to help us work faster and more reliably. Read what changed in our workflows with Cursor, how we integrated it responsibly, and what’s next for Cursor within Grab's ecosystem. -
 Engineering
EngineeringDocker lazy loading at Grab: Accelerating container startup times
Large container images were causing slow cold starts and poor auto-scaling for Grab's data platforms. This post explores how we implemented Docker image lazy loading with Seekable OCI (SOCI) technology, to achieve faster image pulls and startup times. The blog discusses how lazy loading works, the technology behind SOCI and eStargz, and finally how this configuration delivered a 60% improvement in download times. -
 Engineering
EngineeringFrom deployment slop to production reality: How BriX bridges the gap with enterprise-grade AI infrastructure
Built an AI tool that works locally but can't scale enterprise-wide? Learn how BriX tackles this deployment gap, turning prototypes into governed, production-grade solutions—no engineering team required. -
 Engineering · Design · Product
Engineering · Design · ProductDemystifying user journeys: Revolutionizing troubleshooting with auto tracking
In the dynamic realm of mobile development, understanding user journeys is key to effective troubleshooting. This blog delves into how Grab's innovative AutoTrack SDK has revolutionized session tracking. By addressing the challenges of incomplete user journey data, Grab has significantly reduced downtime, boosted customer satisfaction, and enhanced developer efficiency. -
 Engineering
EngineeringHow Grab is accelerating growth with real-time personalization using Customer Data Platform scenarios
Grab’s Customer Data Platform (CDP) introduces Scenarios, enabling real-time personalization at scale. By leveraging event triggers, geo-fencing, historical data, and predictive models, Grab delivers dynamic user experiences like mall offers, traveler recommendations, and ad retargeting. Proven results include more than a 3% uplift in conversions, driving growth across Southeast Asia. -
 Engineering · Data
Engineering · DataA Decade of Defense: Celebrating Grab's 10th Year Bug Bounty Program
Discover how Grab has championed cybersecurity for a decade with its Bug Bounty Program. This article delves into the milestones, insights, and the collaborative efforts that have fortified Grab's defenses, ensuring a secure and reliable platform for millions. -
 Engineering · Data
Engineering · DataReal-time data quality monitoring: Kafka stream contracts with syntactic and semantic test
Discover how Grab's Coban Platform revolutionizes real-time data quality monitoring for Kafka streams. Learn how syntactic and semantic tests empower stream users to ensure reliable data, prevent cascading errors, and accelerate AI-driven innovation. -
 Engineering · Data
Engineering · DataSpellVault’s evolution: Beyond LLM apps, towards the agentic future
Discover SpellVault’s evolution from its early RAG-based foundations and plugin ecosystem to its transformation into a tool-driven, agentic framework that empowers users to build AI agents that are powerful, flexible, and future-ready. -
 Engineering
EngineeringGrab's Mac Cloud Exit supercharges macOS CI/CD
Discover how our transition from cloud-based Mac hardware infrastructure to a colocation cluster within Southeast Asia has revolutionized our macOS CI/CD, enhancing performance and reducing costs. -
 Engineering · Data
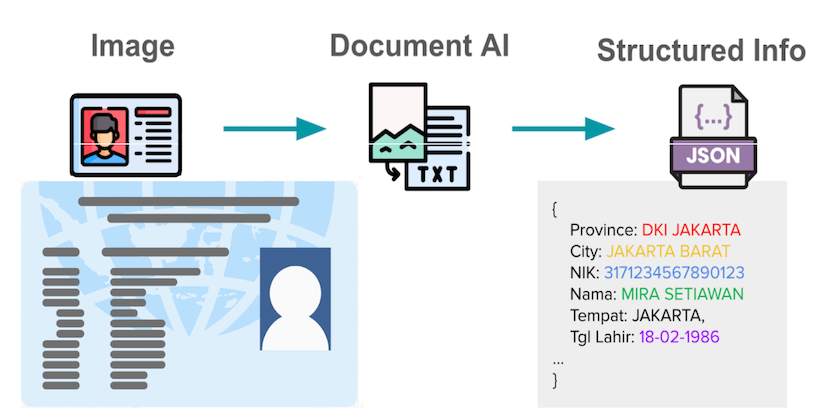
Engineering · DataHow we built a custom vision LLM to improve document processing at Grab
e-KYC faces challenges with unstandardized document formats and local SEA languages. Existing LLMs lack sufficient SEA language support. We trained a Vision LLM from scratch, modifying open-source models to be 50% faster while maintaining accuracy. These models now serve live production traffic across Grab's ecosystem for merchant, driver, and user onboarding. -
 Engineering · Data
Engineering · DataMachine-learning predictive autoscaling for Flink
Explore how Grab uses machine learning to perform predictive scaling on our data processing workloads. -
 Engineering · Data
Engineering · DataModernising Grab’s model serving platform with NVIDIA Triton Inference Server
Dive into Grab’s engineering journey to optimise a core ML model. Learn how we built the Triton Server Manager and used Triton Inference Server (TIS) to achieve a 50% reduction in tail latency and seamlessly migrate over 50% of online deployments. -
 Engineering
EngineeringHighly concurrent in-memory counter in GoLang
Dive into the chaos and triumph of real-time optimisation in the face of high database utilisation! This article recounts a developer's adrenaline-fueled journey of transforming crisis into innovation—optimising campaign usage count tracking through highly concurrent in-memory caching and periodic database updates. Embrace the madness, thrive in the challenge, and discover a bold approach to tackling database bottlenecks head-on! -
 Engineering
EngineeringUser foundation models for Grab
Grab has developed a groundbreaking foundation model specifically designed to understand user behavior. Grab's custom solution addresses the unique challenges of a multi-service platform spanning food delivery, ride-hailing, grocery shopping, financial services, and more. The blog delves into the architecture and technical achievements that this innovation is built on. -
 Engineering
EngineeringPowering Partner Gateway metrics with Apache Pinot
Partner Gateway serves as Grab's secure interface for exposing APIs to third-party entities, facilitating seamless interactions between Grab's hosted services and external consumers. This blog delves into the implementation of Apache Pinot within Partner Gateway for advanced metrics tracking. Discover the challenges, trade-offs, and solutions the team navigated to optimize performance and ensure reliability in this innovative integration. -
 Engineering
EngineeringTaming the monorepo beast: Our journey to a leaner, faster GitLab repo
At Grab, our decade-old Go monorepo had become a 214GB monster with 13 million commits, causing 4-minute replication delays and crippling developer productivity. Through custom migration tooling and strategic history pruning, we achieved a 99.9% reduction in commits while preserving all critical functionality. The result? 36% faster clones, eliminated single points of failure, and a 99.4% improvement in replication performance—transforming our biggest infrastructure bottleneck into a development enabler. -
 Engineering
EngineeringData mesh at Grab part I: Building trust through certification
Grab has embarked on a transformative journey to overhaul its enterprise data ecosystem, addressing challenges posed by the rapid growth of its business spanning across ride-hailing, food delivery, and financial services. With the increasing complexity of its data landscape, Grab transitioned from a centralised data warehouse model to a data mesh architecture, a decentralised approach treating data as a product owned by domain-specific teams. The article shares the motivations behind the change, the factors and steps taken to make it a success, and results. -
 Engineering
EngineeringThe evolution of Grab's machine learning feature store
Learn how Grab is modernising its machine learning platform with a feature table-centric architecture powered by AWS Aurora for Postgres. This shift from a legacy feature fetching system to decentralised deployments enhances performance and user experience, while solving challenges like atomic updates and noisy neighbor issues. -
 Engineering
EngineeringGrab's service mesh evolution: From Consul to Istio
When you're running 1000+ microservices across Southeast Asia's most complex transport and delivery platform, 'good enough' stops being good enough. Discover how Grab tackled the challenge of migrating from Consul to Istio across a hybrid infrastructure spanning AWS and GCP, separate AWS organizations, and diverse deployment models. This isn't your typical service mesh migration story. We share the real challenges of designing resilient architecture for massive scale, the unconventional decisions that paid off, and the lessons learned from coordinating migrations while keeping critical services like food delivery and ride-hailing running seamlessly. From evaluation criteria to architecture decisions, migration strategies to operational insights - get an inside look at how we're building the backbone of Grab's microservices future, one service at a time. -
