How Grab is Blazing Through the Superapp Bazel Migration
Introduction
At Grab, we build a seamless user experience that addresses more and more of the daily lifestyle needs of people across Southeast Asia. We’re proud of our Grab rides, payments, and delivery services, and want to provide a unified experience across these offerings.
Here are a couple of examples of what Grab does for millions of people across Southeast Asia every day:

The Grab Passenger application reached superapp status more than a year ago and continues to provide hundreds of life-changing use cases in dozens of areas for millions of users.
With the big product scale, it brings with it even bigger technical challenges. Here are a couple of dimensions that can give you a sense of the scale we’re working with.
Engineering and Product Structure
Technical and product teams work in close collaboration to outserve our consumers. These teams are combined into dedicated groups to form Tech Families and focus on similar use cases and areas.
Grab consists of many Tech Families who work on food, payments, transport, and other services, which are supported by hundreds of engineers. The diverse landscape makes the development process complicated and requires the industry’s best practices and approaches.
Codebase Scale Overview
The Passenger Applications (Android and iOS) contain more than 2.5 million lines of code each and it keeps growing. We have 1000+ modules in the Android app and 700+ targets in the iOS app. Hundreds of commits are merged by all the mobile engineers on a daily basis.
To maintain the health of the codebase and product stability, we run 40K+ unit tests on Android and 30K+ unit tests on iOS, as well as thousands of UI tests and hundreds of end-to-end tests on both platforms.
Build Time Challenges
The described complexity and scale do not come without challenges. A huge codebase propels the build process to the ultimate extreme- challenging the efficiency of build systems and hardware used to compile the superapp, and creating out of the line challenges to be addressed.
Local Build Time
Local build time (the build on engineers’ laptop) is one of the most obvious challenges. More code goes in the application binary, hence the build system requires more time to compile it.
ADR Local Build Time
The Android ecosystem provides a great out-of-the-box tool to build your project called Gradle. It’s flexible and user friendly, and provides huge capabilities for a reasonable cost. But is this always true? It appears to not be the case due to multiple reasons. Let’s unpack these reasons below.
Gradle performs well for medium sized projects with say 1 million line of code. Once the code surpasses that 1 million mark (or so), Gradle starts failing in giving engineers a reasonable build time for the given flexibility. And that’s exactly what we have observed in our Android application.
At some point in time, the Android local build became ridiculously long. We even encountered cases where engineers’ laptops simply failed to build the project due to hardware resources limits. Clean builds took by the hours, and incremental builds easily hit dozens of minutes.
iOS Local Build Time
Xcode behaved a bit better compared to Gradle. The Xcode build cache was somehow bearable for incremental builds and didn’t exceed a couple of minutes. Clean builds still took dozens of minutes though. When Xcode failed to provide the valid cache, engineers had to rerun everything as a clean build, which killed the experience entirely.
CI Pipeline Time
Each time an engineer submits a Merge Request (MR), our CI kicks in running a wide variety of jobs to ensure the commit is valid and doesn’t introduce regression to the master branch. The feedback loop time is critical here as well, and the pipeline time tends to skyrocket alongside the code base growth. We found ourselves on the trend where the feedback loop came in by the hours, which again was just breaking the engineering experience, and prevented us from delivering the world’s best features to our consumers.
As mentioned, we have a large number of unit tests (30K-40K+) and UI tests (700+) that we run on a pre-merge pipeline. This brings us to hours of execution time before we could actually allow MRs to land to the master branch.
The number of daily commits, which is by the hundreds, adds another stone to the basket of challenges.
All this clearly indicated the area of improvement. We were missing opportunities in terms of engineering productivity.
The Extra Mile
The biggest question for us to answer was how to put all this scale into a reasonable experience with minimal engineering idle time and fast feedback loop.
Build Time Critical Path Optimisation
The most reasonable thing to do was to pay attention to the utilisation of the hardware resources and make the build process optimal.
This literally boiled down to the simplest approach:
- Decouple building blocks
- Make building blocks as small as possible
This approach is valid for any build system and applies for both iOS and Android. The first thing we focused on was to understand what our build graph looked like, how dependencies were distributed, and which blocks were bottlenecks.
Given the scale of the apps, it’s practically not possible to manage a dependency tree manually, thus we created a tool to help us.
Critical Path Overview
We introduced the Critical Path concept:
The critical path is the longest (time) chain of sequential dependencies, which must be built one after the other.
