
Customer Support Workforce Routing
Introduction
With Grab’s wide range of services, we get large volumes of queries a day. Our Customer Support teams address concerns and issues from safety issues to general FAQs. The teams delight our consumers through quick resolutions, resulting from world-class support framework and an efficient workforce routing system.
Our routing workforce system ensures that available resources are efficiently assigned to a request based on the right skillset and deciding factors such as department, country, request priority. Scalability to work across support channels (e.g. voice, chat, or digital) is also another factor considered for routing a request to a particular support specialist.
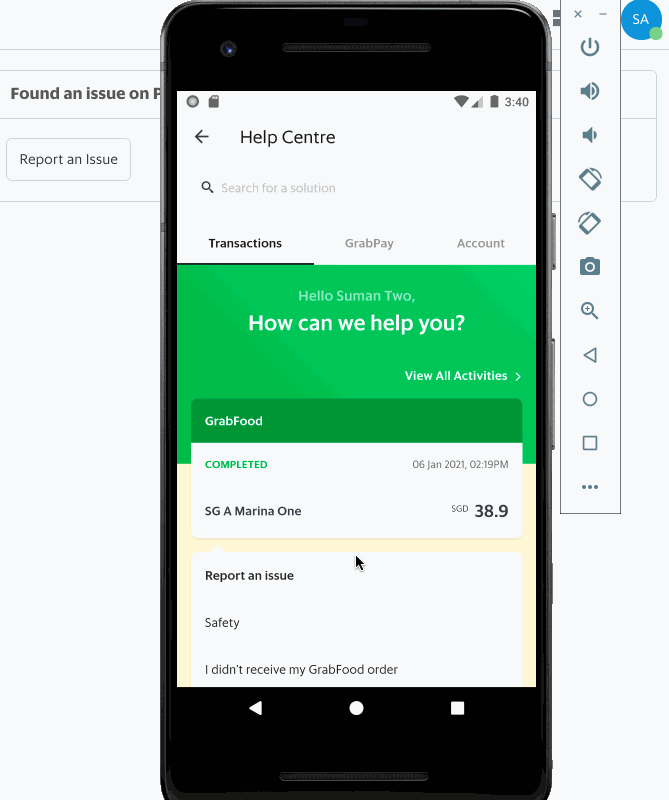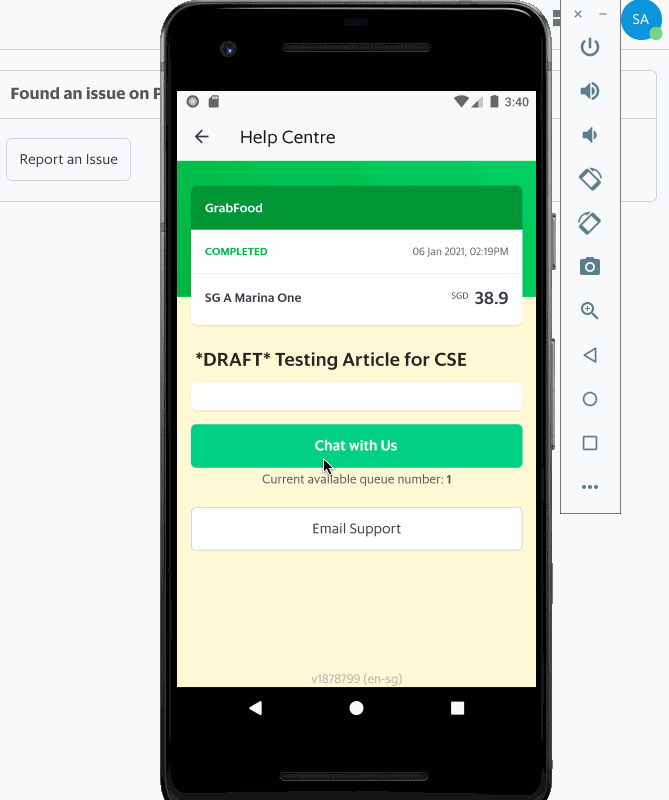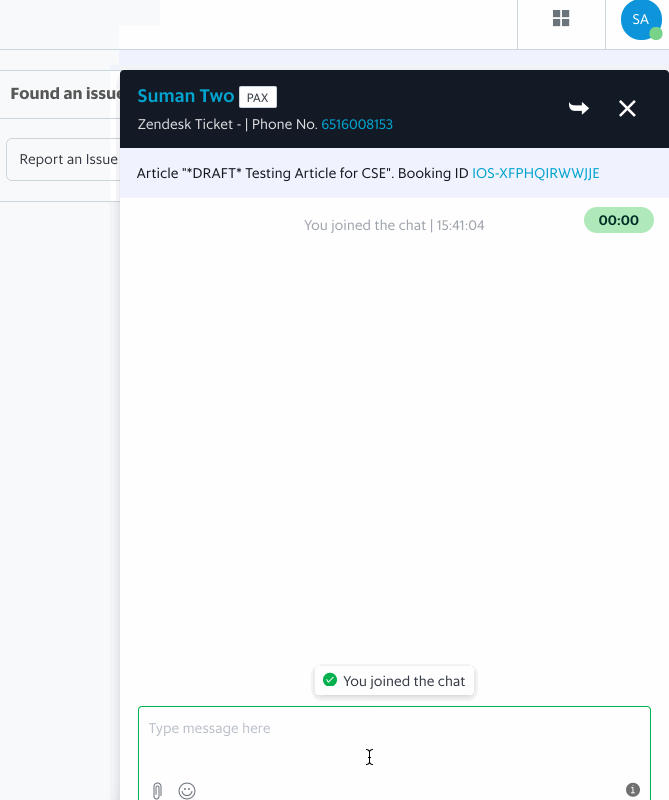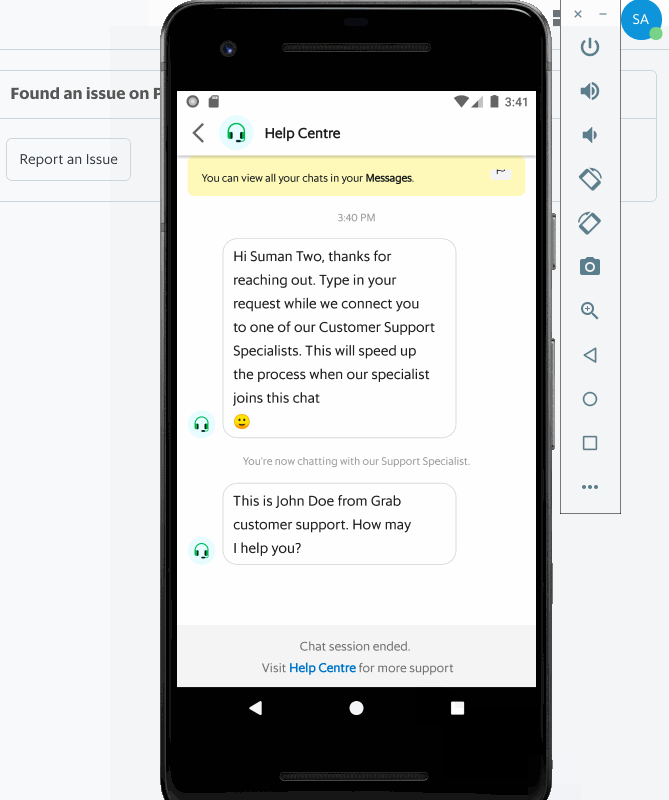
Having an efficient workforce routing system ensures that requests are directed to relevant support specialists who are most suited to handle a certain type of issue, resulting in quicker resolution, happier and satisfied consumers, and reduced cost spent on support.
We initially implemented a third-party solution, however there were a few limitations, such as prioritisation, that motivated us to build our very own routing solution that provides better routing configuration controls and cost reduction from licensing costs.