 Engineering
EngineeringDispatchGym: Grab’s reinforcement learning research framework
DispatchGym is a research framework that supports reinforcement learning (RL) studies for dispatch systems. A system that matches bookings with drivers. Designed to be efficient, cost-effective, and accessible, this article outlines its principles, research benefits, and real-world applications. -
 Engineering
EngineeringCounter Service: How we rewrote it in Rust
The Integrity Data Platform team at Grab rewrote a QPS-heavy Golang microservice in Rust, achieving 70% infrastructure savings while maintaining similar performance. This initiative explored the ROI of adopting Rust for production services, balancing efficiency gains against challenges like Rust’s steep learning curve and the risks of rewriting legacy systems. The blog delves into the selection process, approach, pitfalls, and the ultimate business value of the rewrite. -
 Engineering
EngineeringThe complete stream processing journey on FlinkSQL
Introducing FlinkSQL interactive solution to enhance real-time stream processing exploration. The new system simplifies stream processing development, automates production workflows and democratises access to real-time insights. Read on about our journey that begun at addressing challenges encountered with the previous Zeppelin notebook-based solution to the current state of integration with and productionisation of FlinkSQL. -
 Engineering
EngineeringEffortless enterprise authentication at Grab: Dex in action
This article outlines Grab's journey towards enabling a seamless single sign-on experience for its numerous internal applications. It addresses the challenges of fragmented authentication and authorisation systems and introduces Dex, an open-source federated OpenID Connect provider, as the chosen solution. The document details the implementation of Dex, its key features, and discusses future plans for an unified authorisation model. -
 Engineering
EngineeringFrom failure to success: The birth of GrabGPT, Grab’s internal ChatGPT
When Grab's Machine Learning team sought to automate support queries, a failed chatbot experiment sparked an unexpected pivot: GrabGPT. Born from the need to harness Large Language Models (LLMs) internally, this tool became a go-to resource for employees. Offering private, auditable access to models like GPT and Gemini, the author shares his journey of turning failed experiments into strategic wins. -
 Engineering · Data Analytics · Data Science
Engineering · Data Analytics · Data ScienceStreamlining RiskOps with the SOP agent framework
Discover how the SOP-driven Large Language Model (LLM) agent framework is revolutionising Risk Operations (RiskOps) by automating Account Takeover (ATO) investigations. Explore the potential of this transformative tool to unlock unprecedented levels of productivity and innovation across industries. -
 Engineering · Data Analytics · Data Science
Engineering · Data Analytics · Data ScienceIntroducing the SOP-driven LLM agent frameworks
The SOP-driven Large Language Model (LLM) agent framework, revolutionises enterprise AI by integrating Standard Operating Procedures (SOPs) to ensure reliable execution and boost productivity. Achieving over 99.8% accuracy, it offers versatile automation tools and app development, making AI solutions 10 times faster. The framework addresses LLM challenges by structuring SOPs as a tree, enabling intuitive workflow creation. The framework aims to transform enterprise operations and explore industry applications. -
 Engineering
EngineeringEvaluating performance impact of removing Redis-cache from a Scylla-backed service
At Grab, we recently reevaluated a setup that combined Scylla with an external Redis cache. We decided to remove Redis and adjusted our Scylla configurations and strategies accordingly. This change helped reduce latency spikes while significantly lowering the overall cost. In this article, we explore the process, the challenges we faced, and the solutions we implemented to create a more efficient and cost-effective setup. -
 Engineering
EngineeringFacilitating Docs-as-Code implementation for users unfamiliar with Markdown
In this article, we'll discuss how we've streamlined the Docs-as-Code process for technical contributors, specifically engineers, who are already familiar with GitLab but might face challenges with Markdown. Discover how we plan to improve the workflow for non-engineering teams contributing to service and standalone documentation. -
 Engineering · Data Analytics
Engineering · Data AnalyticsImproving Hugo stability and addressing oncall challenges through automation
Managing 4,000+ data pipelines demanded a smarter approach to stability. We built a comprehensive automation solution that enhances Hugo's monitoring capabilities, streamlines issue diagnosis, and significantly reduces on-call workload. Explore our architecture, implementation, and the impact of automated healing features. -
 Engineering · Data Analytics
Engineering · Data AnalyticsBuilding a Spark observability product with StarRocks: Real-time and historical performance analysis
Discover how Grab revolutionised its Spark observability with StarRocks! We transformed our monitoring capabilities by moving from a fragmented system to a unified, high-performance platform. Learn about our journey from the initial Iris tool to a robust solution that tackles limitations with real-time and historical data analysis, all powered by StarRocks. Explore the architecture, data model, and advanced analytics that enable us to provide deeper insights and recommendations for optimising Spark jobs at Grab. -
 Engineering
EngineeringTechDocs at Grab: Cultivating a culture of quality documentation
Discover the steps taken in building a strong documentation culture that produces high-quality content, while making the tools easy to use for everyone involved in Grab. -
 Engineering · Data Science
Engineering · Data ScienceGrab AI Gateway: Connecting Grabbers to multiple GenAI providers
GenAI has become integral to innovation, powering the next generation of AI enabled applications. With easy integration with multiple AI providers, it brings cutting edge technology to every user. This article explores why we need GenAI Gateway, how it works, what are the user benefits, and the challenges faced in GenAI in this article. -
 Engineering · Security
Engineering · SecurityEmbracing passwordless authentication with Grab’s Passkey
Find out how Passkey makes logging in easier and safer by introducing passwordless authentication. Learn how this new feature works, the benefits it brings, and why it's a game-changer for your security and convenience. Dive in to see how Grab is making your app experience smoother and more secure. -
 Engineering · Product
Engineering · ProductTurbocharging GrabUnlimited with Temporal
Discover how Grab tackled the challenges of scaling its flagship membership program, GrabUnlimited. In this deep dive, we explore the migration from a legacy system to Temporal, reducing production incidents by 80%, improving scalability, and transforming the architecture for millions of users. -
 Engineering · Data Science
Engineering · Data ScienceHow we seamlessly migrated high volume real-time streaming traffic from one service to another with zero data loss and duplication
In the world of high-volume data processing, migrating services without disruption is a formidable challenge. At Grab, we recently undertook this task by splitting one of our backend service's stream read and write functionalities into two separate services. Discover how we conducted this transition with zero data loss and duplication using a simple switchover strategy, along with rigorous validation mechanisms. -
 Engineering · Data Science
Engineering · Data ScienceSupercharging LLM application development with LLM-Kit
Discover how Grab's LLM-Kit enhances AI app development by addressing scalability, security, and integration challenges. This article discusses the challenges faced in LLM app building, the solution, the architecture of the LLM-Kit as well as the future plans of the LLM-Kit. -
 Engineering
EngineeringHow we reduced initialisation time of Product Configuration Management SDK