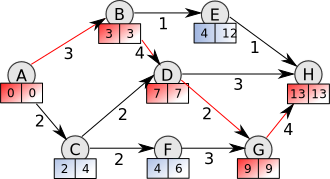
Even with an infinite number of parallel processors/cores, the total build time cannot be less than the critical path time.
We implemented the tool that parsed the dependency trees (for both Android and iOS), aggregated modules/target build time, and calculated the critical path.
The concept of the critical path introduced a number of action items, which we prioritised:
- The critical path must be as short as possible.
- Any huge module/target on the critical path must be split into smaller modules/targets.
- Depend on interfaces/bridges rather than implementations to shorten the critical path.
- The presence of other teams’ implementation modules/targets in the critical path of the given team is a red flag.
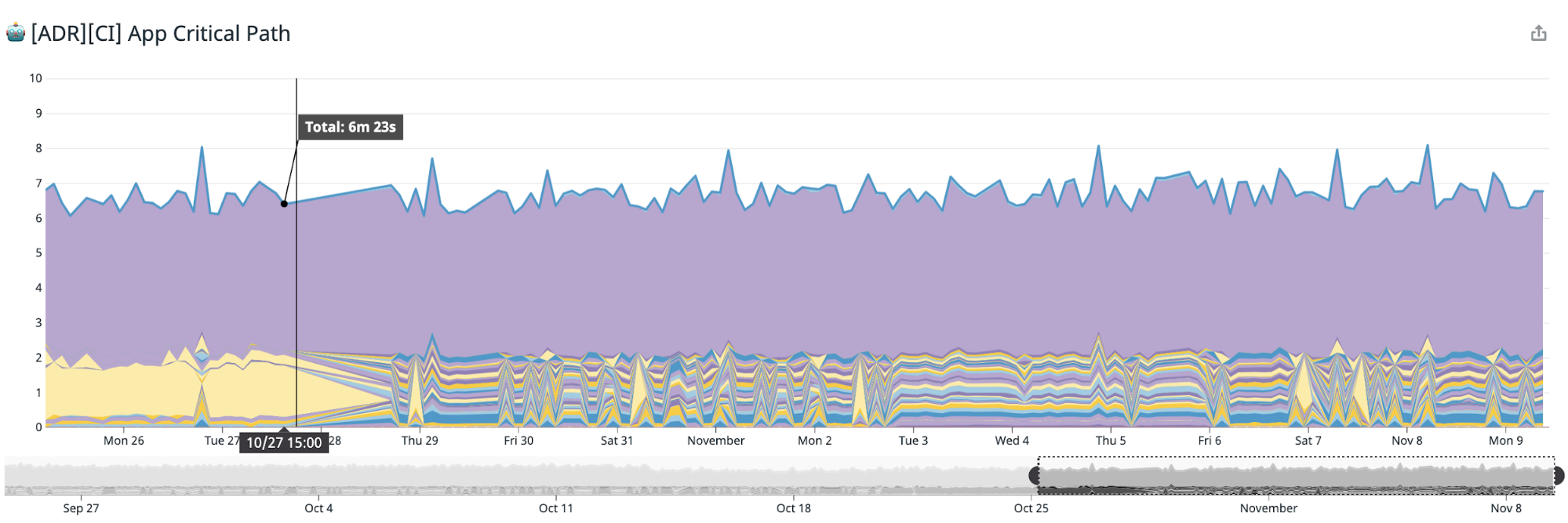
Project’s Scale Factor
To implement the conceptually easy action items, we ran a Grab-wide program. The programme has impacted almost every mobile team at Grab and involved 200+ engineers to some degree. The whole implementation took 6 months to complete.
During this period of time, we assigned engineers who were responsible to review the changes, provide support to the engineers across Grab, and monitor the results.
Results
Even though the overall plan seemed to be good on paper, the results were minimal - it just flattened the build time curve of the upcoming trend introduced by the growth of the codebase. The estimated impact was almost the same for both platforms and gave us about a 7%-10% cut in the CI and local build time.
Open Source Plan
The critical path tool proved to be effective to illustrate the projects’ bottlenecks in a dependency tree configuration. It is currently widely used by mobile teams at Grab to analyse their dependencies and cut out or limit an unnecessary impact on the respective scope.
The tool is currently considered to be open-sourced as we’d like to hear feedback from other external teams and see what can be built on top of it. We’ll provide more details on this in future posts.
Remote Build
Another pillar of the build process is the hardware where the build runs. The solution is really straightforward - put more muscles on your build to get it stronger and to run faster.