This article describes how we built our in-house workforce routing system at Grab and focuses on Livechat, one of the domains of consumer support.
Problem
Let’s run through the issues with our previous routing solution in the next sections.
Priority Management
The third-party solution didn’t allow us to prioritise a group of requests over others. This was particularly important for handling safety issues that were not impacted due to other low-priority requests like enquiries. So our goal for the in-house solution was to ensure that we were able to configure the priority of the request queues.
Bespoke Product Customisation
With the third-party solution being a generic service provider, customisations often required long lead times as not all product requests from Grab were well received by the mass market. Building this in-house meant Grab had full controls over the design and configuration over routing. Here are a few sample use cases that were addressed by customisation:
- Bulk configuration changes - Previously, it was challenging to assign the same configuration to multiple agents. So, we introduced another layer of grouping for agents that share the same configuration. For example, which queues the agents receive chats from and what the proficiency and max concurrency should be.
- Resource Constraints - To avoid overwhelming resources with unlimited chats and maintaining reasonable wait times for our consumers, we introduced a dynamic queue limit on the number of chat requests enqueued. This limit was based on factors like the number of incoming chats and the agent performance over the last hour.
- Remote Work Challenges - With the pandemic situation and more of our agents working remotely, network issues were common. So we released an enhancement on the routing system to reroute chats handled by unavailable agents (due to disconnection for an extended period) to another available agent. The seamless experience helped increase consumer satisfaction.
Reporting and Analytics
Similar to previous point, having a solution addressing generic use cases didn’t allow us to add further customisations for monitoring. With the custom implementation, we were able to add more granular metrics that are very useful to assess the agent productivity and performance, which helps in planning the resources ahead of time. This is why reporting and analytics were so valuable for workforce planning. Few of the customisations added additionally were:
- Agent Time Utilisation - While basic agent tracking was available in the out-of-the-box solution, it limited users to three states (online, away, and invisible). With the custom routing solution, we were able to create customised statuses to reflect the time the agent spent in a particular state due to chat connection issues and failures and reflect this on dashboards for immediate attention.
- Chat Transfers - The number of chat transfers could only be tabulated manually. We then automated this process with a custom implementation.
Solution
Now that we’ve covered the issues we’re solving, let’s go over the solutions.
Prioritising High-priority Requests
During routing, the constraint is on the number of resources available. The incoming requests cannot simply be assigned to the first available agent. The issue with this approach is that we would eventually run out of agents to serve the high-priority requests.
One of the ways to prevent this is to have a separate group of agents to solely handle high-priority requests. This does not solve issues as the high-priority requests and low-priority requests share the same queue and are de-queued in a First-In, First-out (FIFO) order. As a result, the low-priority requests are directly processed instead of waiting for the queue to fill up before processing high-priority requests. Because of this queuing issue, prioritisation of requests is critical.
The Need to Prioritise
High-priority requests, such as safety issues, must not be in the queue for a long duration and should be handled as fast as possible even when the system is filled with low-priority requests.
There are two different kinds of queues: one to handle requests at priority level and the other to handle individual issues that are on the business queues on which the queue limit constraints apply.
To illustrate further, here are two different scenarios of enqueuing/de-queuing:
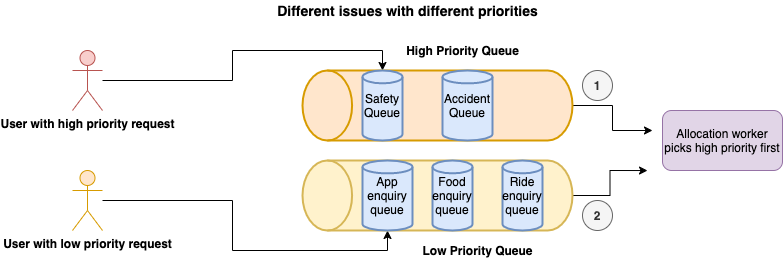
Different Issues with Different Priorities
In this scenario, the priority is set to de-queue safety issues, which are in the high-priority queue, before picking up the enquiry issues from the low-priority queue.