Discover how we revolutionised our product configuration management SDK, reducing initialisation time by up to 90%. Learn about the challenges we faced with cold starts and the phased approach we took to optimise the SDK's performance. -
 Engineering · Data Science
Engineering · Data ScienceMetasense V2: Enhancing, improving and productionisation of LLM powered data governance
In the initial article, we explored the integration of Large Language Models (LLM) to automate metadata generation, addressing challenges like limited customisation and resource constraints. This integration enabled efficient column-level tag classifications and data sensitivity tiering. With the model initially scanning over 20,000 entries, we identified areas for improvement post-rollout. These advancements have significantly reduced manual workloads, increased accuracy, and bolstered trust in our data governance processes. -
 Engineering
EngineeringHow we reduced peak memory and CPU usage of the product configuration management SDK
Learn about GrabX, Grab’s central platform for product configuration management. This article discusses the steps taken to optimise the SDK, aiming to improve resource utilisation, reduce costs, and accelerate internal adoption. -
 Engineering · Data Science
Engineering · Data ScienceLLM-assisted vector similarity search
Vector similarity search has revolutionised data retrieval, particularly in the context of Retrieval-Augmented Generation in conjunction with advanced Large Language Models (LLMs). However, it sometimes falls short when dealing with complex or nuanced queries. In this post, we explore our experimentation with a simple yet effective approach to mitigate this shortcoming by combining the efficiency of vector similarity search with the contextual understanding of LLMs. -
 Engineering · Analytics · Data Science
Engineering · Analytics · Data ScienceLeveraging RAG-powered LLMs for analytical tasks
The emergence of Retrieval-Augmented Generation (RAG) has significantly revolutionised Large Language Models (LLMs), propelling them to unprecedented heights. This development prompts us to consider its integration into the field of Analytics. Explore how Grab harnesses this technology to optimise our analytics processes. -
 Engineering · Data Science
Engineering · Data ScienceEvolution of Catwalk: Model serving platform at Grab
Read about the evolution of Catwalk, Grab's model serving platform, from its inception to its current state. Discover how it has evolved to meet the needs of Grab's growing machine learning model serving requirements. -
 Engineering
EngineeringEnabling conversational data discovery with LLMs at Grab
Discover how Grab is revolutionising data discovery with the power of AI and LLMs. Dive into our journey as we overcome challenges, build groundbreaking tools like HubbleIQ, and transform the way our employees find and access data. Get ready to be inspired by our innovative approach and learn how you can harness the potential of AI to unlock the full value of your organisation's data. -
 Engineering
EngineeringBringing Grab’s Live Activity to Android: Enhancing user experience through custom notifications
Unleashing Live Activity feature for iOS. Live Activity is a feature that enhances user experience by displaying a user interface (UI) outside of the app, delivering real-time updates and interactive content. Discover how its was solutionised at Grab. -
 Engineering · Design
Engineering · DesignUnveiling the process: The creation of our powerful campaign builder
Dive into Trident, our real-time event-driven marketing tool at Grab. Explore the build of the core units powering our If This, Then That (IFTTT) logic. Learn how we deal with complex campaigns and discover the secret behind how we support various processing mechanisms -
 Engineering · Design
Engineering · DesignChimera Sandbox: A scalable experimentation and development platform for Notebook services
Unleashing the potential of machine learning (ML) with Grab's Chimera Sandbox. This scalable platform facilitates rapid development and experimentation of ML solutions, offering deep integration with Large Language Models and a variety of compute instances. Discover how it's driving AI innovation at Grab. -
 Engineering · Design
Engineering · DesignHow we improved translation experience with cost efficiency
Dive into our journey of improving in-app translation experience amidst a post-COVID tourism boom. Discover how we overcame language detection hurdles, crafted an in-house translation model, and implemented stringent quality checks, all while maintaining cost efficiency. -
 Engineering · Data Science
Engineering · Data ScienceLLM-powered data classification for data entities at scale
With the advent of the Large Language Model (LLM), new possibilities dawned for metadata generation and sensitive data identification at Grab. This prompted the inception of our project aimed to integrate LLM classification into our existing data management service. Read to find out how we transformed what used to be a tedious and painstaking process to a highly efficient system and how it has empowered the teams across the organisation. -
 Engineering
EngineeringProfile-guided optimisation (PGO) on Grab services
Profile-guided optimisation (PGO) is a method that tracks CPU profile data and uses that data to optimise your application builds. The AI platform team enabled this on several Grab services to discover the full benefits and caveats of using PGO. Read this article to find out more. -
 Engineering
EngineeringHow we evaluated the business impact of marketing campaigns
Discover how Grab assesses marketing effectiveness using advanced attribution models and strategic testing to improve campaign precision and impact. -
 Engineering
EngineeringNo version left behind: Our epic journey of GitLab upgrades
Join us as we share our experience in developing and implementing a consistent upgrade routine. This process underscored the significance of adaptability, comprehensive preparation, efficient communication, and ongoing learning. -
 Data Science · Engineering · Security
Data Science · Engineering · SecurityEnsuring data reliability and observability in risk systems
As the amount of data Grab handles grows, there is an increased need for quick detections for data anomalies (incompleteness or inaccuracy), while keeping it secure. Read this to learn how the Risk Data team utilised Flink and Datadog to enhance data observability within Grab’s services. -
 Engineering · Data Science
Engineering · Data ScienceGrab Experiment Decision Engine - a Unified Toolkit for Experimentation
Explore how the GrabX Decision Engine, an integral part of Grab's Experimentation platform, streamlines the testing of thousands of experimental variants weekly. This blog delves into how this internally open-sourced package institutionalises best practices in experimental efficiency and analytics, thereby ensuring accurate and reliable conclusions from each experiment. -
 Engineering · Data Science
Engineering · Data ScienceIris - Turning observations into actionable insights for enhanced decision making
With cross-platform monitoring, a common problem is the difficulty in getting comprehensive and in-depth views on metrics, making it tough to see the big picture. Read to find out how the Data Tech team ideated Iris to turn observations into actionable insights for enhanced decision-making. -
 Engineering
EngineeringAndroid App Size at Scale with Project Bonsai
With the size of our app growing to include more features, Grab recognised it as a potential hurdle for new users with small storage capacities or restricted Internet bandwidth. Read to find out more about Project Bonsai and how it reduced app download size and app disk size. -
 Engineering · Data Science
Engineering · Data ScienceEnabling near real-time data analytics on the data lake
As the data lake landscape matures over the years, it presents opportunities to unlock more business value from the data. This correlates with the increased demand for flexible ad-hoc usage of fresh data. This article explores how we implemented data ingestion in Hudi table formats using Flink to meet this business demand. -
 Engineering · Product · Design
Engineering · Product · DesignThe journey of building a comprehensive attribution platform