Clearly, our engineers’ laptops could not be considered fast enough. To have a fast enough build we were looking at something with 20+ cores, ~200Gb of RAM. None of the desktop or laptop computers can reach those numbers within reasonable pricing. We hit a bottleneck in hardware. Further parallelization of the build process didn’t give any significant improvement as all the build tasks were just queueing and waiting for the resources to be released. And that’s where cloud computing came into the picture where a huge variety of available options is ready to be used.
ADR Mainframer
We took advantage of the Mainframer tool. When the build must run, the code diff is pushed to the remote executor, gets compiled, and then the generated artifacts are pushed back to the local machine. An engineer might still benefit from indexing, debugging, and other features available in the IDE.
To make the infrastructure mature enough, we’ve introduced Kubernetes-based autoscaling based on the load. Currently, we have a stable infrastructure that accommodates 100+ Android engineers scaling up and down (saving costs).
This strategy gave us a 40-50% improvement in the local build time. Android builds finished, in the extreme case, x2 faster.
iOS
Given the success of the Android remote build infrastructure, we have immediately turned our attention to the iOS builds. It was an obvious move for us - we wanted the same infrastructure for iOS builds. The idea looked good on paper and was proven with Android infrastructure, but the reality was a bit different for our iOS builds.
Our very first roadblock was that Xcode is not that flexible and the process of delegating builds to remote is way more complicated as compared to Android. We tackled a series of blockers such as running indexing on a remote machine, sending and consuming build artifacts, and even running the remote build itself.
The reality was that the remote build was absolutely possible for iOS. There were minor tradeoffs impacting engineering experience alongside obvious gains from utilising cloud computing resources. But the problem is that legally iOS builds are only allowed to be built on an Apple machine.
Even if we get the most powerful hardware - a macPro - the specs are still not ideal and are unfortunately not optimised for the build process. A 24 core, 194Gb RAM macPro could have given about x2 improvement on the build time, but when it had to run 3 builds simultaneously for different users, the build efficiency immediately dropped to the baseline value.
Android remote machines with the above same specs are capable of running up to 8 simultaneous builds. This allowed us to accommodate up to 30-35 engineers per machine, whereas iOS’ infrastructure would require to keep this balance at 5-6 engineers per machine. This solution didn’t seem to be scalable at all, causing us to abandon the idea of the remote builds for iOS at that moment.
Test Impact Analysis
The other battlefront was the CI pipeline time. Our efforts in dependency tree optimisations complemented with comparably powerful hardware played a good part in achieving a reasonable build time on CI.
CI validations also include the execution of unit and UI tests and easily take 50%-60% of the pipeline time. The problem was getting worse as the number of tests was constantly growing. We were to face incredibly huge tests’ execution time in the near future. We could mitigate the problem by a muscle approach - throwing more runners and shredding tests - but it won’t make finance executives happy.
So the time for smart solutions came again. It’s a known fact that the simpler solution is more likely to be correct. The simplest solution was to stop running ALL tests. The idea was to run only those tests that were impacted by the codebase change introduced in the given MR.
Behind this simple idea, we’ve found a huge impact. Once the Test Impact Analysis was applied to the pre-merge pipelines, we’ve managed to cut down the total number of executed tests by up to 90% without any impact on the codebase quality or applications’ stability. As a result, we cut the pipeline for both platforms by more than 30%.
Today, the Test Impact Analysis is coupled with our codebase. We are looking to invest some effort to make it available for open sourcing. We are excited to be on this path.
The End of the Native Build Systems
One might say that our journey was long and we won the battle for the build time.
Today, we hit a limit to the native build systems’ efficiency and hardware for both Android and iOS. And it’s clear to us that in our current setup, we would not be able to scale up while delivering high engineering experience.
Let’s Move to Bazel
To introduce another big improvement to the build time, we needed to make some ground-level changes. And this time, we focused on the build system itself.
Native build systems are designed to work well for small and medium-sized projects, however they have not been as successful in large scale projects such as the Grab Passenger applications.
With these assumptions, we considered options and found the Bazel build system to be a good contender. The deep comparison of build systems disclosed that Bazel was promising better results almost in all key areas:
- Bazel enables remote builds out of box
- Bazel provides sustainable cache capabilities (local and remote). This cache can be reused across all consumers - local builds, CI builds
- Bazel was designed with the big codebase as a cornerstone requirement
- The majority of the tooling may be reused across multiple platforms
Ways of Adopting
On paper, Bazel was awesome and shining. All our playground investigations showed positive results:
- Cache worked great
- Incremental builds were incredibly fast
But the effort to shift to this new build system was huge. We made sure that we foresee all possible pitfalls and impediments. It took us about 5 months to estimate the impact and put together a sustainable proof of concept, which reflected the majority of our use cases.
