From firefighting to building: How AI agents restored our team’s core productivity
Abstract
Grab’s Analytics Data Warehouse (ADW) team supports over 1,000 users each month. These users support an extensive repository of more than 15,000 tables, which powers approximately 50% of all queries within our data lake.
However, the manual process of addressing “quick questions” is time-consuming and labor-intensive, thus creating a bottleneck in our operations.
The team was drowning in repetitive requests, spending approximately 40% of their time or an equivalent of roughly 2 days every week, on tasks like:
- Answering the same questions about data definitions
- Tracing data sources and troubleshooting
- Running quality checks to verify data integrity
- Basic enhancement requests
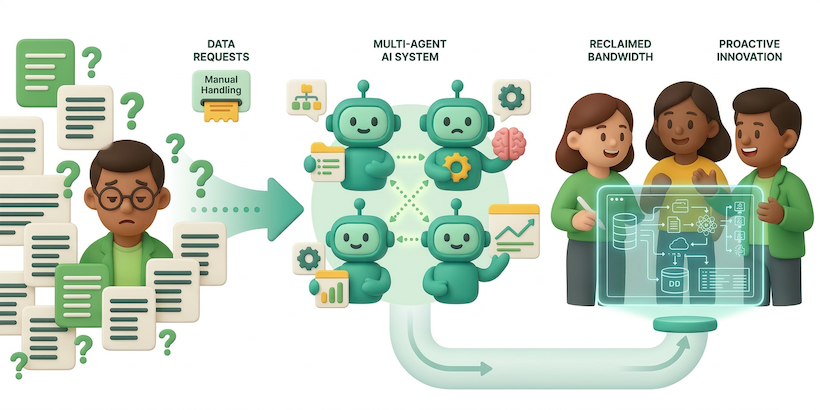
We deployed a multi-agent AI system that autonomously answers simpler questions and collaboratively addresses more complex requests. This led us to reclaim significant engineering bandwidth and unlock hundreds of hours of productivity monthly.
Introduction
It’s 5:00 PM on a Friday. You’re wrapping up for the week when you receive a Slack message: “The vehicle_id in our production table looks gibberish. Is the pipeline broken?”
We tracked the anatomy of these ‘simple’ questions. It involved a fragmented journey through data catalogs, manual lineage tracing, SQL validation, and log diving. By the time a stakeholder received an answer, hours of high-value engineering time had been diverted into investigative overhead.
This process consumed nearly half of our team’s bandwidth. We recognized that while problems differed, the process of solving them was consistent. This led us to build a multi-agent AI system to automate the context hunt, allowing engineers to focus on complex challenges.
Solution
Tech stack
- FastAPI & LangGraph: We use FastAPI to handle requests and LangGraph to manage the complex state and cyclical logic required for multi-agent collaboration. Unlike simple Large Language Model (LLM) calls, LangGraph allows our agents to loop back, ask for more information, or hand off tasks to one another.
- Redis & PostgreSQL: Redis handles our caching and real-time session needs, while PostgreSQL serves as the persistent memory, storing conversation history and agent metadata.
- Hubble: A centralized metadata management platform and data catalog.
- Genchi: A data quality observability platform that enforces data contracts.
- Lighthouse: A platform that tracks execution status and monitors pipeline health.
From request to resolution
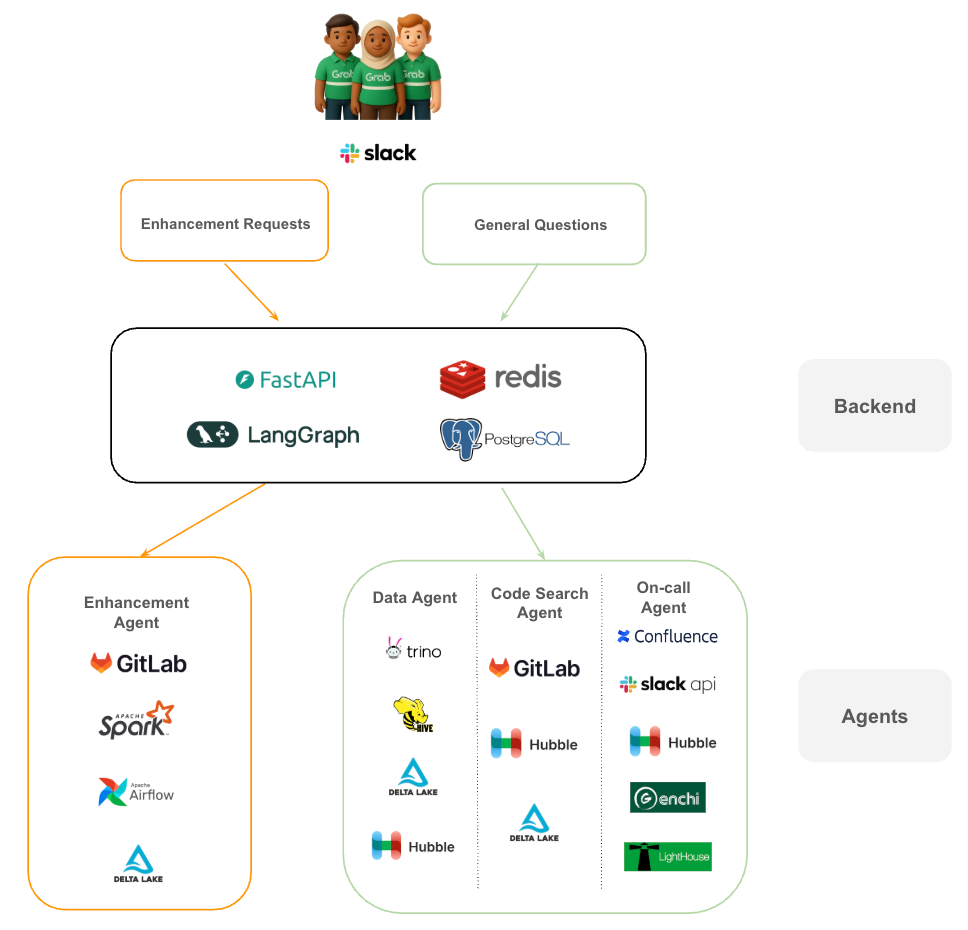
The journey begins in Slack. When a user submits a request, it is categorized into one of two streams:
- Enhancement requests: These are routed to the Enhancement Agent, which interacts directly with our core engineering tools like GitLab, Apache Spark, and Airflow to propose and test code changes.