The Grab superapp offers a comprehensive array of services from ride-hailing and food delivery to financial services. This creates multifaceted user journeys, covering homepages, product pages, checkouts, and interactions with diverse content, including advertisements and promo codes. Read this to find out more. -
 Engineering
EngineeringRethinking Stream Processing: Data Exploration
As Grab matures along the digitalisation journey, it is collecting and streaming event data generated from the end users of its superapp on a larger magnitude than before. Coban, Grab’s data-streaming platform team, is looking to help unlock the value of streaming data at an earlier stage of the data journey before this data is typically stored in a central location (“Data Lake”). This allows Grab to serve its superapp users more efficiently. -
 Engineering · Data Science
Engineering · Data ScienceKafka on Kubernetes: Reloaded for fault tolerance
Dive into this insightful post to explore how Coban, Grab's real-time data streaming platform, has drastically enhanced the fault tolerance on its Kafka on Kubernetes design, to ensure seamless operation even amid unexpected disruptions. -
 Engineering · Security
Engineering · SecurityChampioning CyberSecurity: Grab's bug bounty programme in 2023
Since its launch in 2015, Grab’s Bug Bounty programme has made strides in giving back to the global security community and aiding research. Read this article to find out more about our quarterly campaigns in collaboration with HackerOne and other achievements we’ve had in 2023. -
 Engineering
EngineeringSliding window rate limits in distributed systems
In the field of distributed systems, there are several common challenges, such as rate limiters and fast queries in big data. In this blog post, we delve into how we address these challenges with sliding window rate limits to optimise marketing communications for our users. -
 Engineering · Data Science · Product
Engineering · Data Science · ProductAn elegant platform
Supporting real-time data streaming enables our internal users to build intelligent applications and services, a crucial aspect of continuously out-serving our community. Read this article to understand our journey of building a real-time data streaming platform from pure Infrastructure-as-Code towards a more sophisticated control plane, and the benefits of this solution. -
 Engineering · Data Science · Product
Engineering · Data Science · ProductRoad localisation in GrabMaps
With GrabMaps powering the Grab superapp we have the opportunity to improve our services and enhance our map with hyperlocal data. No matter the use case, road localisation plays an important role in Grab’s map-making process. However, road localisation entails handling a substantial volume of data, making it a costly and time-consuming endeavour. In this article, we explore the strategies we have implemented to drive down costs and reduce processing times associated with road localisation. -
 Engineering · Security
Engineering · SecurityGraph modelling guidelines
Graphs are powerful data representations that detect relationships and data linkages between devices. This is very helpful in revealing fraudulent or malicious users. Graph modelling is the key to leveraging graph capabilities. Read to find out how the GrabDefence team performs graph modelling to create graphs that can help discover potentially malicious data linkages. -
 Engineering · Data Science
Engineering · Data ScienceScaling marketing for merchants with targeted and intelligent promos
Apart from ensuring advertisements reach the right audience, it is also important to make promos by merchants more targeted and intelligent to help scale their marketing. With Grab’s innovative AI tool, merchants can boost sales while cutting costs. Dive into this game-changing tool that’s reshaping the future of marketing and find out how the Data Science team at Grab used automation and made promo assignments a more seamless and intelligent process. -
 Engineering · Data Science
Engineering · Data ScienceStepping up marketing for advertisers: Scalable lookalike audience
A key challenge in advertising is reaching the right audience who are most likely to use your product. Read this article to find out how the Data Science team improved advertising effectiveness by using lookalike audiences to identify individuals who share similar characteristics with an existing consumer base. -
 Engineering · Data Science · Product
Engineering · Data Science · ProductBuilding hyperlocal GrabMaps
Being hyperlocal is a key advantage for GrabMaps. In this article we will explain what being hyperlocal means and how it helps GrabMaps bring value to our driver-partners and passengers through the Grab platform. -
 Engineering
EngineeringStreamlining Grab's Segmentation Platform with faster creation and lower latency
Since 2019, Grab's Segmentation Platform has served as a comprehensive solution for user segmentation and audience creation across all business verticals. This article offers an insider look at the platform's design and the team's efforts to optimise segment storage, ultimately reducing read latency and unlocking new segmentation possibilities. -
 Engineering · Security
Engineering · SecurityZero traffic cost for Kafka consumers
Grab's data streaming infrastructure runs in the cloud across multiple Availability Zones for high availability and resilience, but this also incurs staggering network traffic cost. In this article, we describe how enabling our Kafka consumers to fetch from the closest replica helped significantly improve the cost efficiency of our design. -
 Engineering
EngineeringGo module proxy at Grab
While consolidating code into a single monorepo has its benefits, there are also several challenges that come with managing a large monorepo like slow performance and low developer productivity. Find out how Grab’s FLIP team contributes and leverages the open-sourced Athens Go module proxy to improve developer productivity at Grab. -
 Engineering · Security
Engineering · SecurityPII masking for privacy-grade machine learning
Data engineers at Grab work with large sets of data to build and train advanced machine learning models to continuously improve our user experience. However, as with any data-handling company, dealing with users' data may present a potential privacy risk as it contains Personally Identifiable Information (PII). Read this article to find out more about Grab’s mature privacy protective measures and how our data streaming team uses PII tagging and masking on data streaming pipelines to protect our users. -
 Engineering
EngineeringPerformance bottlenecks of Go application on Kubernetes with non-integer (floating) CPU allocation
At Grab, we have been running our Go based stream processing framework (SPF) on Kubernetes for several years. But as the number of SPF pipelines increases, we noticed some performance bottlenecks and other issues. Read to find out how this issue came about and how the Coban team resolved it with non-integer CPU allocation. -
 Engineering
EngineeringHow we improved our iOS CI infrastructure with observability tools
After upgrading to Xcode 13.1, we noticed a few issues such as instability of the CI tests and high CPU utilisation. Read to find out how the Test Automation - Mobile team investigated these issues and resolved them by integrating observability tools into our iOS CI development process. -
 Engineering
Engineering2.3x faster using the Go plugin to replace Lua virtual machine
The Talaria open-source project has made significant improvements by replacing Lua VM with the Go plugin resulting in 2.3x faster performance and memory usage reduction. Talaria is a time-series database designed for Big Data systems used to process millions of transactions and connections daily at Grab, requiring scalable data-driven decision-making. -
 Engineering
EngineeringSafer deployment of streaming applications
As Flink becomes more popular with real-time stream applications, we realise that Flink deployments are sometimes stressful and prone to errors. The Coban team deep dives into the issues with our existing Flink deployment process, possible mitigations, and the eventual solution to ensure safer deployments of Flink streaming applications. -
 Engineering · Design
Engineering · DesignMessage Center - Redesigning the messaging experience on the Grab superapp
