
Exposing a Kafka Cluster via a VPC Endpoint Service
In large organisations, it is a common practice to isolate the cloud resources of different verticals. Amazon Web Services (AWS) Virtual Private Cloud (VPC) is a convenient way of doing so. At Grab, while our core AWS services reside in a main VPC, a number of Grab Tech Families (TFs) have their own dedicated VPC. One such example is GrabKios. Previously known as “Kudo”, GrabKios was acquired by Grab in 2017 and has always been residing in its own AWS account and dedicated VPC.
In this article, we explore how we exposed an Apache Kafka cluster across multiple Availability Zones (AZs) in Grab’s main VPC, to producers and consumers residing in the GrabKios VPC, via a VPC Endpoint Service. This design is part of Coban unified stream processing platform at Grab.
There are several ways of enabling communication between applications across distinct VPCs; VPC peering is the most straightforward and affordable option. However, it potentially exposes the entire VPC networks to each other, needlessly increasing the attack surface.
Security has always been one of Grab’s top concerns and with Grab’s increasing growth, there is a need to deprecate VPC peering and shift to a method of only exposing services that require remote access. The AWS VPC Endpoint Service allows us to do exactly that for TCP/IPv4 communications within a single AWS region.
Setting up a VPC Endpoint Service compared to VPC peering is already relatively complex. On top of that, we need to expose an Apache Kafka cluster via such an endpoint, which comes with an extra challenge. Apache Kafka requires clients, called producers and consumers, to be able to deterministically establish a TCP connection to all brokers forming the cluster, not just any one of them.
Last but not least, we need a design that optimises performance and cost by limiting data transfer across AZs.
Note: All variable names, port numbers and other details used in this article are only used as examples.
Architecture overview
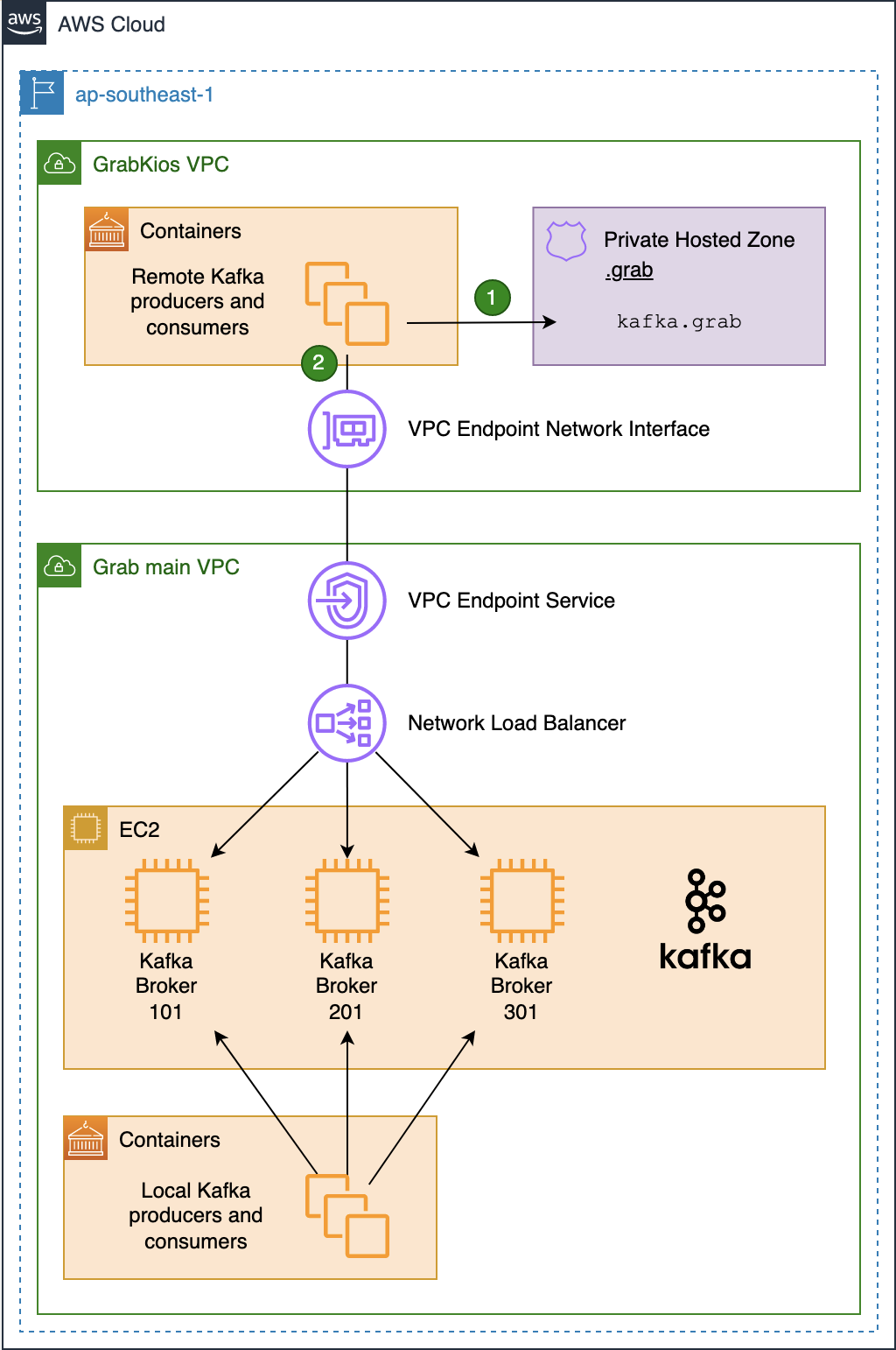
As shown in this diagram, the Kafka cluster resides in the service provider VPC (Grab’s main VPC) while local Kafka producers and consumers reside in the service consumer VPC (GrabKios VPC).
In Grab’s main VPC, we created a Network Load Balancer (NLB) and set it up across all three AZs, enabling cross-zone load balancing. We then created a VPC Endpoint Service associated with that NLB.
