
Graph for fraud detection
In earlier articles of this series, we’ve covered the importance of graph networks, graph concepts and how graph visualisation makes fraud investigations easier and more effective. In this article, we will explore how we use graph-based models to tackle fraud detection as fraud patterns increase and diversify.
Grab has grown rapidly in the past few years. It has expanded its business from ride hailing to food and grocery delivery, financial services, and more. Fraud detection is challenging in Grab, because new fraud patterns always arise whenever we introduce a new business product. We cannot afford to develop a new model whenever a new fraud pattern appears as it is time consuming and introduces a cold start problem, that is no protection at the early stage. We need a general fraud detection framework to better protect Grab from various unknown fraud risks.
Our key observation is that although Grab has many different business verticals, the entities within those businesses are connected to each other (Figure 1. Left), for example, two passengers may be connected by a Wi-Fi router or phone device, a merchant may be connected to a passenger by a food order, and so on. A graph provides an elegant way to capture the spatial correlation among different entities in the Grab ecosystem. A common fraud shows clear patterns on a graph, for example, a fraud syndicate tends to share physical devices, and collusion happens between a merchant and an isolated set of passengers (Figure 1. Right).
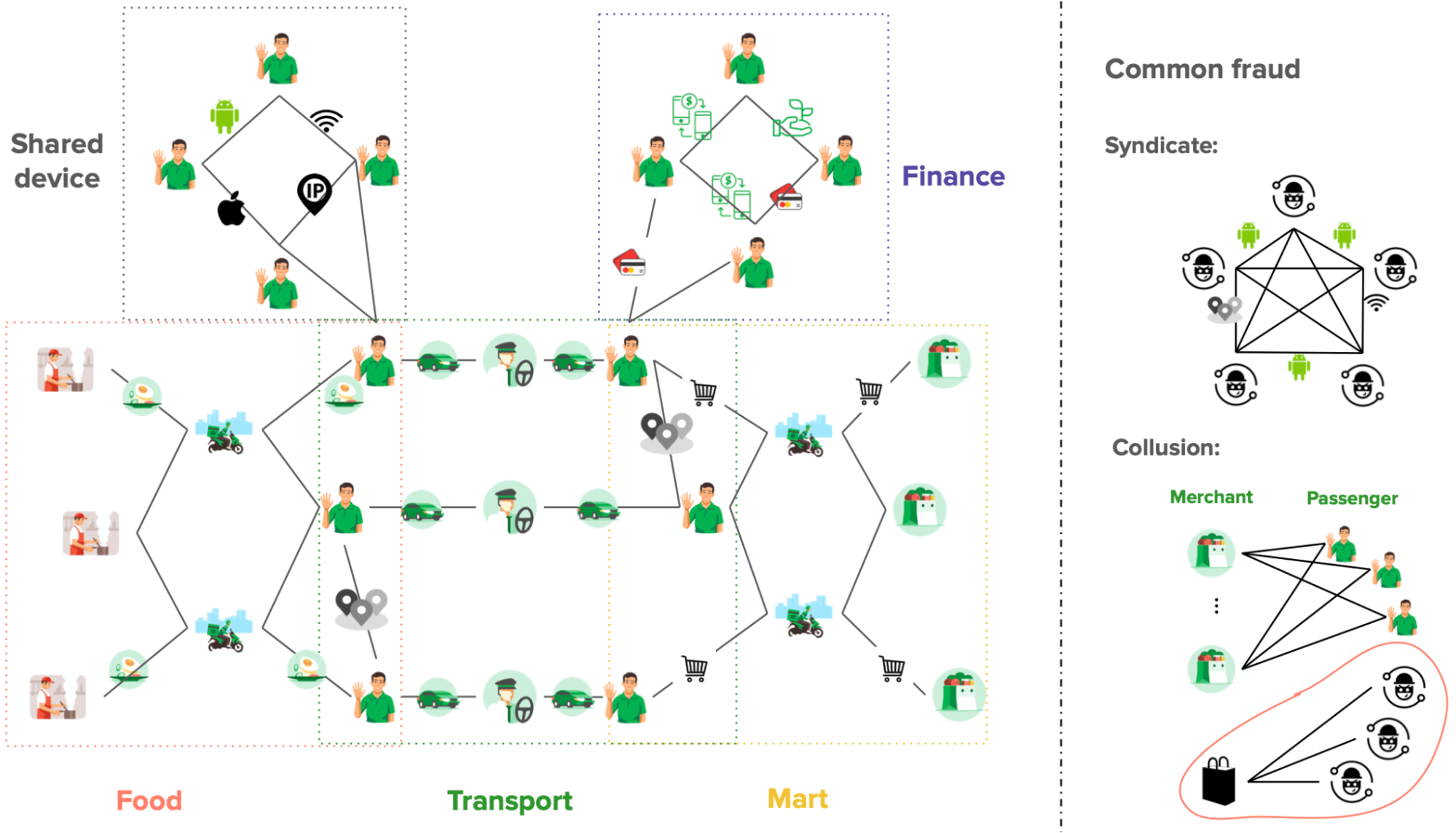
Right: The graph shows that common fraud has clear patterns.