Grab’s messaging feature was designed for two-party communications, but as our superapp grew to include more features, we became more aware of the limitations in our app. Read to find out how we redesigned the messaging experience to make it more extensible and future-proof. -
 Engineering · Design
Engineering · DesignEvolution of quality at Grab
Testing is typically done after development is complete, which often results in bugs being discovered late in the process. Read to find out how Grab has improved its quality to scale and support the superapp experience. This evolution also brings a cultural shift for quality mindset in teams, enabling us to deliver faster with a better experience for our users. -
 Engineering · Design
Engineering · DesignHow OVO determined the right technology stack for their web-based projects
As companies grow in today's technology landscape, it often leads to a diverse set of technology stacks being used in different teams, which can lead to bigger problems in the future. Find out how the OVO team compared and analysed different technologies to find the one that best met their needs. -
 Engineering · Security
Engineering · SecurityMigrating from Role to Attribute-based Access Control
To ensure our consumers continue to be well-protected, we need to ensure our data access measures are compliant with evolving security standards. With more services and resources to manage, it becomes increasingly difficult to maintain a frictionless process. Read to find out how we solve this by migrating from role to attribute-based access control. -
 Engineering
EngineeringSecuring GitOps pipelines
This article illustrates how Grab’s real-time data platform team secured GitOps pipelines at scale with our in-house GitOps implementation. -
 Engineering · Product
Engineering · ProductNew zoom freezing feature for Geohash plugin
Built by Grab, the Geohash Java OpenStreetMap Editor (JOSM) plugin is widely used in map-making, but a common pain point is the inability to zoom in to a specific region without displaying new geohashes. Read to find out more about the issue and how the latest update addresses it. -
 Engineering · Security · Data Science
Engineering · Security · Data ScienceGraph service platform
Graphs are powerful data representations that detect relationships and data linkages between devices and help reveal fraudulent or malicious users. Learn how GrabDefence built the graph service platform to help discover potentially malicious data linkages. -
 Engineering · Security
Engineering · SecurityZero trust with Kafka
In addition to ensuring the high performance and availability of our services, security continues to be one of our highest priorities. Read this article to find out how the Coban team enhances security by moving from network-based access control to zero trust with Kafka. -
 Engineering · Product · Design
Engineering · Product · DesignHow KartaCam powers GrabMaps
The foundation for making maps lies in imagery and ensuring that it is fresh, high quality, and collected in an efficient yet low-cost manner. Read this to find out how the Geo team created KartaCam, how it addresses those concerns, and its future enhancements. -
 Engineering · Data Science · Security
Engineering · Data Science · SecurityGraph for fraud detection
Fraud detection has become increasingly important in a fast growing business as new fraud patterns arise when a business product is introduced. We need a sustainable framework to combat different types of fraud and prevent fraud from happening. Read and find out how we use graph-based models to protect our business from various known and unknown fraud risks. -
 Engineering · Data Science
Engineering · Data ScienceQuery expansion based on user behaviour
User behaviour data is a gold mine to gain insights about users and help us improve user experience. In this blog, we explore a query expansion framework based on user rewrite behaviour and how it improves user search experience and conversion. -
 Engineering · Data Science · Security
Engineering · Data Science · SecurityUsing mobile sensor data to encourage safer driving
Telematics is most commonly used to monitor vehicle movements and track driving safety, profiling, fleet optimisation and possible productivity improvements. Read this to find out more about how Grab uses telematics to encourage safer driving across our driver and delivery partner fleet. -
 Engineering · Data Science
Engineering · Data ScienceAutomatic rule backtesting with large quantities of data
At Grab, real-time fraud detection is built on a rule engine. As data scientists and analysts, we need to analyse and simulate a rule on historical data to check the performance and accuracy of the rule. Backtesting, also known as Replay, enables analysts to run simulations of either newly-invented rules, or evaluate the performance of existing rules using past events ranging from days to months, and significantly improve rule creation efficiency. -
 Engineering · Data Science
Engineering · Data ScienceHow we store and process millions of orders daily
The Grab Order Platform is a distributed system that processes millions of GrabFood or GrabMart orders every day. Learn about how the Grab order platform stores food order data to serve transactional (OLTP) and analytical (OLAP) queries. -
 Engineering
EngineeringHow we automated FAQ responses at Grab
Most frequently asked questions (FAQ) are repetitive, which hinder on-call engineers' productivity. Read to find out how we automated FAQ responses at Grab, allowing engineers to focus on operational tasks. -
 Engineering · Security · Data Science
Engineering · Security · Data ScienceGraph Networks - 10X investigation with Graph Visualisations
As fraud schemes get more complex, we need to stay one step ahead by improving fraud investigation methods. Read to find out more about graph visualisation, why we need it and how it helps with uncovering patterns and relationships. -
 Engineering · Security · Data Science
Engineering · Security · Data ScienceHow facial recognition technology keeps you safe
Facial recognition technology has grown tremendously in recent years due to the rise of deep learning techniques and accelerated digital transformation. Read to find out more about facial recognition technology in Grab and the components that help keep you safe. -
 Engineering · Security
Engineering · SecurityGraph concepts and applications
Graph theory-based approaches show the concepts underlying the behaviour of massively complex systems and networks. Read to find out how graphs came about, where they can be used and the part they play in graph technology. -
 Engineering · Data Science
Engineering · Data ScienceAutomated Experiment Analysis - Making experimental analysis scalable
Analysts and data scientists invest lots of time into creating trustworthy experiments, which are key to making sound decisions. Read to find out how Automated Experiment Analysis helps make experimental analysis more scalable. -
 Engineering
EngineeringSearch architecture revamp
Grab’s search architecture was initially designed to only support exact text matching based on user queries. Find out what problems the Deliveries search team faced and how they improved the search architecture to address these issues. -
 Engineering
EngineeringEmbracing a Docs-as-Code approach
Read to find out how Grab is using the Docs-as-Code approach to improve technical documentation. -
 Engineering · Security
Engineering · SecurityGraph Networks - Striking fraud syndicates in the dark
As fraudulent entities evolve and get smarter, Grab needs to continuously enhance our defences to protect our consumers. Read to find out how Graph Networks help the Integrity team advance fraud detection at Grab. -
 Engineering
EngineeringHow we reduced our CI YAML files from 1800 lines to 50 lines
GitLab and its tooling are are an integral part of the machine learning platform team stack, for continuous delivery of machine learning. One of our core products is MerLin Pipelines. We were reaching certain limitations of GitLab for large repositories by way of includes and nested gitlab-ci YAML files. -
 Engineering
EngineeringHow Kafka Connect helps move data seamlessly
Grab’s real-time data platform team (Coban) covers the importance of moving data in and out of Kafka easily and how Kafka Connect helps with that. -
 Engineering
EngineeringSupporting large campaigns at scale
Running batch jobs targeting a large user base is a challenge. Find out how we designed our system to tackle the challenge at scale. -
