
How we reduced our CI YAML files from 1800 lines to 50 lines
This article illustrates how the Cauldron Machine Learning (ML) Platform team uses GitLab parent-child pipelines to dynamically generate GitLab CI files to solve several limitations of GitLab for large repositories, namely:
- Limitations to the number of includes (100 by default).
- Simplifying the GitLab CI file from 1800 lines to 50 lines.
- Reducing the need for nested
gitlab-ciyml files.
Introduction
Cauldron is the Machine Learning (ML) Platform team at Grab. The Cauldron team provides tools for ML practitioners to manage the end to end lifecycle of ML models, from training to deployment. GitLab and its tooling are an integral part of our stack, for continuous delivery of machine learning.
One of our core products is MerLin Pipelines. Each team has a dedicated repo to maintain the code for their ML pipelines. Each pipeline has its own subfolder. We rely heavily on GitLab rules to detect specific changes to trigger deployments for the different stages of different pipelines (for example, model serving with Catwalk, and so on).
Background
Approach 1: Nested child files
Our initial approach was to rely heavily on static code generation to generate the child gitlab-ci.yml files in individual stages. See Figure 1 for an example directory structure. These nested yml files are pre-generated by our cli and committed to the repository.
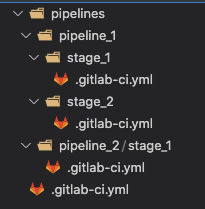 Figure 1: Example directory structure with nested gitlab-ci.yml files. Child `gitlab-ci.yml` files are added by using the include keyword.
Figure 1: Example directory structure with nested gitlab-ci.yml files. Child `gitlab-ci.yml` files are added by using the include keyword.
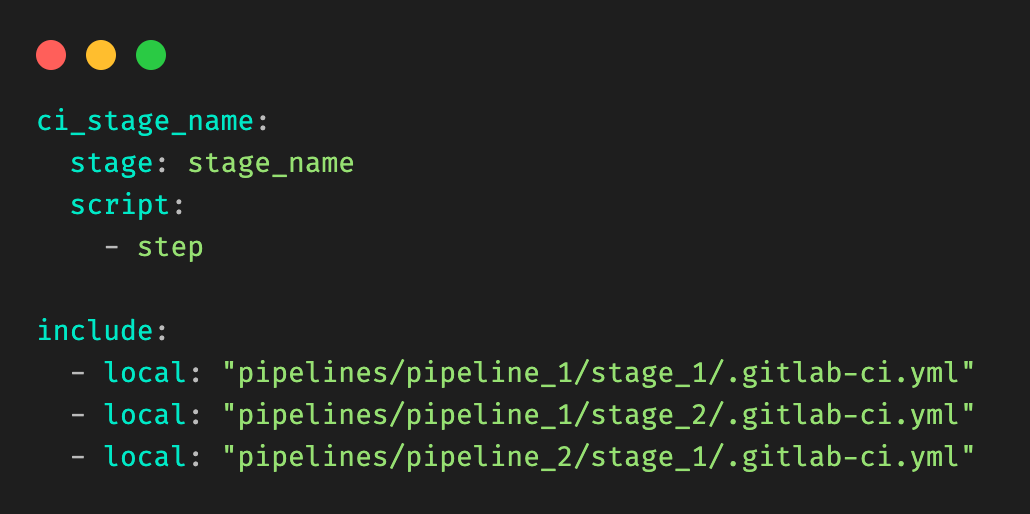 Figure 2: Example root .gitlab-ci.yml file, and include clauses.
Figure 2: Example root .gitlab-ci.yml file, and include clauses.
 Figure 3: Example child `.gitlab-ci.yml` file for a given stage (Deploy Model) in a pipeline (pipeline 1).
Figure 3: Example child `.gitlab-ci.yml` file for a given stage (Deploy Model) in a pipeline (pipeline 1).
As teams add more pipelines and stages, we soon hit a limitation in this approach:
There was a soft limit in the number of includes that could be in the base
.gitlab-ci.ymlfile.
It became evident that this approach would not scale to our use-cases.
Approach 2: Dynamically generating a big CI file
Our next attempt to solve this problem was to try to inject and inline the nested child gitlab-ci.yml contents into the root gitlab-ci.yml file, so that we no longer needed to rely on the in-built GitLab “include” clause.