We believe graphs can help us discover subtle traces and complicated fraud patterns more effectively. Graph-based solutions will be a sustainable foundation for us to fight against known and unknown fraud risks.
Why graph?
The most common fraud detection methods include the rule engine and the decision tree-based models, for example, boosted tree, random forest, and so on. Rules are a set of simple logical expressions designed by human experts to target a particular fraud problem. They are good for simple fraud detection, but they usually do not work well in complicated fraud or unknown fraud cases.
| Fraud detection methods |
Utilises correlations (Higher is better) |
Detects unknown fraud (Higher is better) |
Requires feature engineering (Lower is better) |
Depends on labels (Lower is better) |
|---|---|---|---|---|
| Rule engine | Low | N/A | N/A | Low |
| Decision tree | Low | Low | High | High |
| Graph model | High | High | Low | Low |
Table 1. Graph vs. common fraud detection methods.
Decision tree-based models have been dominating fraud detection and Kaggle competitions for structured or tabular data in the past few years. With that said, the performance of a tree-based model is highly dependent on the quality of labels and feature engineering, which is often hard to obtain in real life. In addition, it usually does not work well in unknown fraud which has not been seen in the labels.
On the other hand, a graph-based model requires little amount of feature engineering and it is applicable to unknown fraud detection with less dependence on labels, because it utilises the structural correlations on the graph.
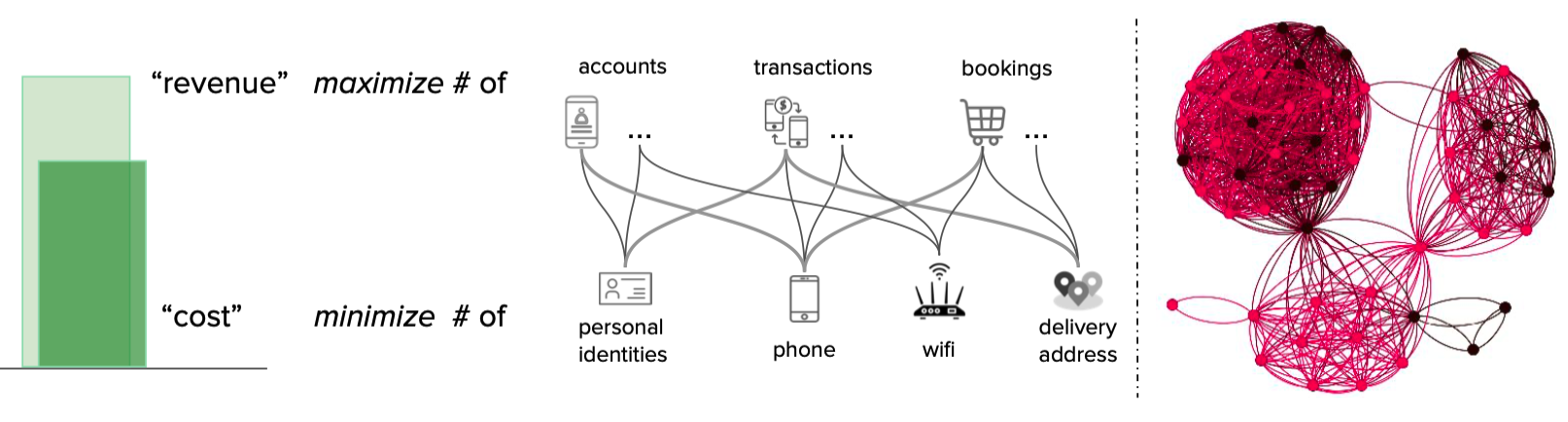
In particular, fraudsters tend to show strong correlations on a graph, because they have to share physical properties such as personal identities, phone devices, Wi-Fi routers, delivery addresses, and so on, to reduce cost and maximise revenue as shown in Figure 2 (left). An example of such strong correlations is shown in Figure 2 (right), where the entities on the graph are densely connected, and the known fraudsters are highlighted in red. Those strong correlations on the graph are the key reasons that make the graph based approach a sustainable foundation for various fraud detection tasks.