 Engineering · Data Science
Engineering · Data ScienceHow telematics helps Grab to improve safety
Coupled with data science, telematics can help to detect traffic events such as harsh braking and unsafe lane changes so we can provide a safer experience for our users. Read on to find out more about the challenges faced and how we addressed them with telematics. -
 Engineering · Data Science
Engineering · Data ScienceReal-time data ingestion in Grab
When it comes to data ingestion, there are several prevailing issues that come to mind: data inconsistency, integrity and maintenance. Find out how the Caspian team leveraged real-time data ingestion to help address these pain points. -
 Engineering
EngineeringAbacus - Issuing points for multiple sources
Learn about the challenges of points rewarding and how GrabRewards Points are rewarded for different Grab offerings. -
 Engineering
EngineeringExposing a Kafka Cluster via a VPC Endpoint Service
Establishing communications between cloud resources that are hosted on different Virtual Private Clouds (VPC) can be complex and costly. Find out how the Coban team used a VPC Endpoint Service to expose an Apache Kafka cluster across multiple Availability Zones to a different VPC. -
 Engineering
EngineeringSearch indexing optimisation
Learn about the different optimisation techniques when building a search index. -
 Engineering
EngineeringAutomating Multi-Armed Bandit testing during feature rollout
Find out how you can run an automated test and simultaneously roll out a new feature. -
 Engineering
EngineeringProtecting Personal Data in Grab's Imagery
Learn how Grab improves privacy protection to cater to various geographical locations. -
 Engineering
EngineeringProcessing ETL tasks with Ratchet
Read about what Data and ETL pipelines are and how they are used for processing multiple tasks in the Lending Team at Grab. -
 Engineering
EngineeringApp Modularisation at Scale
Read up to know how we improved our app’s build time performance and developer experience at Grab. -
 Engineering
EngineeringDebugging High Latency Due to Context Leaks
Learn how the Marketplace Tech Family debugged and resolved Market-Store's high latency issues. -
 Engineering
EngineeringBuilding a Hyper Self-Service, Distributed Tracing and Feedback System for Rule & Machine Learning (ML) Predictions
Find out how the Trust, Identity, Safety, and Security (TISS) team improved machine learning predictions with Archivist, an in-house built solution. -
 Engineering
EngineeringOur Journey to Continuous Delivery at Grab (Part 2)
Read more about our long awaited piece on the automation work we have made through integration and hermeticity. -
 Engineering
EngineeringHow We Improved Agent Chat Efficiency with Machine Learning
Read to find out how Customer Support Experience's Phoenix live chat team improved agent chat efficiency with machine learning. -
 Engineering
EngineeringHow Grab Leveraged Performance Marketing Automation to Improve Conversion Rates by 30%
Read to find out how Grab's Performance Marketing team leveraged on automation to improve conversion rates. -
 Engineering
EngineeringOne Small Step Closer to Containerising Service Binaries
Learn how Grab is investigating and reducing service binary size for Golang projects. -
 Engineering
EngineeringCustomer Support Workforce Routing
Read how we built our in-house workforce routing system at Grab. -
 Engineering
EngineeringServing Driver-partners Data at Scale Using Mirror Cache
Find out how a team at Grab used Mirror Cache, an in-memory local caching solution, to serve driver-partners data efficiently. -
 Engineering
EngineeringTrident - Real-time Event Processing at Scale
Find out where the messages and rewards come from, that arrive on your Grab app. Walk through scaling and processing optimisations that achieve tremendous throughput. -
 Engineering
EngineeringPharos - Searching Nearby Drivers on Road Network at Scale
Learn how Grab stores driver locations and how these locations are used to find nearby drivers around you. -
 Engineering
EngineeringHow Grab is Blazing Through the Superapp Bazel Migration
Learn how we planned and started migrating our superapp to Bazel at Grab. -
 Engineering
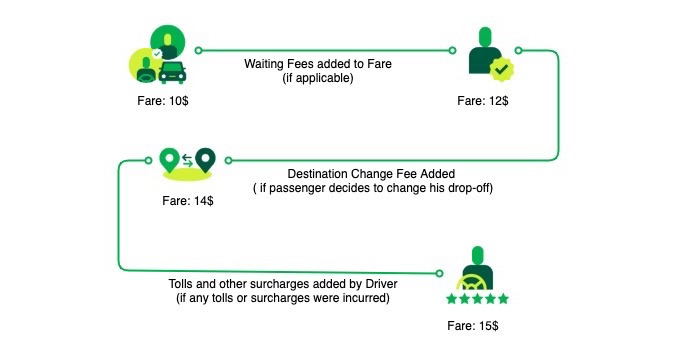
EngineeringDemocratising Fare Storage at Scale Using Event Sourcing
Read how we built Grab's single source of truth for fare storage and management. In this post, we explain how we used the Event Sourcing pattern to build our fare data store. -
 Engineering
EngineeringKeeping 170 Libraries Up to Date on a Large Scale Android App
Learn how we maintain our libraries and prevent defect leaks in our Grab Passenger app. -
 Engineering
EngineeringOptimally Scaling Kafka Consumer Applications
Read this deep dive on our Kubernetes infrastructure setup for Grab's stream processing framework. -
 Engineering
EngineeringOur Journey to Continuous Delivery at Grab (Part 1)
Continuous Delivery is the principle of delivering software often, everyday. Read more to find out how we implemented continuous delivery at Grab. -
 Engineering
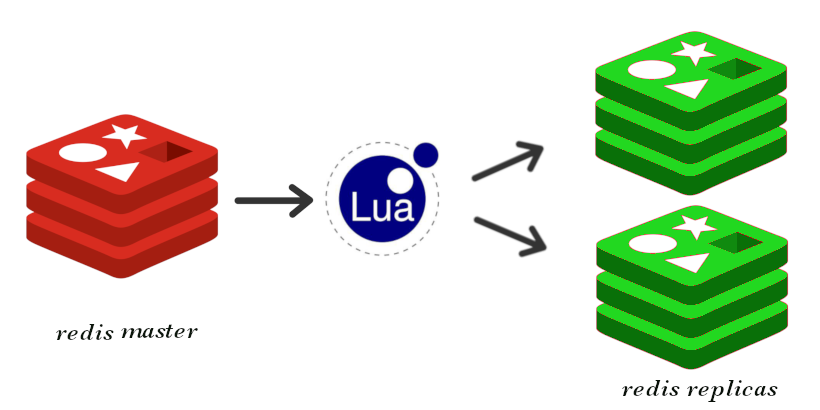
EngineeringUncovering the Truth Behind Lua and Redis Data Consistency
Redis does not guarantee the consistency between master and its replica nodes when Lua scripts are used. Read more to find out why and how to guarantee data consistency. -
 Engineering · Data Science
Engineering · Data ScienceSecuring and Managing Multi-cloud Presto Clusters with Grab’s DataGateway
This blog post discusses how Grab's DataGateway plays a key role in supporting hundreds of users in our entire Presto ecosystem - from managing user access, cluster selection, workload distribution, and many more. -
 Engineering
EngineeringGo Modules- A Guide for monorepos (Part 2)
This is the second post on the Go module series, which highlights Grab’s experience working with Go modules in a multi-module monorepo. Here, we discuss the additional solutions for addressing dependency issues, as well as cover automatic upgrades. -
 Engineering · Data Science
Engineering · Data ScienceThe Journey of Deploying Apache Airflow at Grab
This blog post shares how we designed and implemented an Apache Airflow-based scheduling and orchestration platform for teams across Grab. -
 Engineering
EngineeringHow We Built Our In-house Chat Platform for the Web
This blog post shares our learnings from building our very own chat platform for the web. -
Engineering
Go Modules- A Guide for monorepos (Part 1)
This post is the first in a series of blogs about Grab’s experience with Go modules in a multi-module monorepo. Here, we discuss the challenges we faced along the way and the solutions we came up with. -
 Engineering
EngineeringTackling UI Test Execution Time Imbalance for Xcode Parallel Testing
This blog post introduces how we use Xcode parallel testing to balance test execution time and improve the parallelism of our systems. We also share how we overcame a challenge that prevented us from running the tests efficiently. -
 Engineering
EngineeringReturning 575 Terabytes of Storage Space to Our Users
This blog explains how we measured and reduced our app's storage footprint on user devices. -
 Engineering
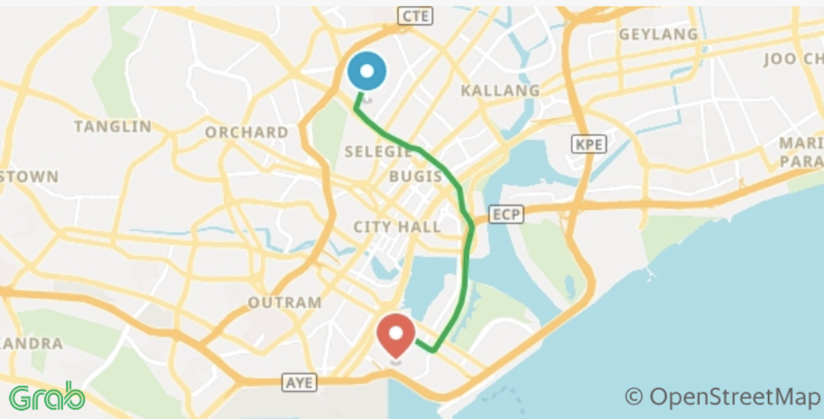
EngineeringGrab-Posisi - Southeast Asia’s First Comprehensive GPS Trajectory Dataset
This blog highlights Grab's latest GPS trajectory dataset - its content, format, applications, and how you can access the dataset for your research purpose. -
 Engineering
EngineeringHow We Prevented App Performance Degradation from Sudden Ride Demand Spikes
This blog addresses how engineers overcame the challenges Grab faced during the initial days due to sudden spike in ride demand. -
 Engineering
EngineeringPlumbing At Scale
This article details our journey building and deploying an event sourcing platform in Go, building a stream processing framework over it, and then scaling it (reliably and efficiently) to service over 300 billion events a week. -
 Engineering
EngineeringJourney to a Faster Everyday Superapp Where Every Millisecond Counts
This post narrates the journey of our performance improvement efforts on the Grab passenger app. It highlights how we were able to reduce the time spent starting the app by more than 60%, while preventing regressions introduced by new features. -
 Engineering