Next, we created a VPC Endpoint Network Interface in the GrabKios VPC, also set up across all three AZs, and attached it to the remote VPC endpoint service in Grab’s main VPC. Apart from this, we also created a Route 53 Private Hosted Zone .grab and a CNAME record kafka.grab that points to the VPC Endpoint Network Interface hostname.
Lastly, we configured producers and consumers to use kafka.grab:10000 as their Kafka bootstrap server endpoint, 10000/tcp being an arbitrary port of our choosing. We will explain the significance of these in later sections.
Network Load Balancer setup
On the NLB in Grab’s main VPC, we set up the corresponding bootstrap listener on port 10000/tcp, associated with a target group containing all of the Kafka brokers forming the cluster. But this listener alone is not enough.
As mentioned earlier, Apache Kafka requires producers and consumers to be able to deterministically establish a TCP connection to all brokers. That’s why we created one listener for every broker in the cluster, incrementing the TCP port number for each new listener, so each broker endpoint would have the same name but with different port numbers, e.g. kafka.grab:10001 and kafka.grab:10002.
We then associated each listener with a dedicated target group containing only the targeted Kafka broker, so that remote producers and consumers could differentiate between the brokers by their TCP port number.
The following listeners and associated target groups were set up on the NLB:
10000/tcp(bootstrap) ->9094/tcp@ [broker 101, broker 201, broker 301]10001/tcp->9094/tcp@ [broker 101]10002/tcp->9094/tcp@ [broker 201]10003/tcp->9094/tcp@ [broker 301]
Security Group rules
In the Kafka brokers’ Security Group (SG), we added an ingress SG rule allowing 9094/tcp traffic from each of the three private IP addresses of the NLB. As mentioned earlier, the NLB was set up across all three AZs, with each having its own private IP address.
On the GrabKios VPC (consumer side), we created a new SG and attached it to the VPC Endpoint Network Interface. We also added ingress rules to allow all producers and consumers to connect to tcp/10000-10003.
Kafka setup
Kafka brokers typically come with a listener on port 9092/tcp, advertising the brokers by their private IP addresses. We kept that default listener so that local producers and consumers in Grab’s main VPC could still connect directly.
$ kcat -L -b 10.0.0.1:9092
3 brokers:
broker 101 at 10.0.0.1:9092 (controller)
broker 201 at 10.0.0.2:9092
broker 301 at 10.0.0.3:9092
... truncated output ...