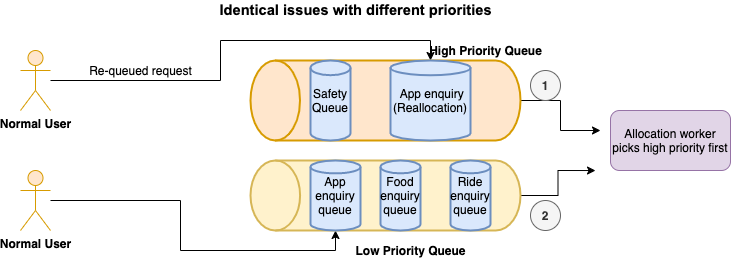
Identical Issues with Different Priorities
In this scenario where identical issues have different priorities, the reallocated enquiry issue in the high-priority queue is de-queued first before picking up a low-priority enquiry issue. Reallocations happen when a chat is transferred to another agent or when it was not accepted by the allocated agent. When reallocated, it goes back to the queue with a higher priority.
Approach
To implement different levels of priorities, we decided to use separate queues for each of the priorities and denoted the request queues by groups, which could logically exist in any of the priority queues.
For de-queueing, time slices of varied lengths were assigned to each of the queues to make sure the de-queueing worker spends more time on a higher priority queue.
The architecture uses multiple de-queueing workers running in parallel, with each worker looping over the queues and waiting for a message in a queue for a certain amount of time, and then allocating it to an agent.
for i := startIndex; i < len(consumer.priorityQueue); i++ {
queue := consumer.priorityQueue[i]
duration := queue.config.ProcessingDurationInMilliseconds
for now := time.Now(); time.Since(now) < time.Duration(duration)*time.Millisecond; {
consumer.processMessage(queue.client, queue.config)
// cool down
time.Sleep(time.Millisecond * 100)
}
}
The above code snippet iterates over individual priority queues and waits for a message for a certain duration, it then processes the message upon receipt. There is also a cooldown period of 100ms before it moves on to receive a message from a different priority queue.
The caveat with the above approach is that the worker may end up spending more time than expected when it receives a message at the end of the waiting duration. We addressed this by having multiple workers running concurrently.
Request Starvation
Now when priority queues are used, there is a possibility that some of the low-priority requests remain unprocessed for long periods of time. To ensure that this doesn’t happen, the workers are forced to run out of sync by tweaking the order in which priority queues are processed, such that when worker1 is processing a high-priority queue request, worker2 is waiting for a request in the medium-priority queue instead of the high-priority queue.
Customising to Our Needs
We wanted to make sure that agents with the adequate skills are assigned to the right queues to handle the requests. On top of that, we wanted to ensure that there is a limit on the number of requests that a queue can accept at a time, guaranteeing that the system isn’t flushed with too many requests, which can lead to longer waiting times for request allocation.
Approach
The queues are configured with a dynamic queue limit, which is the upper limit on the number of requests that a queue can accept. Additionally attributes such as country, department, and skills are defined on the queue.
The dynamic queue limit takes account of the utilisation factor of the queue and the available agents at the given time, which ensures an appropriate waiting time at the queue level.
A simple approach to assign which queues the agents can receive the requests from is to directly assign the queues to the agents. But this leads to another problem to solve, which is to control the number of concurrent chats an agent can handle and define how proficient an agent is at solving a request. Keeping this in mind, it made sense to have another grouping layer between the queue and agent assignment and to define attributes, such as concurrency, to make sure these groups can be reused.