To achieve it, we wrote a utility that parsed a raw gitlab-ci file, walked the tree to retrieve all “included” child gitlab-ci files, and to replace the includes to generate a final big gitlab-ci.yml file.
Figure 4 illustrates the resulting file is generated from Figure 3.
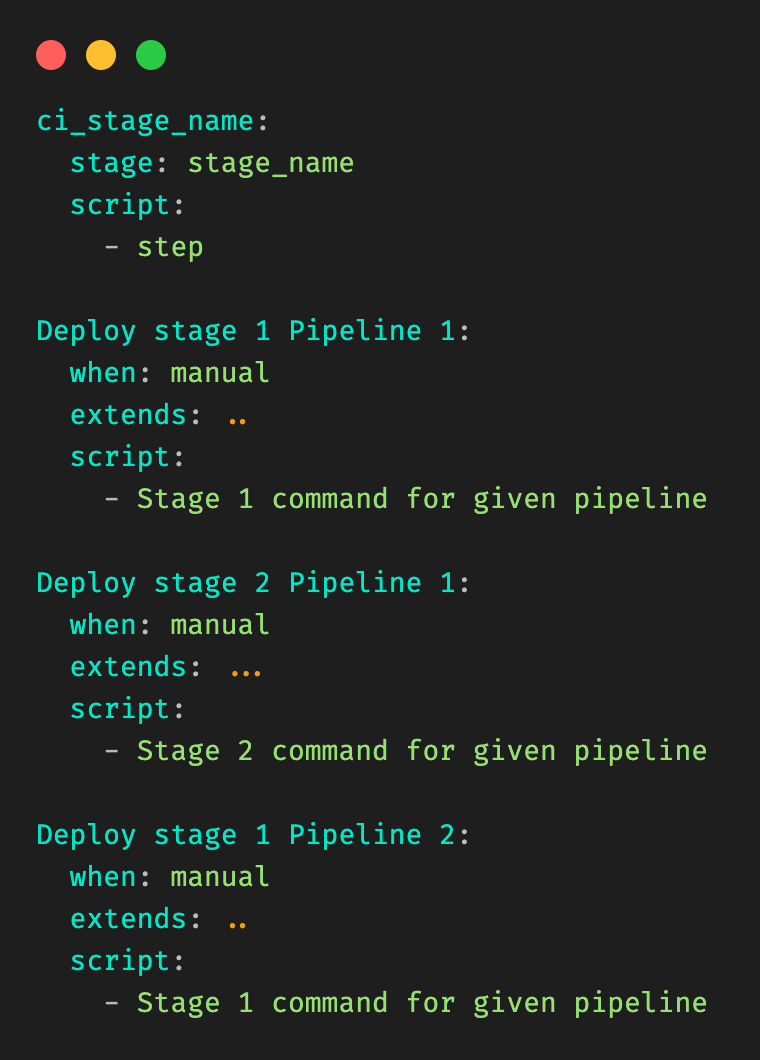 Figure 4: “Fat” YAML file generated through this approach, assumes the original raw file of Figure 3.
Figure 4: “Fat” YAML file generated through this approach, assumes the original raw file of Figure 3.
This approach solved our issues temporarily. Unfortunately, we ended up with GitLab files that were up to 1800 lines long. There is also a soft limit to the size of gitlab-ci.yml files. It became evident that we would eventually hit the limits of this approach.
Solution
Our initial attempt at using static code generation put us partially there. We were able to pre-generate and infer the stage and pipeline names from the information available to us. Code generation was definitely needed, but upfront generation of code had some key limitations, as shown above. We needed a way to improve on this, to somehow generate GitLab stages on the fly. After some research, we stumbled upon Dynamic Child Pipelines.
Quoting the official website:
Instead of running a child pipeline from a static YAML file, you can define a job that runs your own script to generate a YAML file, which is then used to trigger a child pipeline.
This technique can be very powerful in generating pipelines targeting content that changed or to build a matrix of targets and architectures.
We were already on the right track. We just needed to combine code generation with child pipelines, to dynamically generate the necessary stages on the fly.