- General questions: These are funneled through our investigation pathway. The system orchestrates a “huddle” between the Data Agent (querying Trino, Hive, or Delta Lake), the Code Search Agent (analyzing GitLab), and the On-call Agent (checking Confluence and Slack for ongoing incidents).
By decoupling the “brain” (the LLM) from the “hands” (the specialized agents and tools), we created a system that is both capable and easy to debug.
Why specialized agents beat a single “Super AI”
We could have built one massive AI trained to handle every question, but specialized agents are easier to build, maintain, and improve than a monolithic system.
The table below illustrates the comparison between a single AI system and a multi-agent system:
| Approach | Advantages | Challenges |
|---|---|---|
| Single AI (Monolithic) | One model to maintain, single inference call | Hard to debug, changes affect everything, generalist performance |
| Multi-Agent System | Focused expertise, modular updates, specialist accuracy | Sequential execution adds latency, coordination complexity |
We chose the multi-agent approach because maintainability and accuracy mattered more than shaving off a few seconds of latency. When you’re replacing a multi-hour manual investigation, taking a few minutes for a precise answer is a massive leap in operational throughput.
The architecture: Two pathways, five specialized agents
When a question arrives through Slack, the system first determines which pathway to take:
- Pathway 1: Enhancement Requests → Enhancement Agent (handles code changes)
- Pathway 2: Investigation Questions → Classifier → Specialized agents → Summarizer
Enhancement pathway: Semi-Automated code changes
For requests like “Can you add a new column for customer_segment?” or “We need to change the aggregation logic for revenue”, the Enhancement Agent handles the heavy lifting.
Enhancement Agent receives user requirements and proposes code changes:
- Gathers context: schema, lineage, dependencies, existing codebase.
- Generates code changes and creates a merge request (MR).
- Runs changes in a test environment.
- Flags governance concerns (Personally Identifiable Information (PII) classification, Service Level Agreements (SLAs), backward compatibility).
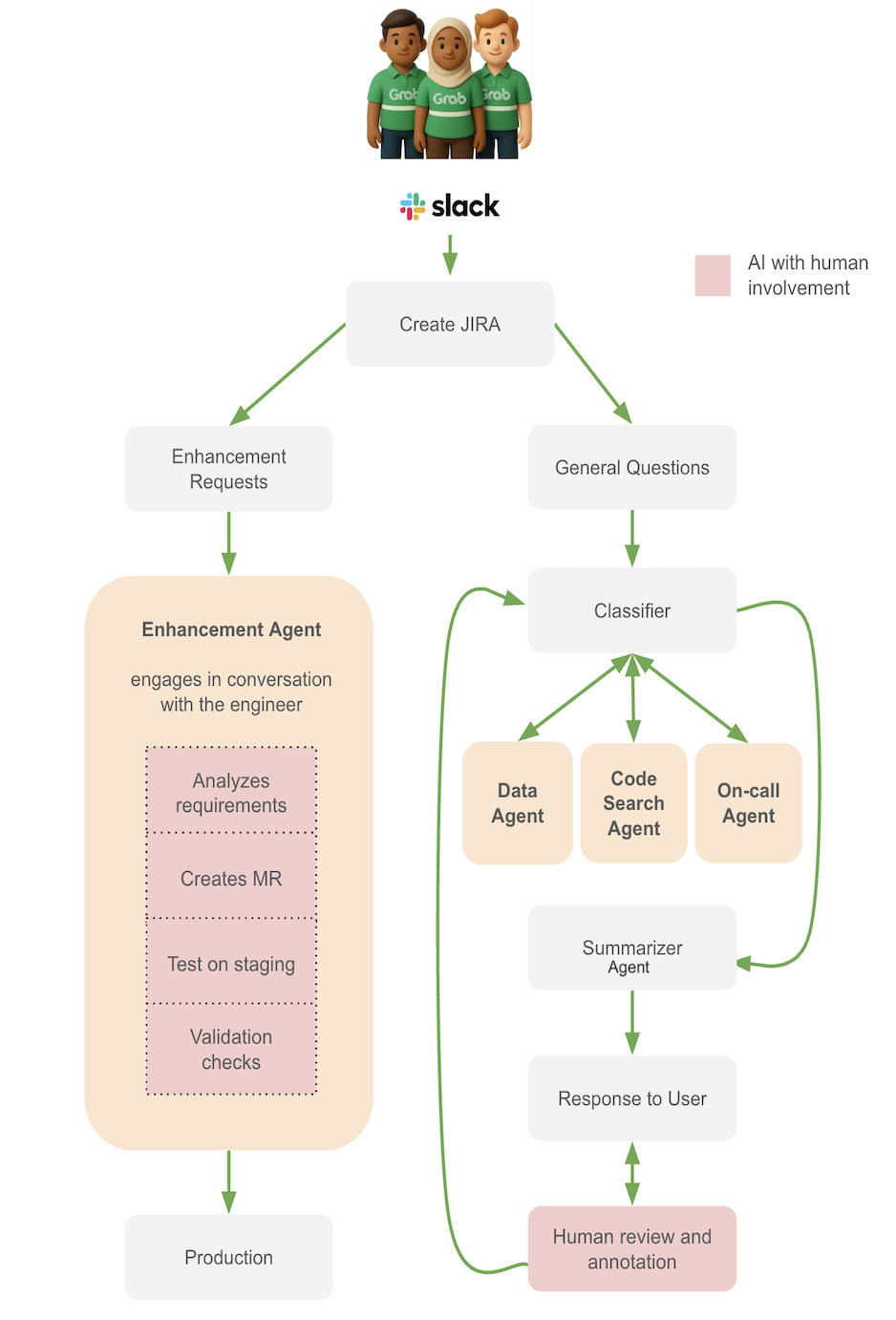
The workflow:
- User creates a JIRA request.