Semi-supervised graph learning
Unlike traditional decision tree-based models, the graph-based machine learning model can utilise the graph’s correlations and achieve great performance even with few labels. The semi-supervised Graph Convolutional Network model has been extremely popular in recent years 1. It has proven its success in many fraud detection tasks across industries, for example, e-commerce fraud, financial fraud, internet traffic fraud, etc. We apply the Relational Graph Convolutional Network (RGCN) 2 for fraud detection in Grab’s ecosystem. Figure 3 shows the overall architecture of RGCN. It takes a graph as input, and the graph passes through several graph convolutional layers to get node embeddings. The final layer outputs a fraud probability for each node. At each graph convolutional layer, the information is propagated along the neighbourhood nodes within the graph, that is nodes that are close on the graph are similar to each other.
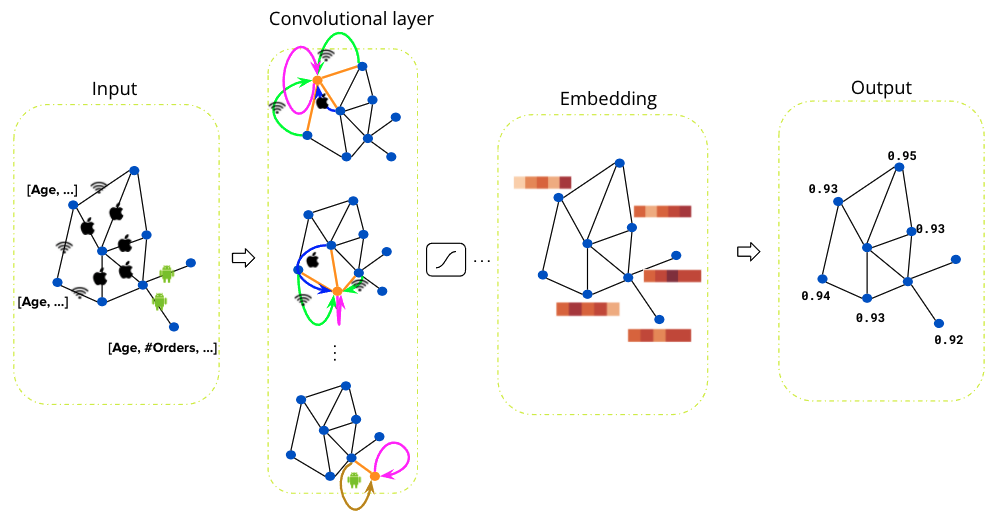
We train the RGCN model on a graph with millions of nodes and edges, where only a few percentages of the nodes on the graph have labels. The semi-supervised graph model has little dependency on the labels, which makes it a robust model for tackling various types of unknown fraud.
Figure 4 shows the overall performance of the RGCN model. On the left is the Receiver Operating Characteristic (ROC) curve on the label dataset, in particular, the Area Under the Receiver Operating Characteristic (AUROC) value is close to 1, which means the RGCN model can fit the label data quite well. The right column shows the low dimensional projections of the node embeddings on the label dataset. It is clear that the embeddings of the genuine passenger are well separated from the embeddings of the fraud passenger. The model can distinguish between a fraud and a genuine passenger quite well.