Architecture details
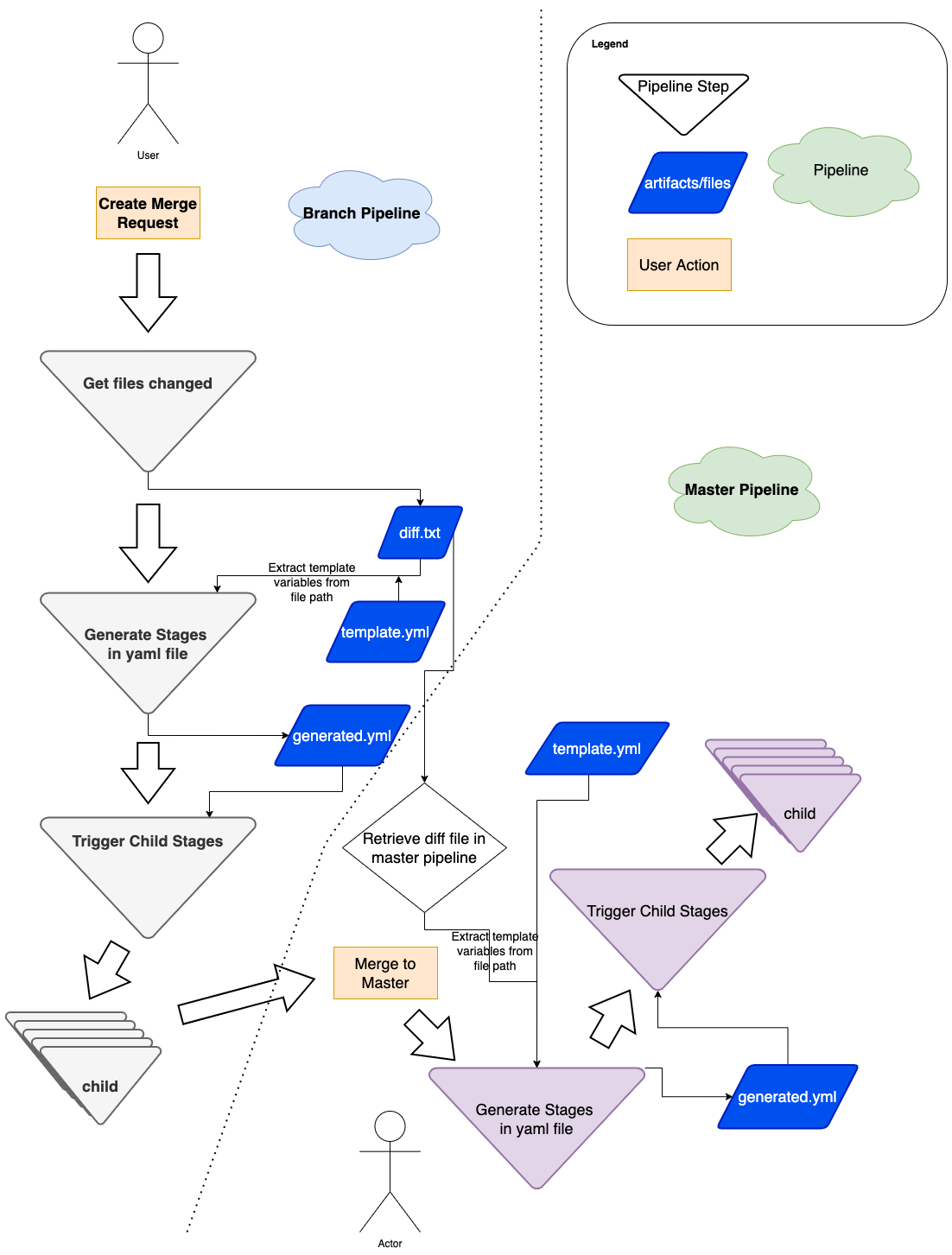 Figure 5: Flow diagram of how we use dynamic yaml generation. The user raises a merge request in a branch, and subsequently merges the branch to master.
Figure 5: Flow diagram of how we use dynamic yaml generation. The user raises a merge request in a branch, and subsequently merges the branch to master.
Implementation
The user Git flow can be seen in Figure 5, where the user modifies or adds some files in their respective Git team repo. As a refresher, a typical repo structure consists of pipelines and stages (see Figure 1). We would need to extract the information necessary from the branch environment in Figure 5, and have a stage to programmatically generate the proper stages (for example, Figure 3).