- Agent analyzes requirements and gathers context through interactive dialogue with the engineer.
- Agent creates an MR with suggested code.
- Engineer reviews the MR.
- If valid, agent runs changes in test environment.
- Engineer reviews results against test cases.
- If tests pass, engineer merges the MR.
Why is the workflow semi-automated by design? Code changes to production pipelines require human judgment. The agent accelerates the process by doing the research, writing the code, and running tests, but humans make the final approval.
Investigation pathway: Four agents working together
For questions like “Why does this data look wrong?” or “Where does this metric come from?”, the system uses a coordinated team of specialists.
The Classifier is the first responder for investigation questions. It:
- Parses the question to extract key information (tables, scripts, specific data requests).
- Detects guardrail violations (PII requests, out-of-scope queries).
- Determines which specialist agents are needed and in what sequence.
- Provides reasoning and task descriptions for each recommended agent.
Example: For the question “Why does this ID look wrong?”, the Classifier routes the question to: Data Agent → Code Search Agent → On-call Agent (if needed).
Data Agent performs the data investigation:
- Enhances the prompt’s context with the table and column metadata.
- Executes queries with guardrails (PII detection, command validation).
- Validates schemas to avoid unnecessary scans and hallucinations.
- Retrieves sample data with LLM exploratory comments.
Example: It queries vehicle_id from the table to validate the user’s observation against the actual data.
Code Search Agent analyzes the code:
- Traces column transformations through the codebase.
- Follows table lineage through multiple transformation steps.
- Generates plain-language explanations of transformation logic.
- Highlights divergences from documentation or stakeholder expectations.
Example: It can trace a vehicle_id column from the final table back through 5 transformation steps to the original source, explaining each change along the way.
On-call Agent monitors production systems and assists with urgent issues:
- Searches Slack channels for announcements about outages, source table failures, and delays.
- Checks observability platforms for pipeline health, logs, and retry policies.
- Validates data quality metrics (null counts, duplicates, range validation).
- Produces incident notes and initial Root Cause Analysis (RCA) when issues are identified.
Example: If the Data Agent detects SLA breaches or missing partitions, it may consult the On-call Agent for production context.
Summarizer Agent refines responses from the previous agents:
- Handles conflicting information.
- Combines responses into a coherent narrative.
- Makes the answer concise and structured.
- Ensures consistency across agent findings.
Generating the summary is the final step before human review.
Seeing the system in action
The best way to understand how this multi-agent system works is to see it handle real scenarios. Let’s walk through two common situations our team faces daily.
Scenario 1: Adding a new column
The request: A stakeholder raises a JIRA ticket requesting, “Please add a customer_segment column to the rides table. Source data is available in the user_profiles table.”
In the traditional workflow, a data engineer would spend a significant portion of their afternoon clarifying requirements, developing and testing code, similar to the workflow steps in “Figure 2: Agent workflows”.
With the Enhancement Agent, the entire process is completed autonomously in minutes. The agent performs these tasks in sequence:
- Read the JIRA ticket: Agent fetches the ticket details to understand the exact requirements: what column needs to be added, which table is involved, and where the source data comes from.
- Discover the relevant code: Using intelligent search capabilities, it locates the specific pipeline files in our codebase that need modification. It navigates through the repository structure to find the right transformation scripts.
- Run validation checks: Before making any changes, it validates:
- The requested column exists in the upstream source table.
- The column doesn’t already exist in the target table.
- Schema compatibility and data quality requirements are met.
- Generate database schema changes: The agent references existing Data Definition Language (DDL) scripts to understand the standard format, then automatically generates the necessary schema modification scripts. These scripts are added to the MR alongside the code changes.
- Create the MR: All changes, including code modifications and schema scripts, are packaged into an MR with proper documentation, making it ready for review.
- Enable pipeline execution: Once the MR is validated, users can interact with the bot to trigger the data pipeline and start testing their changes on Airflow. They can optionally specify date ranges or other parameters to control the test runs.
The entire process, from ticket to deployable MR, completes autonomously in minutes, with full traceability at every step.