We also configured all brokers with an additional listener on port 9094/tcp that advertises the brokers by:
- Their shared private name
kafka.grab. - Their distinct TCP ports previously set up on the NLB’s dedicated listeners.
$ kcat -L -b 10.0.0.1:9094
3 brokers:
broker 101 at kafka.grab:10001 (controller)
broker 201 at kafka.grab:10002
broker 301 at kafka.grab:10003
... truncated output ...
Note that there is a difference in how the broker’s endpoints are advertised in the two outputs above. The latter enables connection to any particular broker from the GrabKios VPC via the VPC Endpoint Service.
It would definitely be possible to advertise the brokers directly with the remote VPC Endpoint Interface hostname instead of kafka.grab, but relying on such a private name presents at least two advantages.
First, it decouples the Kafka deployment in the service provider VPC from the infrastructure deployment in the service consumer VPC. Second, it makes the Kafka cluster easier to expose to other remote VPCs, should we need it in the future.
Limiting data transfer across Availability Zones
At this stage of the setup, our Kafka cluster is fully reachable from producers and consumers in the GrabKios VPC. Yet, the design is not optimal.
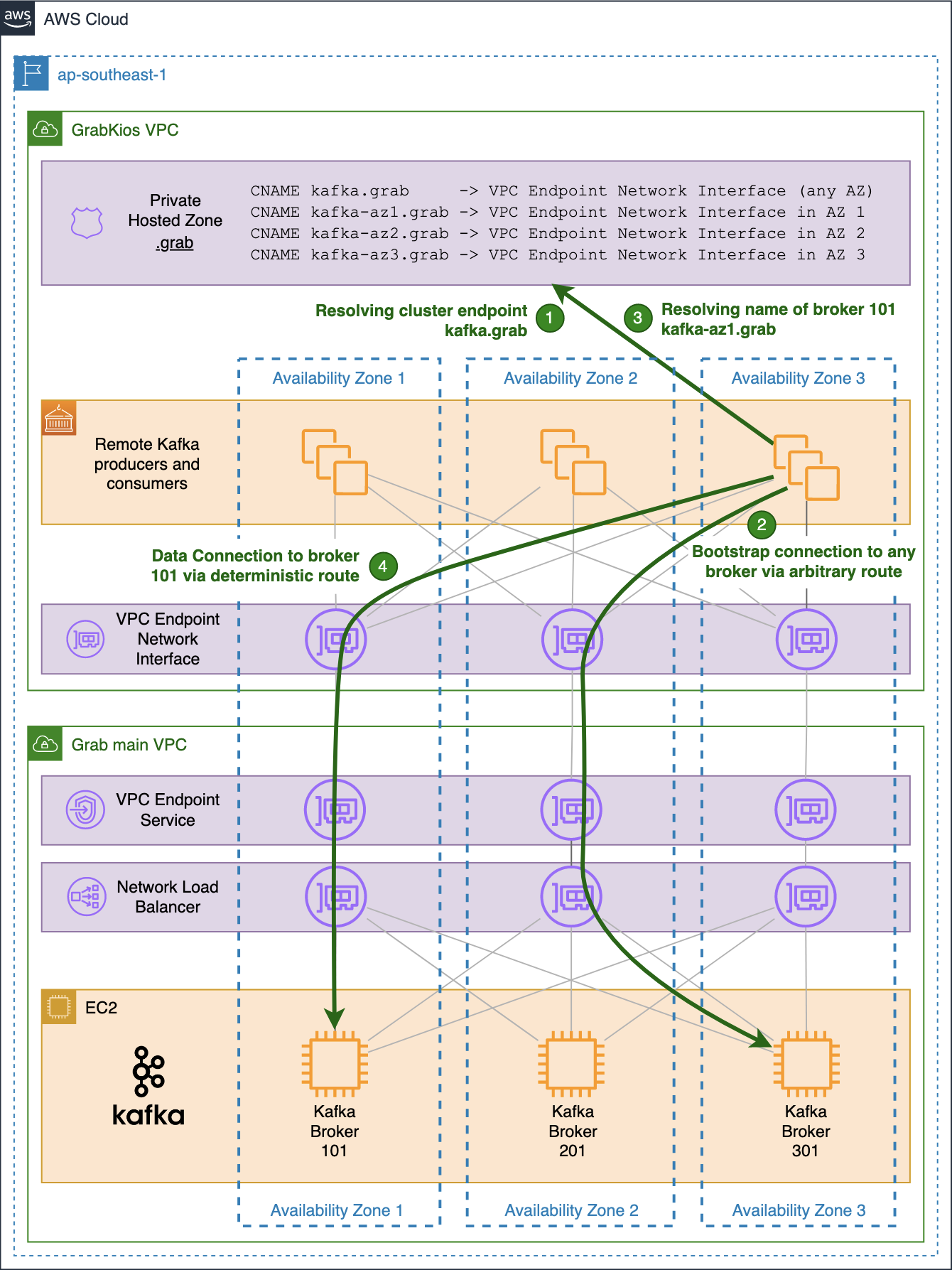
When a producer or a consumer in the GrabKios VPC needs to connect to a particular broker, it uses its individual endpoint made up of the shared name kafka.grab and the broker’s dedicated TCP port.