In short, our requirements can be summarized as:
- Detecting the files being changed in the Git branch.
- Extracting the information needed from the files that have changed.
- Passing this to be templated into the necessary stages.
Let’s take a very simple example, where a user is modifying a file in stage_1 in pipeline_1 in Figure 1. Our desired output would be:
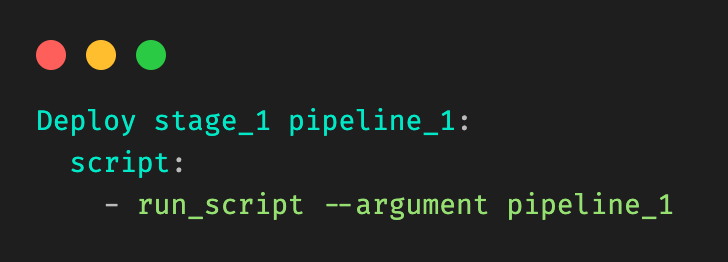 Figure 6: Desired output that should be dynamically generated.
Figure 6: Desired output that should be dynamically generated.
Our template would be in the form of:
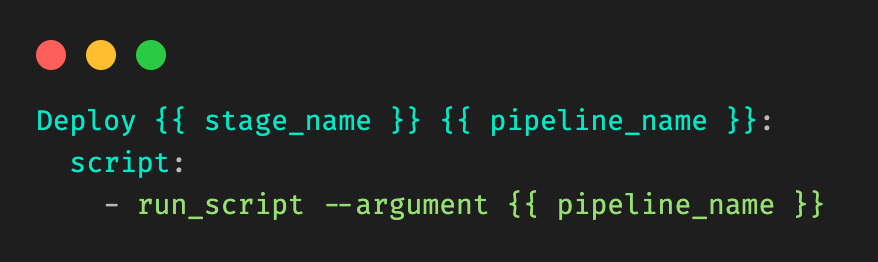 Figure 7: Example template, and information needed. Let’s call it template_file.yml.
Figure 7: Example template, and information needed. Let’s call it template_file.yml.
First, we need to detect the files being modified in the branch. We achieve this with native git diff commands, checking against the base of the branch to track what files are being modified in the merge request. The output (let’s call it diff.txt) would be in the form of:
M pipelines/pipeline_1/stage_1/modelserving.yaml
We must extract the yellow and green information from the line, corresponding to pipeline_name and stage_name.
 Figure 9: Information that needs to be extracted from the file.
Figure 9: Information that needs to be extracted from the file.
We take a very simple approach here, by introducing a concept called stop patterns.
Stop patterns are defined as a comma separated list of variable names, and the words to stop at. The colon (:) denotes how many levels before the stop word to stop.
For example, the stop pattern:
pipeline_name:pipelines
tells the parser to look for the folder pipelines and stop before that, extracting pipeline_1 from the example above tagged to the variable name pipeline_name.
The stop pattern with two colons (::):
stage_name::pipelines
tells the parser to stop two levels before the folder pipelines, and extract stage_1 as stage_name.
Our cli tool allows the stop patterns to be comma separated, so the final command would be:
cauldron_repo_util diff.txt template_file.yml
pipeline_name:pipelines,stage_name::pipelines > generated.yml
We elected to write the util in Rust due to its high performance, and its rich templating libraries (for example, Tera) and decent cli libraries (clap).
Combining all these together, we are able to extract the information needed from git diff, and use stop patterns to extract the necessary information to be passed into the template. Stop patterns are flexible enough to support different types of folder structures.