Scenario 2: Investigating faulty-looking data
The question: “Why is the ID in the vehicles table unreadable?”
Traditionally, the data engineer typically performs these steps:
- Search through various data catalogs to locate relevant information.
- Manually track the data’s origin and transformation path.
- Validate SQL queries.
- Examine logs.
This is how it looks with agents:
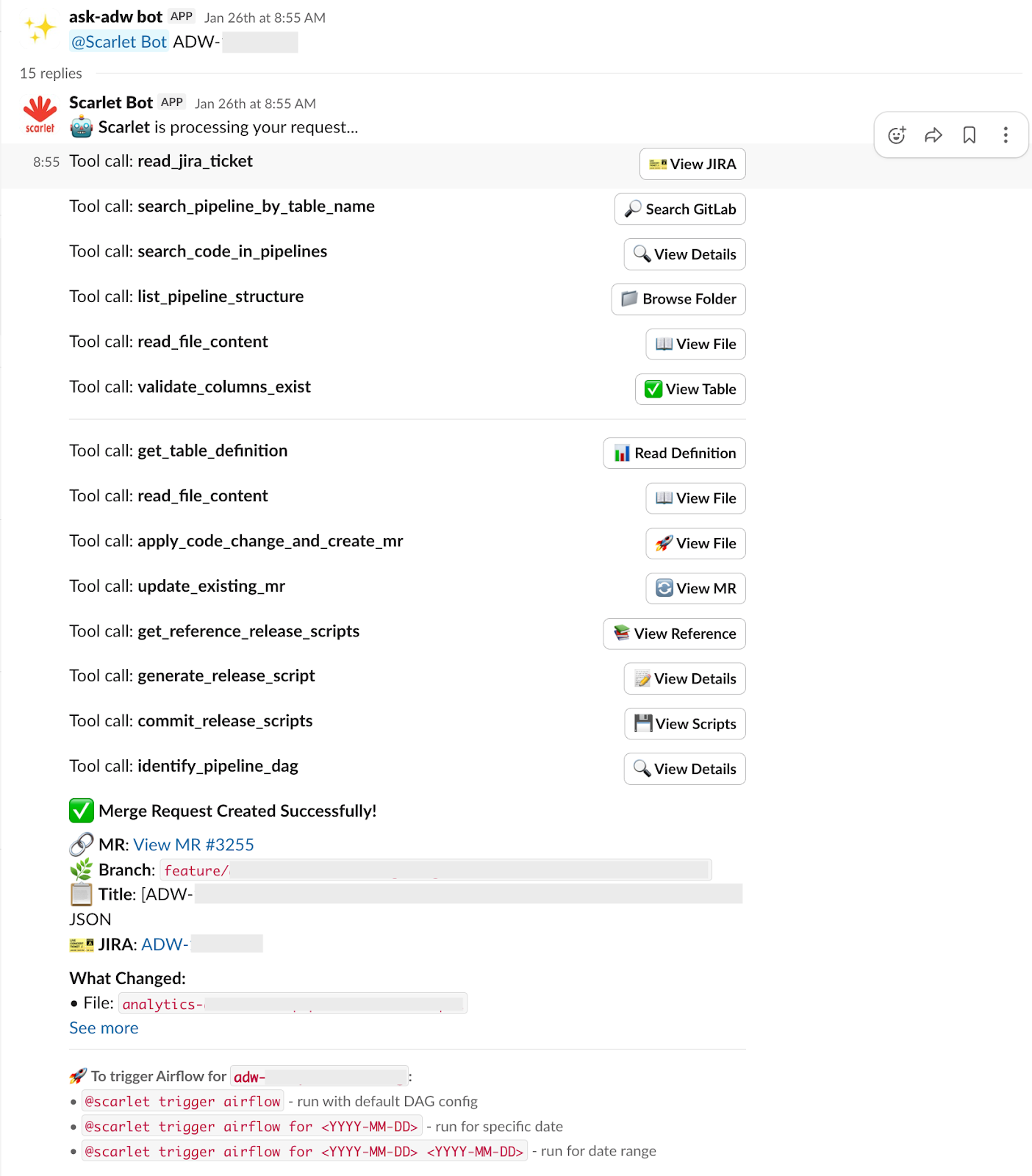
Step 1: Classifier analyzes the question
- Parses the question: determines all three specialist agents are needed.
- Plans the sequence: Data Agent → Code Search Agent → On-call Agent
- Provides reasoning: “Need to verify data format, trace transformation logic, and check for production incidents”.
Step 2: Data Agent investigates
- Retrieves metadata, which helps in building a SQL query for exploring samples.
- Queries actual data. The result confirms the user’s observation with the actual sample and identifies that IDs appear in Universally Unique Identifier (UUID) format, and they’re “unreadable”.
- Searches Grab’s data catalog to find dimension tables that can help decipher UUID in a more human-readable format.
- Finds an appropriate dimension table and builds a join query to test readability.
Conclusion from Data Agent: “The ID column contains UUID format values. These can be joined with dim_vehicles table to get human-readable vehicle names. The format is consistent and valid—not corrupted data.”

Step 3: Code Search Agent traces lineage
- Scans the transformation and lineage logic in the codebase to see exactly how the ID is extracted. It discovers that the ID is a raw UUID from a JSON payload directly from the source system.
- Queries the source table for samples directly. The “unreadable” text pattern matches the data in the vehicles table, confirming that it is not a bug introduced by Spark transformations.