EngineeringMarionette - Enabling E2E User-scenario Simulation
Do you know how we get early feedback on any breaking changes? Read through our blog to find out how Marionette, an in-house simulation platform, detects breaking changes in booking workflows. It even generates resources for running simulations and facilitates the testing of microservices powering our driver and passenger apps. -
 Engineering
EngineeringHow We Implemented Domain-Driven Development in Golang
Are you curious how we quickly enabled our partners to self-service using our platform? Have you wondered how some teams at Grab implemented domain-driven development while using Golang? Read this blog post to know more. -
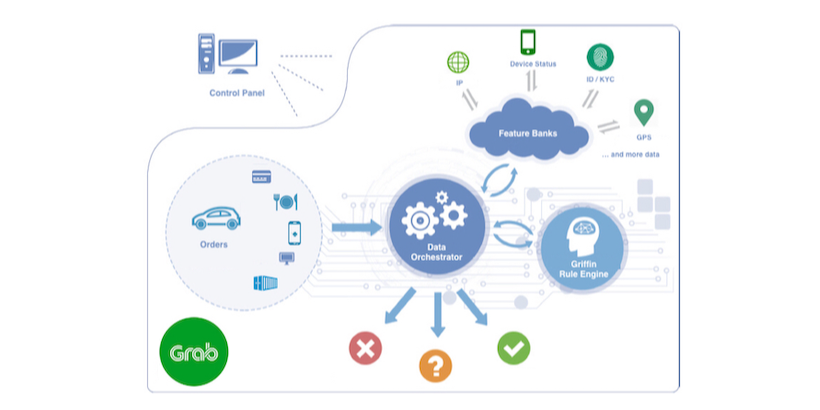 Engineering
EngineeringGriffin, an Anti-fraud Risk Rule Engine Making Billions of Predictions Daily
This blog highlights Grab’s high-performance risk rule engine that automates the creation of rules to detect fraudulent activities with minimal efforts by engineers. -
 Engineering
EngineeringUsing Grab’s Trust Counter Service to Detect Fraud Successfully
This blog introduces Grab’s Trust Counter service for detecting fraud. It explains how the solution was designed so that different stakeholders like data analysts and data scientists can use the Counter service without any manual intervention from engineers. The Counter service provides a reliable data feed to the data science world. -
 Engineering
EngineeringBeing a Principal Engineer at Grab
Curious about what a Principal Engineer role at Grab entails? Our Principal Engineers' responsibilities range from solving complex problems, taking care of the system-level architecture, collaborating with cross-functional teams, providing mentorship, and more. -
 Data Science · Engineering
Data Science · EngineeringData First, SLA Always
Introducing Trailblazer, the Data Engineering team’s solution to implementing change data capture of all upstream databases. In this article, we introduce the reason why we needed to move away from periodic batch ingestion towards a real time solution and show how we achieved this through an end to end streaming pipeline. -
 Engineering
EngineeringHow We Built a Logging Stack at Grab
This blog post explains what we did to solve our inhouse logging problem around the lack of visualizations and metrics for our service logs. -
 Engineering · Data Science
Engineering · Data ScienceCatwalk: Serving Machine Learning Models at Scale
This blog post explains why and how we came up with a machine learning model serving platform to accelerate the use of machine learning in Grab. -
 Engineering
EngineeringReact Native in GrabPay
This blog post describes how we used React Native to optimize the Grab PAX app. -
 Engineering
EngineeringPreventing Pipeline Calls from Crashing Redis Clusters
This blog post describes Grab’s post-mortem findings for the outage caused by the Redis Cluster failure. -
 Engineering
EngineeringLoki, a Dynamic Mock Server for HTTP/TCP Testing
Read our blog to know how Loki, a dynamic mock server, makes local box testing of mobile apps easy, repeatable, and exhaustive. It supports both HTTP and TCP protocols and can provide dynamic runtime responses. -
 Engineering
EngineeringDesigning Resilient Systems Beyond Retries (Part 3): Architecture Patterns and Chaos Engineering
This post is the third of a three-part series on going beyond retries and circuit breakers to improve system resiliency. This whole series covers techniques and architectures that can be used as part of a strategy to improve resiliency. In this article, we will focus on architecture patterns and chaos engineering to reduce, prevent, and test resiliency. -
 Engineering
EngineeringDesigning Resilient Systems Beyond Retries (Part 2): Bulkheading, Load Balancing, and Fallbacks
This post is the second of a three-part series on going beyond retries to improve system resiliency. We’ve previously discussed about rate-limiting as a strategy to improve resiliency. In this article, we will cover these techniques: bulkheading, load balancing, and fallbacks. -
 Engineering
EngineeringDesigning Resilient Systems Beyond Retries (Part 1): Rate-Limiting
This post is the first of a three-part series on going beyond retries to improve system resiliency. In this series, we will discuss other techniques and architectures that can be used as part of a strategy to improve resiliency. To start off the series, we will cover rate-limiting. -
 Engineering
EngineeringContext Deadlines and How to Set Them
This blog post explains from the ground up a strategy for configuring timeouts and using context deadlines correctly, drawing from our experience developing microservices in a large scale and often turbulent network environment. -
 Data Science · Engineering · Product · Design
Data Science · Engineering · Product · DesignRecipe for Building a Widget: How We Helped to “Peak-Shift” Demand by Helping Passengers Understand Travel Trends
We help to “peak-shift” demand by helping passengers understand travel trends with Grab’s data. Curious to know how we empower our passengers to make better travel decisions? Read on! -
 Engineering
EngineeringStructured Logging: The Best Friend You’ll Want When Things Go Wrong
This blog post describes how we built a structured logging framework that integrates well with our existing Elastic stack-based logging backend, allowing us to do logging better and more efficiently. -
 Engineering
EngineeringHow We Simplified Our Data Ingestion & Transformation Process
This blog post describes how Grab built a scalable data ingestion system and how we went from prototyping with Spark Streaming to running a production-grade data processing cluster written in Golang. -
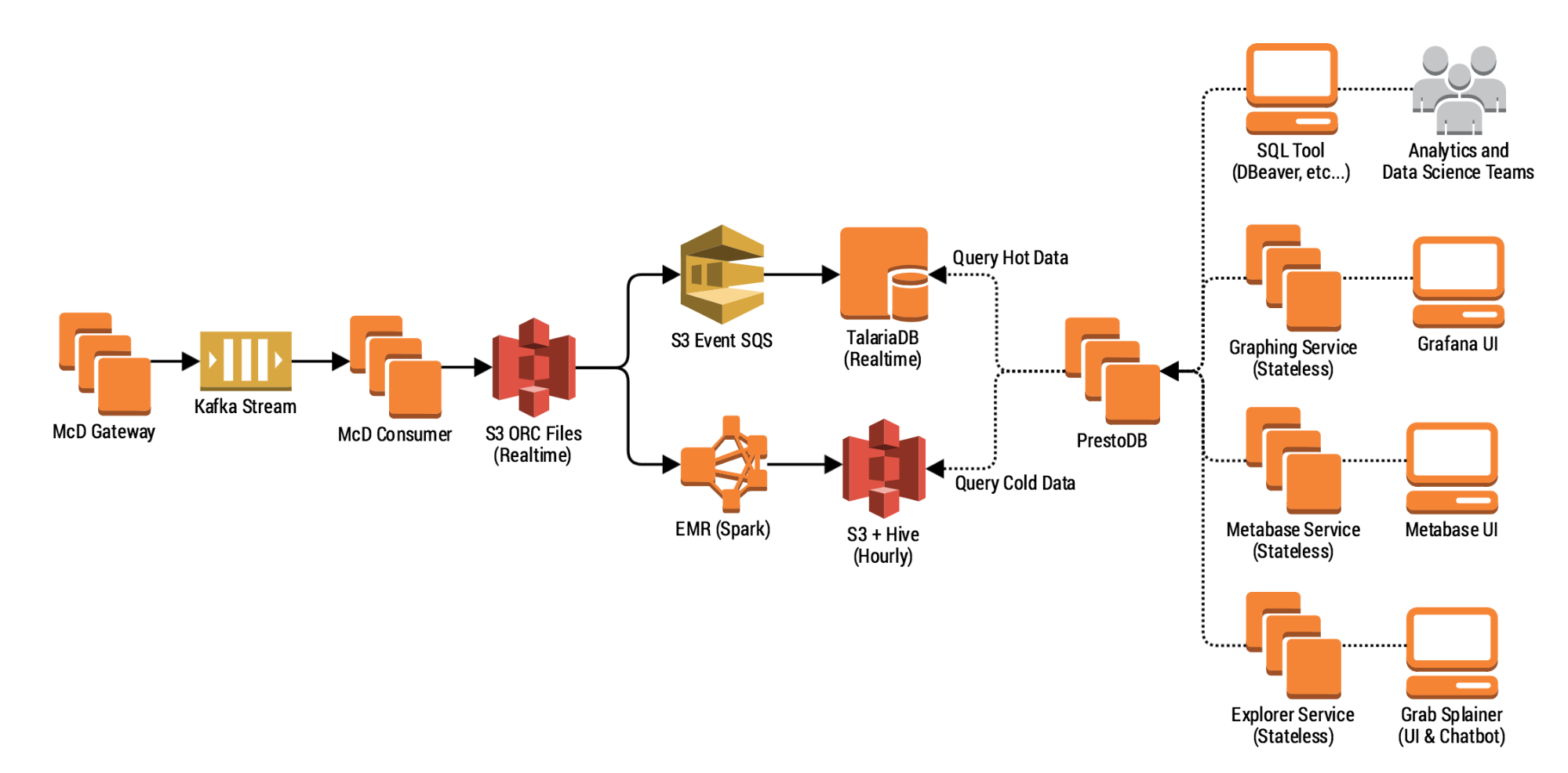 Engineering
EngineeringA Lean and Scalable Data Pipeline to Capture Large Scale Events and Support Experimentation Platform
This blog post focuses on the lessons we learned while building our batch data pipeline. -
 Engineering
EngineeringDesigning Resilient Systems: Circuit Breakers or Retries? (Part 2)
Grab designs fault-tolerant systems that can withstand failures allowing us to continuously provide our consumers with the many services they expect from us. -
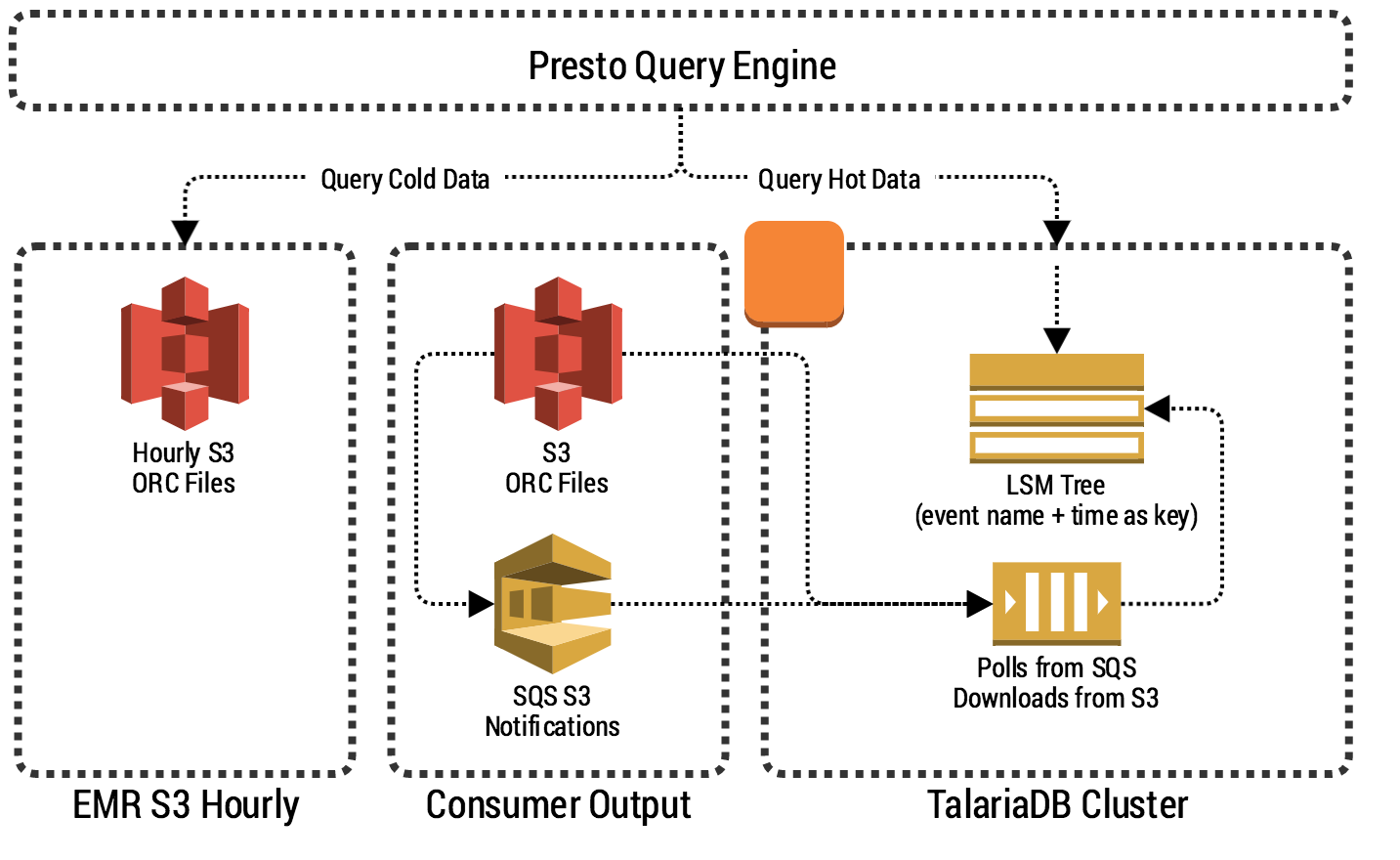 Engineering
EngineeringQuerying Big Data in Real-time with Presto & Grab's TalariaDB
In this article, we focus on TalariaDB, a distributed, highly available, and low latency time-series database that stores real-time data. For example, logs, metrics, and click streams generated by mobile apps and backend services that use Grab's Experimentation Platform SDK. It "stalks" the real-time data feed and only keeps the last one hour of data. -
 Engineering
EngineeringDesigning Resilient Systems: Circuit Breakers or Retries? (Part 1)
Grab designs fault-tolerant systems that can withstand failures allowing us to continuously provide our consumers with the many services they expect from us. -
 Engineering
EngineeringOrchestrating Chaos Using Grab's Experimentation Platform
At Grab, we practice chaos engineering by intentionally introducing failures in a service or component in the overall business flow. But the failed’ service is not the experiment’s focus. We’re interested in testing the services dependent on that failed service. -
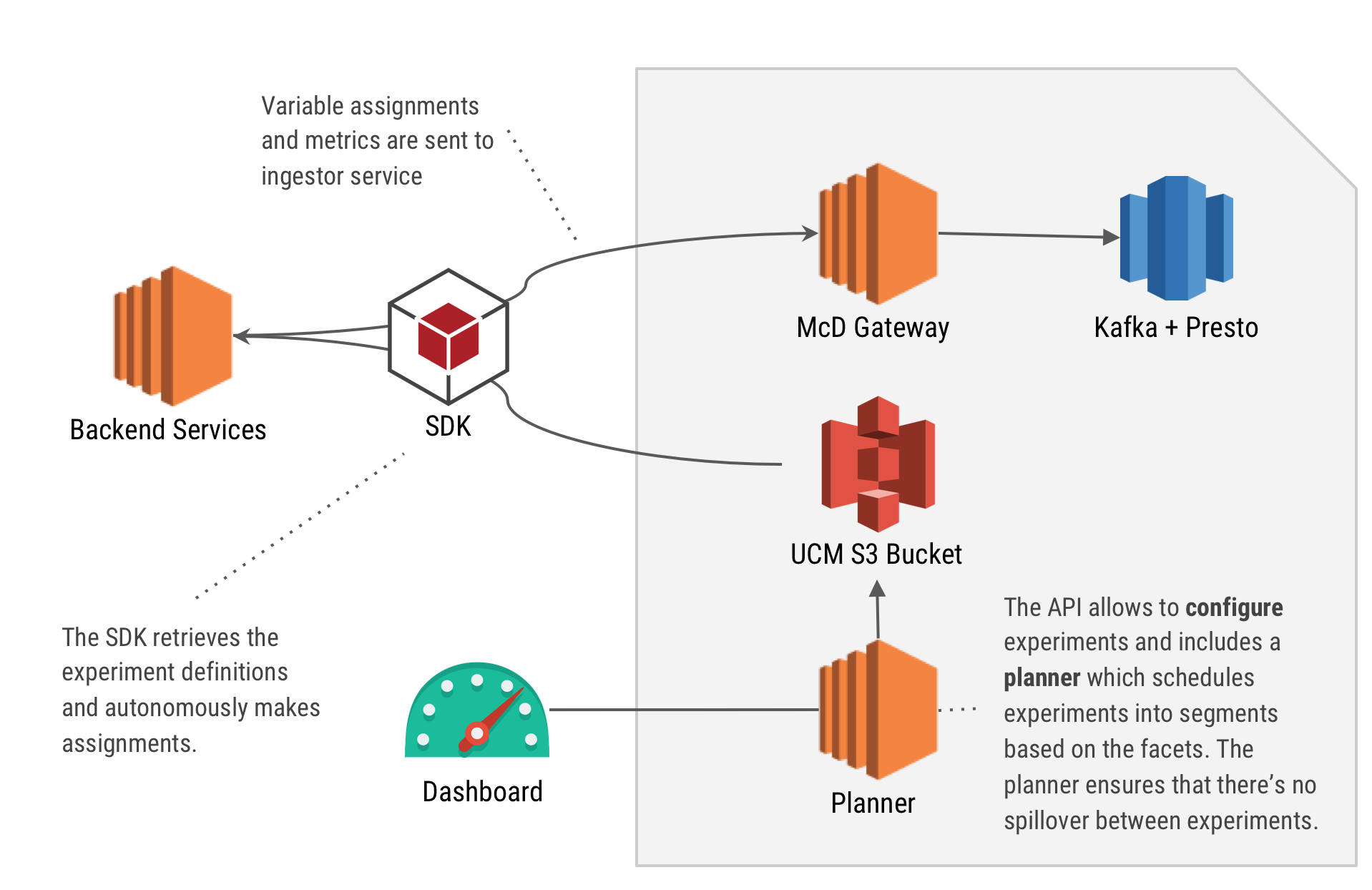 Engineering
EngineeringReliable and Scalable Feature Toggles and A/B Testing SDK at Grab
Grab’s feature toggle SDK provides a dynamic feature toggle capability to our engineering, data, product, and even business teams. Feature toggles also let teams modify system behaviour without changing code. Developers use the feature flags to keep new features hidden until product and marketing teams are ready to share and to run experiments (A/B tests) by dynamically changing feature toggles for specific users, rides, etc. -
 Engineering
EngineeringMockers - Overcoming Testing Challenges at Grab
Sustaining quality in fast paced development is a challenge. At Grab, we use Mockers - a tool to expand the scope of local box testing. It helps us overcome testing challenges in a microservice architecture. -
 Engineering
EngineeringHow We Designed the Quotas Microservice to Prevent Resource Abuse