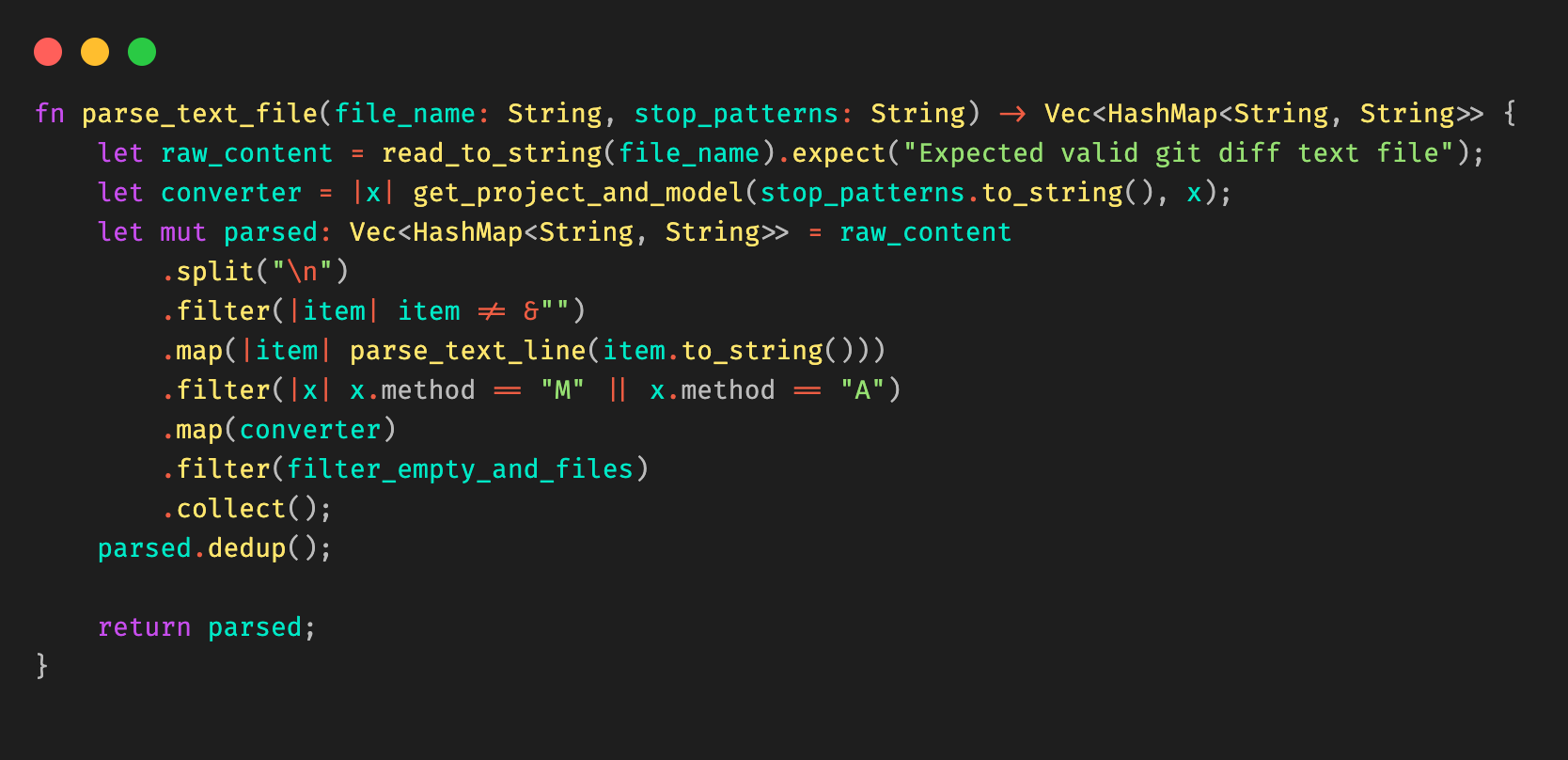 Figure 10: Example Rust code snippet for parsing the Git diff file.
Figure 10: Example Rust code snippet for parsing the Git diff file.
When triggering pipelines in the master branch (see right side of Figure 5), the flow is the same, with a small caveat that we must retrieve the same diff.txt file from the source branch. We achieve this by using the rich GitLab API, retrieving the pipeline artifacts and using the same util above to generate the necessary GitLab steps dynamically.
Impact
After implementing this change, our biggest success was reducing one of the biggest ML pipeline Git repositories from 1800 lines to 50 lines. This approach keeps the size of the .gitlab-ci.yaml file constant at 50 lines, and ensures that it scales with however many pipelines are added.
Our users, the machine learning practitioners, also find it more productive as they no longer need to worry about GitLab yaml files.
Learnings and conclusion
With some creativity, and the flexibility of GitLab Child Pipelines, we were able to invest some engineering effort into making the configuration re-usable, adhering to DRY principles.
Special thanks to the Cauldron ML Platform team.
What’s next
We might open source our solution.
References
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!