Conclusion from Code Search Agent: “The ‘unreadable’ UUID format comes directly from the source system. No transformation is applied. This is not a bug introduced by our Spark pipelines—it’s the native format from the upstream system”.

Step 4: On-call Agent checks production health
- Checks Airflow pipeline status.
- Searches Slack channels for incidents.
- Checks data quality metrics.
Conclusion from On-call Agent: “No production incidents detected. Pipeline running successfully. Data quality metrics are within normal ranges. No recent complaints or issues reported in communication channels.”

Step 5: Summarizer Agent synthesizes the answer
- User concern: ID values appear “unreadable”.
- Data Agent finding: IDs are valid UUIDs, can be joined with dim_vehicles for readable names.
- Code Search finding: UUID format comes directly from source system, not a transformation bug.
- On-call finding: No production issues, pipeline healthy, data quality normal.
Provides a structured answer to: “Why is the ID in the vehicles table unreadable?”
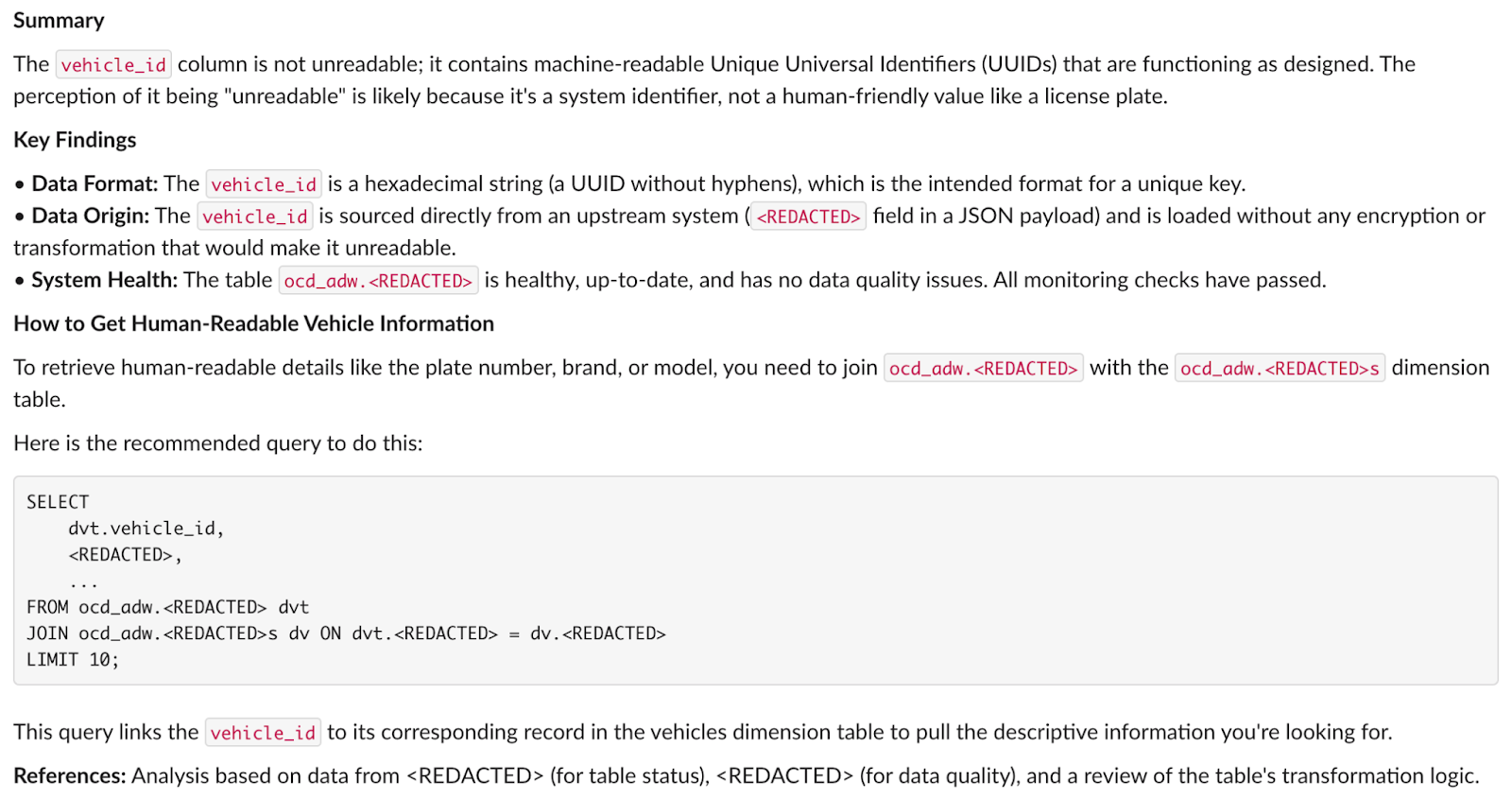
Step 6: Human review and delivery
We publish answers to Slack immediately and mark them as unreviewed. This provides users with quick responses while they await an engineer’s review.
The initial response time has been reduced to just a few minutes, in contrast to the previous hours-long manual search.
Step 7: Continue conversation
After an answer is posted, anyone can engage in a continued conversation with the agents, restarting the loop.

Optimizing the architecture
Building the system was one challenge. Making it production-ready was another.
Our initial prototype worked in controlled demos, but real-world usage revealed critical gaps. Users asked complex questions, conversations grew long, and edge cases exposed vulnerabilities. Here’s how we optimized the system to handle production demands while maintaining accuracy and safety.