Migration Limitations
After those 5 months of investigation, we got the endless list of incompatible features and major blockers to be addressed. Those blockers touched even such obvious things as indexing and the jump to definition IDE feature, which we used to take for granted.
But the biggest challenge was the need to keep the pace of the product release. There was no compromise of stopping the product development even for a day. The way out appeared to be a hybrid build concept. We figured out how to marry native and Bazel build systems to live together in harmony. This move gave us a chance to start migrating target by target, project by project moving from the bottom to top of the dependency graph.
This approach was a valid enabler, however we were still faced with a challenge of our app’s scale. The codebase of over 2.5 million of LOC cannot be migrated overnight. The initial estimation was based on the idea of manually migrating the whole codebase, which would have required us to invest dozens of person-months.
Team Capacity Limitations
This approach was immediately pushed back by multiple teams arguing with the priority and concerns about the impact on their own product roadmap.
We were left with not much choice. On one hand, we had a pressingly long build time. And on the other hand, we were asking for a huge effort from teams. We clearly needed to get buy-ins from all of our stakeholders to push things forward.
Getting Buy-in
To get all needed buy-ins, all stakeholders were grouped and addressed separately. We defined key factors for each group.
Key Factors
C-level stakeholders:
- Impact. The migration impact must be significant - at least a 40% decrease on the build time.
- Costs. Migration costs must be paid back in a reasonable time and the positive impact is extended to the future.
- Engineering experience. The user experience must not be compromised. All tools and features engineers used must be available during migration and even after.
Engineers:
- Engineering experience. Similar to the criteria established at the C-level factor.
- Early adopters engagement. A common core experience must be created across the mobile engineering community to support other engineers in the later stages.
- Education. Awareness campaigns must be in place. Planned and conducted a series of tech talks and workshops to raise awareness among engineers and cut the learning curve. We wrote hundreds of pages of documentation and guidelines.
Product teams:
- No roadmap impact. Migration must not affect the product roadmap.
- Minimise the engineering effort. Migration must not increase the efforts from engineering.
Migration Automation (Separate Talks)
The biggest concern for the majority of the stakeholders appeared to be the estimated migration effort, which impacted the cost, the product roadmap, and the engineering experience. It became evident that we needed to streamline the process and reduce the effort for migration.
Fortunately, the actual migration process was routine in nature, so we had opportunities for automation. We investigated ideas on automating the whole migration process.
The Tools We’ve Created
We found that it’s relatively easy to create a bunch of tools that read the native project structure and create an equivalent Bazel set up. This was a game changer.
Things moved pretty smoothly for both Android and iOS projects. We managed to roll out tooling to migrate the codebase in a single click/command (well with some exceptions as of now. Stay tuned for another blog post on this). With this tooling combined with the hybrid build concept, we addressed all the key buy-in factors:
- Migration cost dropped by at least 50%.
- Less engineers required for the actual migration. There was no need to engage the wide engineering community as a small group of people can manage the whole process.
- There is no more impact on the product roadmap.
Where We Stand Today
When we were in the middle of the actual migration, we decided to take a pragmatic path and migrate our applications in phases to ensure everything was under control and that there were no unforeseen issues.
The hybrid build time is racing alongside our migration progress. It has a linear dependency on the amount of the migrated code. The figures look positive and we are confident in achieving our impact goal of decreasing at least 40% of the build time.
Plans for Open Source
The automated migration tooling we’ve created is planned to be open sourced. We are doing a bit better on the Android side decoupling it from our applications’ implementation details and plan to open source it in the near future.
The iOS tooling is a bit behind, and we expect it to be available for open-sourcing by the end of Q1’2021.
Is it Worth it All?
Bazel is not a silver bullet for the build time and your project. There are a lot of edge cases you’ll never know until it punches you straight in your face.
It’s far from industry standard and you might find yourself having difficulty hiring engineers with such knowledge. It has a steep learning curve as well. It’s absolutely an overhead for small to medium-sized projects, but it’s undeniably essential once you start playing in a high league of superapps.
If you were to ask whether we’d go this path again, the answer would come in a fast and correct way - yes, without any doubts.
Authored by Sergii Grechukha on behalf of the passenger app team at Grab. Special thanks to Madushan Gamage, Mikhail Zinov, Nguyen Van Minh, Mihai Costiug, Arunkumar Sampathkumar, Maryna Shaposhnikova, Pavlo Stavytskyi, Michael Goletto, Nico Liu, and Omar Gawish for their contributions.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!