The shared name arbitrarily resolves into one of the three IP addresses of the VPC Endpoint Network Interface, one for each AZ.
Hence, there is a fair chance that the obtained IP address is neither in the client’s AZ nor in that of the target Kafka broker. The probability of this happening can be as high as 2/3 when both client and broker reside in the same AZ and 1/3 when they do not.
While that is of little concern for the initial bootstrap connection, it becomes a serious drawback for actual data transfer, impacting the performance and incurring unnecessary data transfer cost.
For this reason, we created three additional CNAME records in the Private Hosted Zone in the GrabKios VPC, one for each AZ, with each pointing to the VPC Endpoint Network Interface zonal hostname in the corresponding AZ:
kafka-az1.grabkafka-az2.grabkafka-az3.grab
Note that we used az1, az2, az3 instead of the typical AWS 1a, 1b, 1c suffixes, because the latter’s mapping is not consistent across AWS accounts.
We also reconfigured each Kafka broker in Grab’s main VPC by setting their 9094/tcp listener to advertise brokers by their new zonal private names.
$ kcat -L -b 10.0.0.1:9094
3 brokers:
broker 101 at kafka-az1.grab:10001 (controller)
broker 201 at kafka-az2.grab:10002
broker 301 at kafka-az3.grab:10003
... truncated output ...
Our private zonal names are shared by all brokers in the same AZ while TCP ports remain distinct for each broker. However, this is not clearly shown in the output above because our cluster only counts three brokers, one in each AZ.
The previous common name kafka.grab remains in the GrabKios VPC’s Private Hosted Zone and allows connections to any broker via an arbitrary, likely non-optimal route. GrabKios VPC producers and consumers still use that highly-available endpoint to initiate bootstrap connections to the cluster.
Future improvements
For this setup, scalability is our main challenge. If we add a new broker to this Kafka cluster, we would need to:
- Assign a new TCP port number to it.
- Set up a new dedicated listener on that TCP port on the NLB.
- Configure the newly spun up Kafka broker to advertise its service with the same TCP port number and the private zonal name corresponding to its AZ.
- Add the new broker to the target group of the bootstrap listener on the NLB.
- Update the network SG rules on the service consumer side to allow connections to the newly allocated TCP port.
We rely on Terraform to dynamically deploy all AWS infrastructure and on Jenkins and Ansible to deploy and configure Apache Kafka. There is limited overhead but there are still a few manual actions due to a lack of integration. These include transferring newly allocated TCP ports and their corresponding EC2 instances’ IP addresses to our Ansible inventory, commit them to our codebase and trigger a Jenkins job deploying the new Kafka broker.
Another concern of this setup is that it is only applicable for AWS. As we are aiming to be multi-cloud, we may need to port it to Microsoft Azure and leverage the Azure Private Link service.
In both cases, running Kafka on Kubernetes with the Strimzi operator would be helpful in addressing the scalability challenge and reducing our adherence to one particular cloud provider. We will explain how this solution has helped us address these challenges in a future article.
Special thanks to David Virgil Naranjo whose blog post inspired this work.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!