Challenge 1: Excessive context
In multi-agent systems, context accumulates fast. Information is continuously passed from one agent to the next. Without careful management, excessive context and tokens cause performance degradation.
Our solution:
The orchestrator maintains a rich state throughout execution, tracking three critical elements:
- Conversation and tooling history: Full message context for each agent.
- Execution tracking: Which agents have run, current progress, and execution steps.
- Agent responses: Structured responses from each agent, passed to subsequent agents.
This state is carefully managed to ensure each agent has the right context without overwhelming token limits.
- Token tracking: Every message is counted using tiktoken, giving us real-time visibility into our token budget.
- Intelligent summarization: When token limits are exceeded, earlier messages are automatically summarized while retaining information relevant to the original question. Recent messages and critical context remain unsummarized to preserve accuracy.
- Retrieval-Augmented Generation (RAG) context pruning: We reduce context from tool outputs when enhancing prompts:
- Instead of passing full code files to the Code Search Agent, we use smaller LLM models to extract the most relevant code snippets and a short description.
- For database queries, we apply filters to retrieve only the top relevant results.
- Handoffs Pattern: The previous agent returns its response to a central orchestrator. The orchestrator cleans the context, prunes unnecessary tokens, and invokes the next agent.
The result:
Agents can handle extended investigations without drowning in excessive context, maintaining performance even in complex, multi-turn conversations.
Challenge 2: Excessive tool usage
Our initial design presented a significant performance bottleneck due to excessive context. Early models were equipped with a large and unwieldy set of over 30 distinct tools, each structured similarly to a generic API. Since tool calling is part of an agent’s prompt, agents had to process verbose tool descriptions and outputs, which degraded efficiency.
Our solution:
We focused on tool design based on real-world usage scenarios:
- Included only the relevant portions required for decision-making.
- Aggressively truncated verbose information from tool outputs.
- Streamlined tool descriptions to be concise and actionable.
The result:
By significantly reducing the data load agents needed to process during inference, we achieved a substantial leap in system responsiveness and throughput.
Challenge 3: Risky code executions
AI agents with database access and code generation capabilities pose significant risks. Without proper safeguards, they could access sensitive PII data, execute dangerous SQL operations, run expensive queries, or generate breaking code changes. We needed to make the system safe.