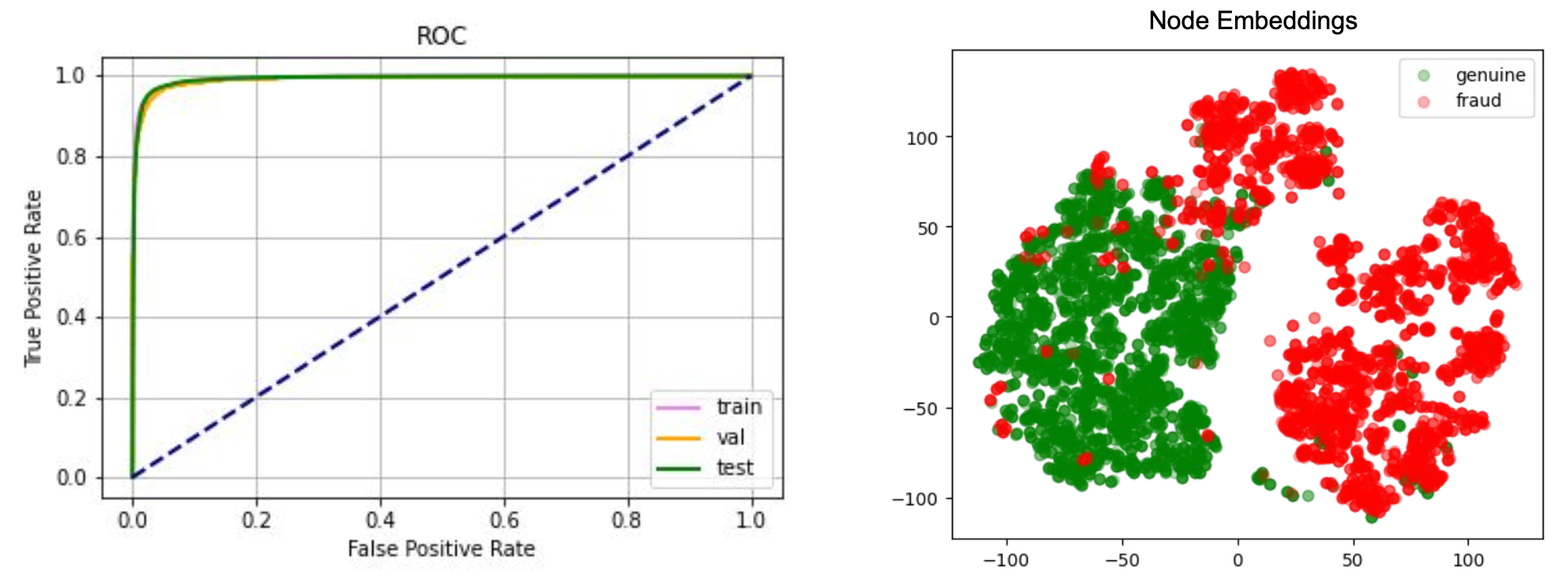
Right: Low dimensional projections of the graph node embeddings.
Finally, we would like to share a few tips that will make the RGCN model work well in practice.
- Use less than three convolutional layers: The node feature will be over-smoothed if there are many convolutional layers, that is all the nodes on the graph look similar.
- Node features are important: Domain knowledge of the node can be formulated as node features for the graph model, and rich node features are likely to boost the model performance.