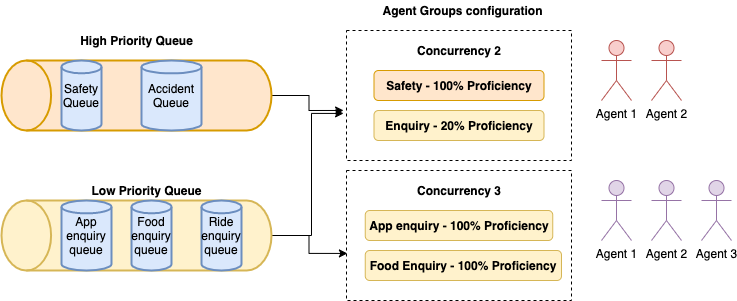
There are three entities in agent assignment:
- Queue
- Agent Group
- Agent
When the request is de-queued, the agent list mapped to the queue is found and then some additional business rules (e.g. proficiency check) are applied to calculate the eligibility score of each mapped agent to decide which agent is the best suited to cater to the request.
The factors impacting the eligibility score are proficiency (whether the agent is online/offline), current concurrency, max concurrency, and last allocation time.
Ensuring the Concurrency is Not Breached
To make sure that the agent doesn’t receive more chats than their defined concurrency, a locking mechanism is used at per agent level. During agent allocation, the worker acquires a lock on the agent record with an expiry, preventing other workers from allocating a chat to this agent. Only once the allocation process is complete (either failed or successful), the concurrency is updated and the lock is released, allowing other workers to assign more chats to the agent depending on the bandwidth.
A similar approach was used to ensure that the queue limit doesn’t exceed the desired limit.
Reallocation and Transfers
Having the routing configuration setup, the reallocation of agents is done using the same steps for agent allocation.
To transfer a chat to another queue, the request goes back to the queue with a higher priority so that the request is assigned faster.
Unaccepted Chats
If the agent fails to accept the request in a given period of time, then the request is put back into the queue, but this time with a higher priority. This is the reason why there’s a corresponding re-allocation queue with a higher priority than the normal queue to make sure that those unaccepted requests don’t have to wait in the queue again.
Informing the Frontend about Allocation
When an allocation of an agent happens, the routing system needs to inform the frontend by sending messages over websocket to the frontend. This is done with our super reliable messaging system called Hermes, which operates at scale in supporting 12k concurrent connections and establishes real-time communication between agents and consumers.
Finding the Online Agents
The routing system should only send the allocation message to the frontend when the agent is online and accepting requests. Frontend uses the same websocket connection used to receive the allocation message to inform the routing system about the availability of agents. This means that if for some reason, the websocket connection is broken due to internet connection issues, the agent would stop receiving any new chat requests.
Enriched Reporting and Analytics
The routing system is able to push monitoring metrics, such as number of online agents, number of chat requests assigned to the agent, and so on. Because of the fine-grained control that comes with building this system in-house, it gives us the ability to push more custom metrics.
There are two levels of monitoring offered by this system: real-time monitoring and non-real time monitoring. They can be used for analytics for calculating things like the productivity of the agent and the time they spent on each chat.
We achieved the discussed solutions with the help of StatsD for real-time monitoring and for analytical purposes. We sent the data used for Tableau visualisations and reporting to Presto tables.
Given that the bottleneck for this system is the number of resources (i.e. number of agents), the real time monitoring helps identify which configuration needs to be adjusted when there is a spike in the number of requests. Moreover, the analytical persistent data allows us the ability to predict the traffic and plan the workforce management such that they are efficiently handling the requests.
Scalability
Letting the system behave appropriately when rolled out to multiple regions is a very critical piece that needed to be taken into account. To ensure that there were enough workers to handle requests, horizontal scaling of instances was set when the CPU utilisation increases.
Now to understand the system limitations and behaviour before releasing to multiple regions, we ran load tests with 10x more traffic than expected. This gave us the understanding on what monitors and alerts we should add to make sure the system is able to function efficiently and reduce our recovery time if something goes wrong.
Next Steps
We have lined up a few enhancements to reduce the consumer wait time and the time spent by the agents on unresponsive consumers. Aside from chats, we plan to implement this solution to handle digital issues (social media and emails) and voice requests (call).
Special thanks to Andrea Carlevato and Karen Kue for making sure that the blogpost is interesting and represents the problem we solved accurately.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!