Our solution: We implemented multiple layers of safety to protect against misuse from both agents and users:
Layer 1: Input classification
Before any agent executes, the Classifier detects:
- PII requests: Questions asking for personally identifiable information
- Out-of-scope queries: Requests beyond the agent’s capabilities
Layer 2: SQL validation before execution
The Data Agent validates every query for:
- PII column access: Checks against column metadata to ensure it doesn’t access confidential information.
- Data definition and manipulation language (DDL/DML) operations: The agent doesn’t have access to DELETE, DROP, TRUNCATE, or UPDATE operations, but this check acts as an additional safeguard.
- Slow queries: Detects missing partition filters or excessive date ranges that could cause expensive full-table scans.
- Schema validation: Confirms tables and columns exist before execution.
Layer 3: Timeout protection
All database queries have strict execution limits to prevent runaway queries from impacting system performance.
Layer 4: Enhancement agent controls
For the Enhancement Agent, which generates code changes:
- Cannot commit to master/main directly: All changes go through MRs.
- Mandatory human review: A human reviewer must validate all inputs before execution.
- Test environment first: Changes run in staging before production deployment.
The result: A safe environment where AI agents can operate in production without compromising security or stability. Users and engineers trust the system because they know it has robust guardrails protecting critical data and systems.
Challenge 4: Ensuring user trust
Even with RAG and guardrails, AI agents aren’t perfect. Hallucinations, misinterpretations, and edge cases could erode user trust.
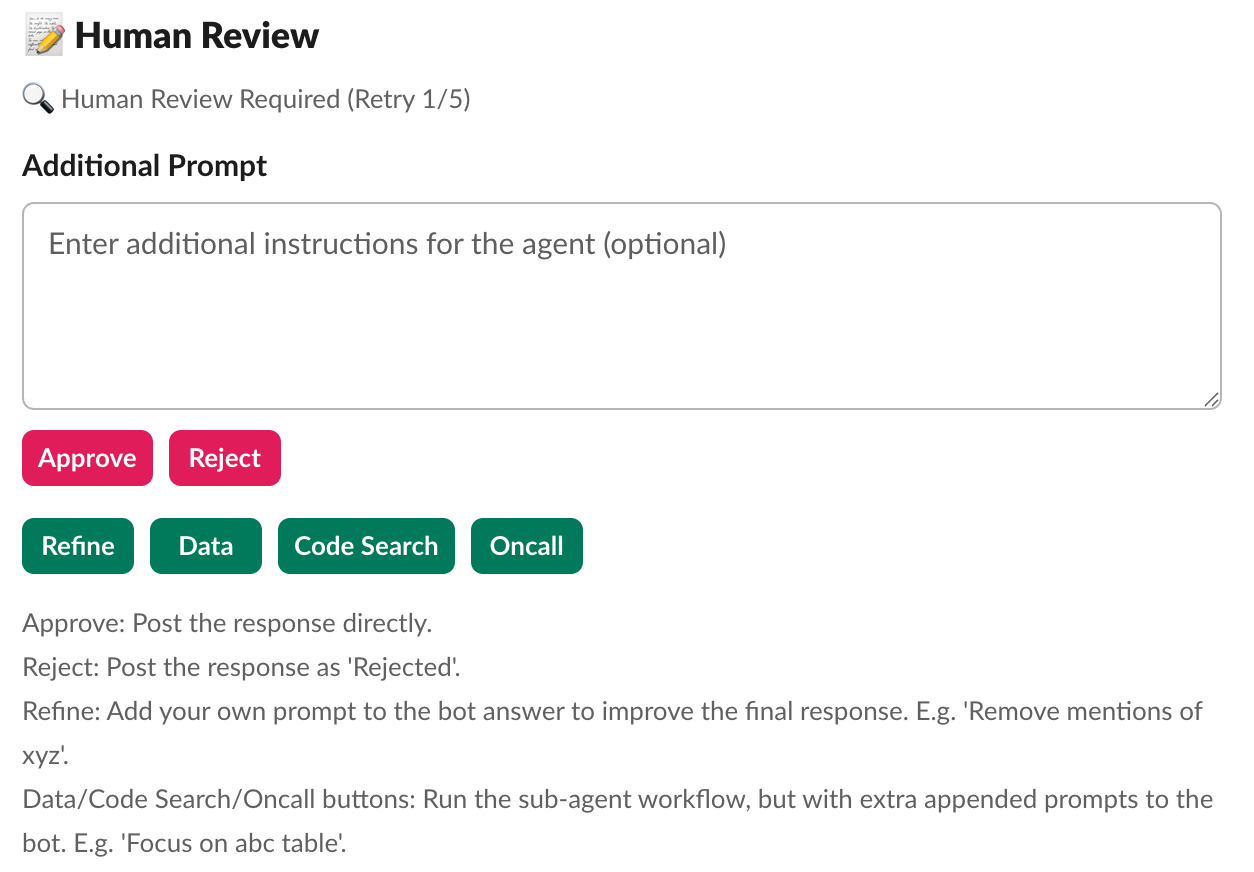
Our solution: After generating a summarized response, the multi-agent system routes to human reviewers who can take five actions:
- Approve: Post the response as-is and add a footnote that the response has been deemed accurate by a human reviewer.
- Reject: Mark the response as incorrect and log it for improvement. The response will not be posted, protecting users from bad information.
- Refine: Add a prompt to improve the summarized response from the sub-agents. The system regenerates the answer with additional guidance.
- Re-route to Sub-Agents: Send the question to a specific agent with additional context. For example: “Data Agent, can you check the last 30 days instead of 7 days?”
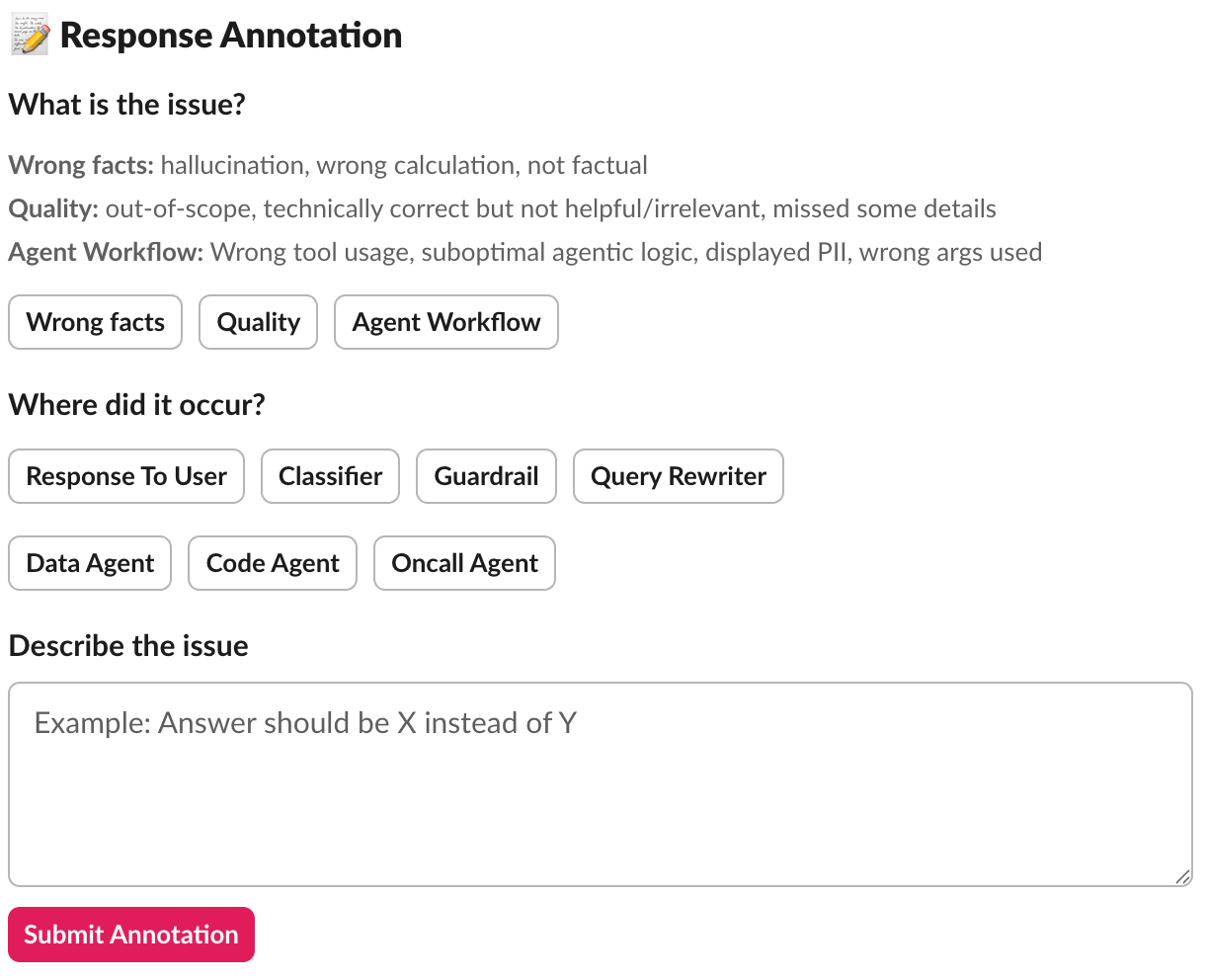
- Annotate: Provide structured feedback to the response, where it gets saved to a database for continuous improvement.