Graph explainability
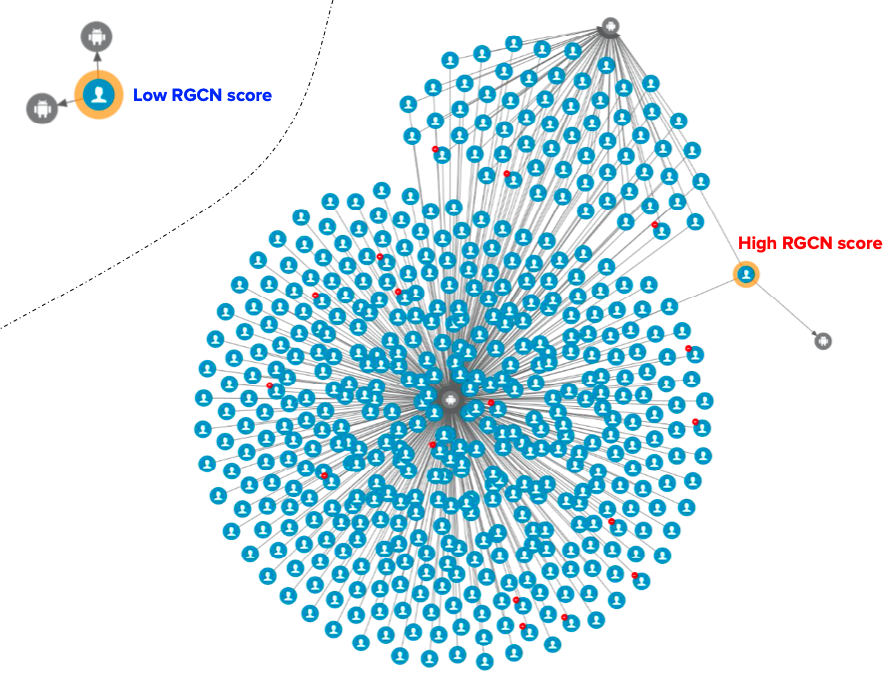
Unlike other deep network models, graph neural network models usually come with great explainability, that is why a user is classified as fraudulent. For example, fraudulent accounts are likely to share hardware devices and form dense clusters on the graph, and those fraud clusters can be easily spotted on a graph visualiser 3.
Figure 5 shows an example where graph visualisation helps to explain the model prediction scores. The genuine passenger with a low RGCN score does not share devices with other passengers, while the fraudulent passenger with a high RGCN score shares devices with many other passengers, that is, dense clusters.
Closing thoughts
Graphs provide a sustainable foundation for combating many different types of fraud risks. Fraudsters are evolving very fast these days, and the best traditional rules or models can do is to chase after those fraudsters given that a fraud pattern has already been discovered. This is suboptimal as the damage has already been done on the platform. With the help of graph models, we can potentially detect those fraudsters before any fraudulent activity has been conducted, thus reducing the fraud cost.
The graph structural information can significantly boost the model performance without much dependence on labels, which is often hard to get and might have a large bias in fraud detection tasks. We have shown that with only a small percentage of labelled nodes on the graph, our model can already achieve great performance.
With that said, there are also many challenges to making a graph model work well in practice. We are working towards solving the following challenges we are facing.
- Feature initialisation: Sometimes, it is hard to initialise the node feature, for example, a device node does not carry many semantic meanings. We have explored self-supervised pre-training 4 to help the feature initialisation, and the preliminary results are promising.
- Real-time model prediction: Realtime graph model prediction is challenging because real-time graph updating is a heavy operation in most cases. One possible solution is to do batch real-time prediction to reduce the overhead.
- Noisy connections: Some connections on the graph are inherently noisy on the graph, for example, two users sharing the same IP address does not necessarily mean they are physically connected. The IP might come from a mobile network. One possible solution is to use the attention mechanism in the graph convolutional kernel and control the message passing based on the type of connection and node profiles.
Speak to us
GrabDefence is a proprietary fraud prevention platform built by Grab, Southeast Asia’s leading superapp. Since 2019, the GrabDefence team has shared its fraud management capabilities and platform with enterprises and startups to leverage Grab’s advanced AI/ML models, hyper local insights and patented device intelligence technologies.
To learn more about GrabDefence or to speak to our fraud management experts, contact us at gd.contact@grabtaxi.com.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
References
-
T. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in ICLR, 2017 ↩
-
Schlichtkrull, Michael, et al. “Modeling relational data with graph convolutional networks.” European semantic web conference. Springer, Cham, 2018. ↩
-
Fujiao Liu, Shuqi Wang, et al.. “Graph Networks - 10X investigation with Graph Visualisations”. Grab Tech Blog. ↩
-
Wang, Chen, et al.. “Deep Fraud Detection on Non-attributed Graph.” IEEE Big Data conference, PSBD, 2021. ↩