Reliable, scalable, and high performing solutions for common system level issues are essential for microservice success, and there is a Grab-wide initiative to provide those common solutions. As an important component of the initiative, we wrote a microservice called Quotas, a highly scalable API request rate limiting solution to mitigate the problems of service abuse and cascading service failures. -
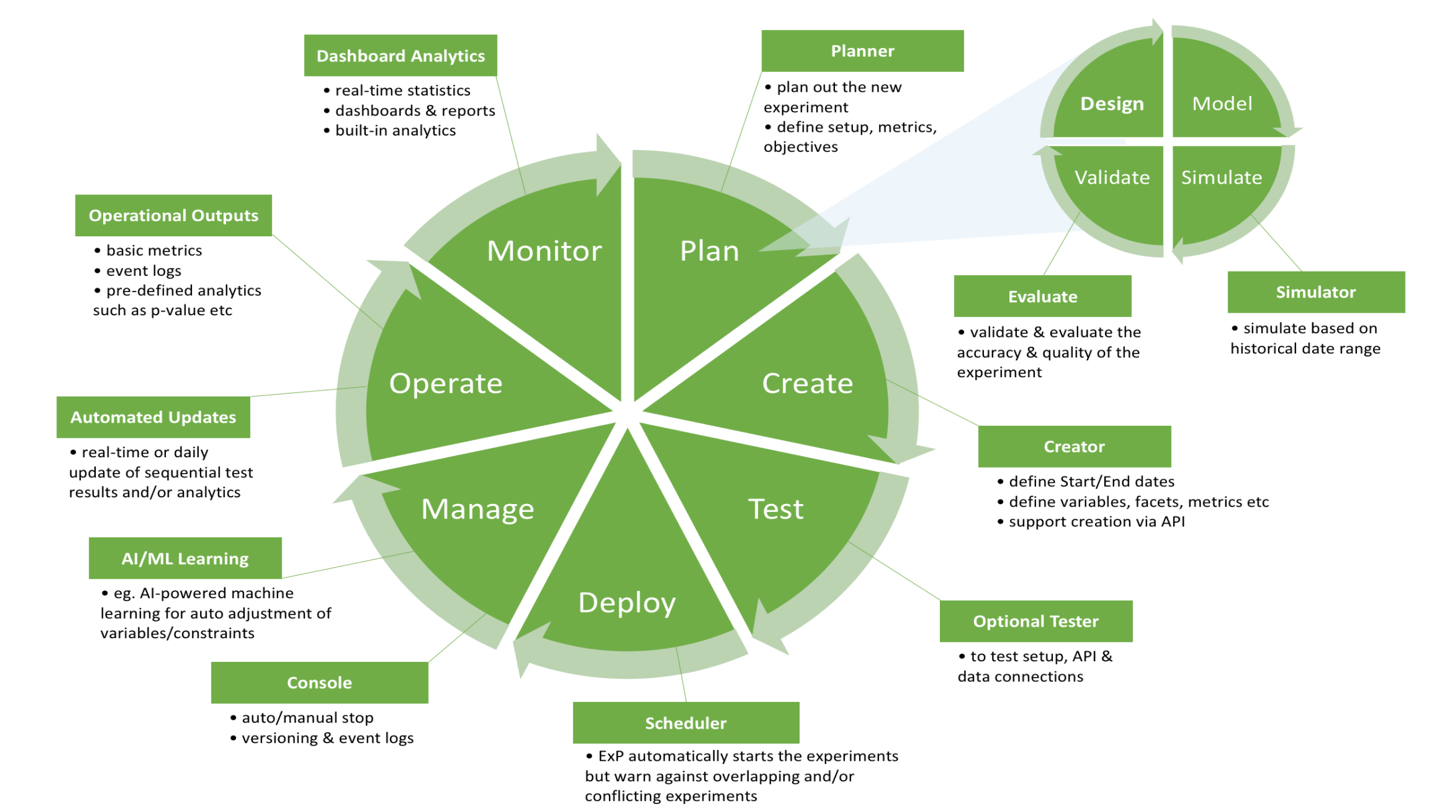 Engineering
EngineeringBuilding Grab’s Experimentation Platform
At Grab, we continuously strive to improve the user experience of our app for both our passengers and driver-partners. To do that, we’re constantly experimenting, and in fact, many of the improvements we roll out to the Grab app are a direct result of successful experiments. -
 Engineering
EngineeringIntroducing Grab-Kit: Distributed Service Design at Grab
As we evolved from a single monolithic application to a microservices-based architecture, we were faced with a new challenge. How do we support exponential growth while maintaining consistency, coordination, and quality? -
 Engineering
EngineeringDeep Dive into Database Timeouts in Rails
Disaster strikes when you do not configure timeout values properly. In this post, we dive into the details of how timeouts work with Ruby on Rails and Databases. -
 Engineering
EngineeringDealing with the Meltdown Patch at Grab
The meltdown attack reported recently had far reaching implications in terms of security as well as performance. This post is a quick rundown of what performance impacts we noted as well as how we went on to mitigate them. -
 Engineering
EngineeringThe Art of Hiring Good Engineers
Hiring the first five good engineers in your team requires a different approach to hiring the first twenty good engineers. The approach to designing this process will be even more different, when you want to hire to scale up to a 100 Engineers... or even to 300. -
 Engineering
EngineeringMigrating Existing Datastores
At Grab we take pride in creating solutions that impact millions of people in Southeast Asia and as they say, with great power comes great responsibility. As an app with 55 million downloads and 1.2 million drivers, it's our responsibility to keep our systems up-and-running. Any downtime causes drivers to miss earning and passengers to miss their appointments. -
 Engineering
EngineeringSo You Need to Hire Good Engineers
If you are in a fast growing tech startup, you're probably actively interviewing and hiring engineers to scale teams. My question to you is, what hiring strategy are you using when interviewing engineering warriors? -
 Engineering
EngineeringCome and #hackallthethings at Grab
For the longest time, security has been at the center of our priorities. There’s nothing more self-evident about the trust our millions of driving partners and consumers put in Grab. We strive every day to build the best tools available to ensure their data stays secure. -
Engineering
How We Scaled Our Cache and Got a Good Night's Sleep
Caching is arguably the most important and widely used technique in computer industry, from CPU to Facebook live videos, cache is everywhere. -
 Engineering
EngineeringGrab's Front End Study Guide
Grab is Southeast Asia (SEA)’s leading transportation platform and our mission is to drive SEA forward, leveraging on the latest technology and the talented people we have in the company. As of May 2017, we handle 2.3 million rides daily and we are growing and hiring at a rapid scale. To keep up with Grab’s phenomenal growth, our web team and web platforms have to grow as well. Fortunately, or unfortunately, at Grab, the web team has been keeping up with the latest best practices and has incorporated the modern JavaScript ecosystem in our web apps. -
Engineering
DNS Resolution in Go and Cgo
This article is part two of a two-part series. In this article, we will talk about RFC 6724 (3484), how DNS resolution works in Go and Cgo, and finally explaining why disabling IPv6 also disables the sorting of IP Addresses. -
 Engineering
EngineeringDriving Southeast Asia Forward with AWS
My name is Arul Kumaravel, VP of Engineering at Grab. Grab's mission is to drive Southeast Asia (SEA) forwards. Today I would like to share with you how AWS is helping us with this mission. -
Engineering
Troubleshooting Unusual AWS ELB 5XX Error
This article is part one of a two-part series. In this article we explain the ELB 5XX errors which we experience without an apparent reason. We walk you through our investigative process and show you our immediate solution to this production issue. In the second article, we will explain why the non-intuitive immediate solution works and how we eventually found a more permanent solution. -
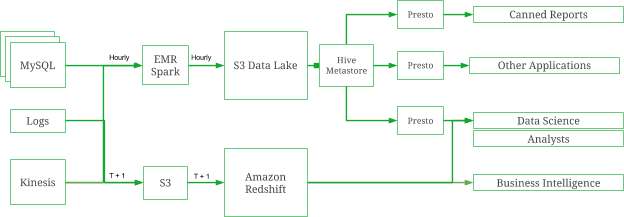 Engineering
EngineeringScaling Like a Boss with Presto
A year ago, the data volumes at Grab were much lower than the volume we currently use for data-driven analytics. We had a simple and robust infrastructure in place to gather, process and store data to be consumed by numerous downstream applications, while supporting the requirements for data science and analytics. -
 Engineering
EngineeringDeep Dive into iOS Automation at Grab - Continuous Delivery
This is the second part of our series "Deep Dive into iOS Automation at Grab", where we will cover how we manage continuous delivery. As a common solution to Apple developer account device whitelist limitation, we use an enterprise account to distribute beta apps internally. There are 4 build configurations per target. -
Engineering
Deep Dive into iOS Automation at Grab - Integration Testing
This is the first part of our series "Deep Dive Into iOS Automation At Grab", where we will cover testing automation in the iOS team. Over the past two years at Grab, the iOS passenger app team has grown from 3 engineers in Singapore to 20 globally. Back then, each one of us was busy shipping features and had no time to set up a proper automation process. -
Engineering
A Key Expired in Redis, You Won't Believe What Happened Next
One of Grab's more popular caching solutions is Redis (often in the flavour of the misleadingly named ElastiCache), and for most cases, it works. Except for that time it didn't. Follow our story as we investigate how Redis deals with consistency on key expiration. -
 Engineering
EngineeringHow Grab Hires Engineers in Singapore
Working at Grab will be the “most challenging yet rewarding opportunity” any employee will ever encounter. -
 Engineering
EngineeringBattling with Tech Giants for the World's Best Talent
Grab steadily attracts a diverse set of engineers from around the world in its three R&D centres: Singapore, Seattle, and Beijing. Right now, half of Grab’s top leadership team is made up of women and we have attracted people from five continents to work together on solving the biggest challenges for Southeast Asia. -
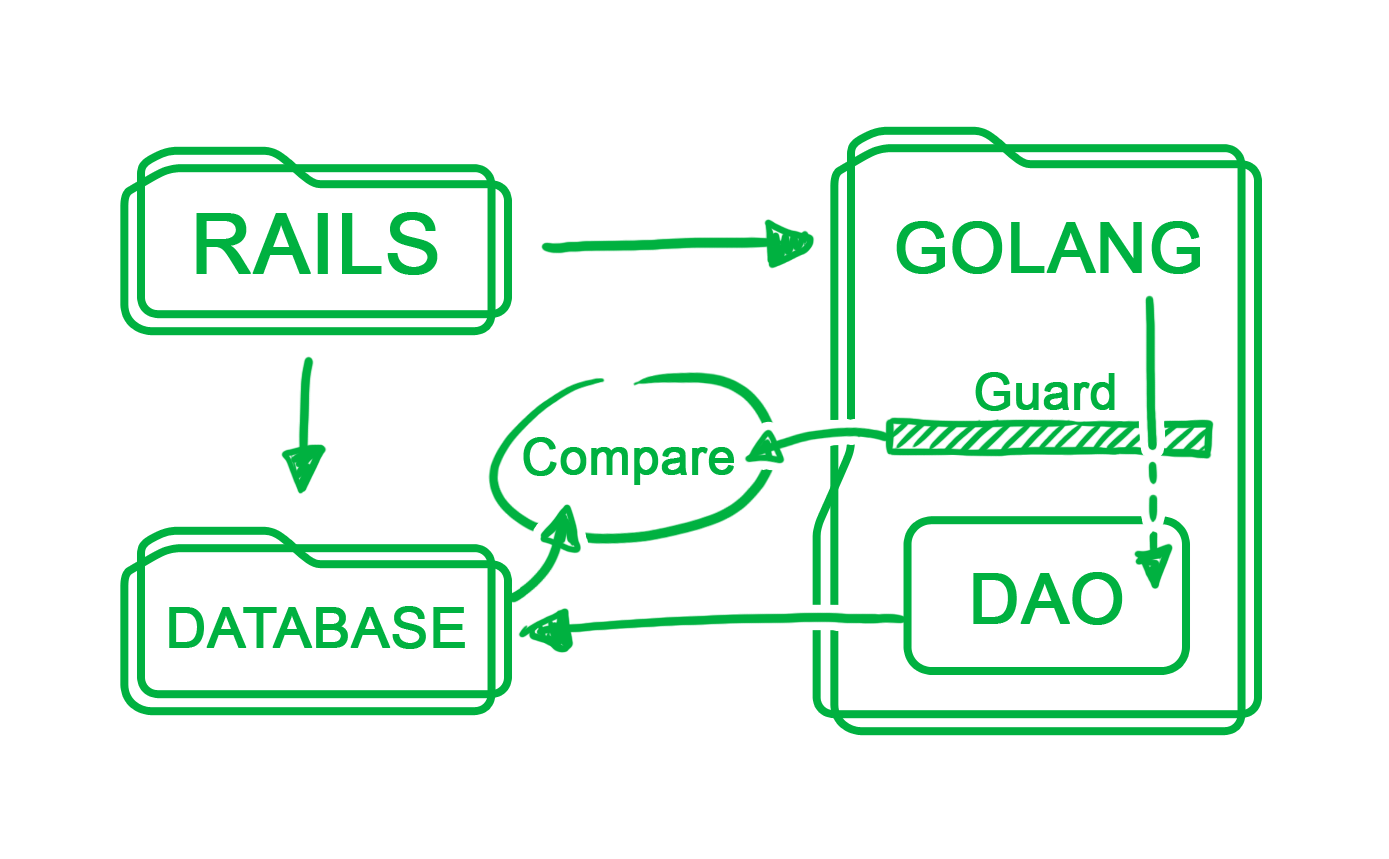 Engineering
EngineeringThis Rocket Ain't Stopping - Achieving Zero Downtime for Rails to Golang API Migration
Grab has been transitioning from a Rails + NodeJS stack to a full Golang Service Oriented Architecture. To contribute to a single common code base, we wanted to transfer engineers working on the Rails server powering our passenger app APIs to other Go teams. -
Engineering
Round-robin in Distributed Systems
While working on Grab's Common Data Service (CDS), there was the need to implement client side load balancing between CDS clients and servers. However, I kept encountering persistent connection issues with Elastic Load Balance (ELB). -
Engineering
Programmers Beware - UX is Not Just for Designers
Perhaps one of the biggest missed opportunities in Tech in recent history is UX. Somehow, UX became the domain of Product Designers and User Interface Designers. While they definitely are the right people to be thinking about web pages, mobile app screens and so on, we've missed a huge part of what we engineers work on every day: SDKs and APIs. -
Engineering
Grab You Some Post-Mortem Reports
Grab adopts a Service-Oriented Architecture (SOA) to rapidly develop and deploy new feature services. One of the drawbacks of such a design is that team members find it hard to help with debugging production issues that inevitably arise in services belonging to other stakeholders. -
Engineering
The Curious Case of the Phantom Instance
Here at the Grab Engineering team, we have built our entire backend stack on top of Amazon Web Services (AWS). Over time, it was inevitable that some habits have started to form when perceiving our backend monitoring statistics.