The result:
This human-in-the-loop model ensures answers are accurate and reliable, increasing user trust in the responses. The annotations help us iteratively improve the model’s future responses.
Challenge 5: Balancing speed and quality
Our initial design withheld AI-generated responses until authorized by an engineering team member. This introduced a bottleneck in the response process, potentially leaving inquiries unresolved for extended periods, particularly during peak workload times.
Our solution: We redesigned the process to allow responses to be posted without immediate human review, provided they are clearly and prominently marked as unreviewed. All posts can still be reviewed and modified by the on-call engineer as needed, but users get answers immediately rather than waiting.
The result: This approach maintains a crucial balance between response speed and quality:
- Users get fast answers when they need them.
- Transparency (unreviewed label) sets appropriate expectations.
- Engineers still review all responses to catch errors and improve the system.
- Feedback loop remains intact for continuous learning.
Challenge 6: Closing the feedback loop
Collecting feedback through annotations was just the first step. Without systematic analysis, we had a goldmine of information about what worked and what didn’t, but we weren’t learning from it. Every rejected response was a lesson unlearned, every annotation a pattern unrecognized. We needed to close the loop.
Our solution:
We transformed annotations from passive records into an active improvement engine through five mechanisms:
- Automated evaluation: Random annotations are pulled to create test cases for offline evaluation. This ensures the system is tested against real-world failure scenarios, not just synthetic test cases we invented.
- Pattern analysis: We analyze annotations to identify systemic issues:
- Is the Classifier consistently routing to the wrong agents?
- Does a specific agent have quality issues?
- Are certain types of queries prone to hallucinations?
- Do particular table schemas cause confusion?
- Quality metrics: Tracking annotation rates over time measures system reliability and identifies regression. If the rejection rate suddenly increases, we know something has changed that needs investigation.
- Targeted improvements: Annotations guide where to focus development effort:
- Improving prompts: Refining agent system prompts with better examples.
- Adding guardrails: Enhancing input classification to catch problematic queries earlier.
- Enhancing specific agents: Adding examples or tools to handle struggling query types.
- Training data: Annotated failures can be used to:
- Fine-tune models on domain-specific patterns.
- Improve few-shot examples in prompts.
- Build regression test suites from actual failures.
The result: The system transformed from static to continuous learning. Every mistake became an opportunity for improvement, and the system got smarter with each interaction. We had data-driven insights guiding our optimization priorities, ensuring we focused on the highest-impact improvements.
Impact
The deployment of this multi-agent system yielded transformative results across key performance indicators, shifting the team’s entire operational dynamic.
- Automated resolution:The bots now autonomously handle the majority of standard user inquiries and a significant portion of common enhancement requests.
- Velocity gains: The time required to resolve issues has seen an order-of-magnitude reduction, effectively eliminating the support backlog. Simple inquiries are autonomously answered and brought to a resolution within minutes.
- Productivity gains: The team has successfully reclaimed several full-time equivalents (FTE) worth of engineering bandwidth, shifting hundreds of hours from reactive support to proactive roadmap delivery.
With this newfound capacity unlocked, the data engineering team pivots from reactive support to proactive, high-value work, ultimately leading to “happier downstream users.”
Conclusions
Our journey from overwhelmed data engineers to a team empowered by AI agents revealed three core principles that made this transformation possible:
Multi-Agent architecture: Specialists over generalists
Specialized AI agents outperform a single generalist by mastering specific domains (e.g., data quality, code analysis). This modularity allows for independent improvement, easy additions, and clear responsibilities, boosting maintainability and flexibility.
Strategic human oversight: Building trust through transparency
Routing AI responses through human reviewers achieved rapid adoption via trust and continuous system improvement by generating annotated training feedback.
Focus on augmentation: Automating repetitive tasks
AI agents operate autonomously in repetitive tasks (context gathering, running queries, checking logs) with human oversight if needed, and collaborate with us in augmenting higher-value work: architectural decisions and building new capabilities.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility, and digital financial services sectors. Serving over 900 cities in eight Southeast Asian countries: Cambodia, Indonesia, Malaysia, Myanmar, the Philippines, Singapore, Thailand, and Vietnam. Grab enables millions of people every day to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. We operate supermarkets in Malaysia under Jaya Grocer and Everrise, which enables us to bring the convenience of on-demand grocery delivery to more consumers in the country. As part of our financial services offerings, we also provide digital banking services through GXS Bank in Singapore and GXBank in Malaysia. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line. We aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!