
How we store and process millions of orders daily
Introduction
In the real world, after a passenger places a GrabFood order from the Grab App, the merchant-partner will prepare the order. A driver-partner will then collect the food and deliver it to the passenger. Have you ever wondered what happens in the backend system? The Grab Order Platform is a distributed system that processes millions of GrabFood or GrabMart orders every day. This post aims to share the journey of how we designed the database solution that powers the order platform.
Background
What are the design goals when building the database solution? We collected the requirements by analysing query patterns and traffic patterns.
Query patterns
Here are some important query examples that the Order Platform supports:
-
Write queries:
a. Create an order.
b. Update an order.
-
Read queries:
a. Get order by id.
b. Get ongoing orders by passenger id.
c. Get historical orders by various conditions.
d. Get order statistics (for example, get the number of orders)
We can break down queries into two categories: transactional queries and analytical queries. Transactional queries are critical to online order creation and completion, including the write queries and read queries such as 2a or 2b. Analytical queries like 2c and 2d retrieves historical orders or order statistics on demand. Analytical queries are not essential to the oncall order processing.
Traffic patterns
Grab’s Order Platform processes a significant amount of transaction data every month.
During peak hours, the write Queries per Second (QPS) is three times of primary key reads; whilst the range Queries per Second are four times of the primary key reads.
Design goals
From the query and traffic patterns, we arrived at the following three design goals:
- Stability - the database solution must be able to handle high read and write QPS. Online order processing queries must have high availability. Even when some part of the system is down, we must be able to provide a degraded experience to the end users allowing them to still be able to create and complete an order.
- Scalability and cost - the database solution must be able to support fast evolution of business requirements, given now we handle up to a million orders per month. The solution must also be cost effective at a large scale.
- Consistency - strong consistency for transactional queries, and eventually consistency for analytical queries.
Solution
The first design principle towards a stable and scalable database solution is to use different databases to serve transactional and analytical queries, also known as OLTP and OLAP queries. An OLTP database serves queries critical to online order processing. This table keeps data for only a short period of time. Meanwhile, an OLAP database has the same set of data, but serves our historical and statistical queries. This database keeps data for a longer time.
What are the benefits from this design principle? From a stability point of view, we can choose different databases which can better fulfil our different query patterns and QPS requirements. An OLTP database is the single source of truth for online order processing; any failure in the OLAP database will not affect online transactions. From a scalability and cost point of view, we can choose a flexible database for OLAP to support our fast evolution of business requirements. We can maintain less data in our OLTP database while keeping some older data in our OLAP database.
To ensure that the data in both databases are consistent, we introduced the second design principle - data ingestion pipeline. In Figure 1, Order Platform writes data to the OLTP database to process online orders and asynchronously pushes the data into the data ingestion pipeline. The data ingestion pipeline ensures that the OLAP database data is eventually consistent.
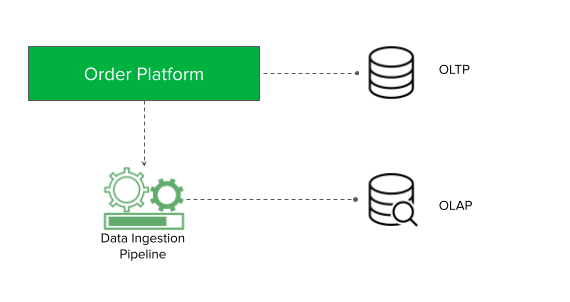
Architecture details
OLTP database
There are two categories of OLTP queries, the key-value queries (for example, load by order id) and the batch queries (for example, Get ongoing orders by passenger id). We use DynamoDB as the database to support these OLTP queries.
Why DynamoDB?
- Scalable and highly available: the tables of DynamoDB are partitioned and each partition is three-way replicated.
- Support for strong consistent reads by primary key.
- DynamoDB has a mechanism called adaptive capacity to handle hotkey traffic. Internally, DynamoDB will distribute higher capacity to high-traffic partitions, and isolate frequently accessed items to a dedicated partition. This way, the hotkey can utilise the full capacity of an entire partition, which is up to 3000 read capacity units and 1000 write capacity units.
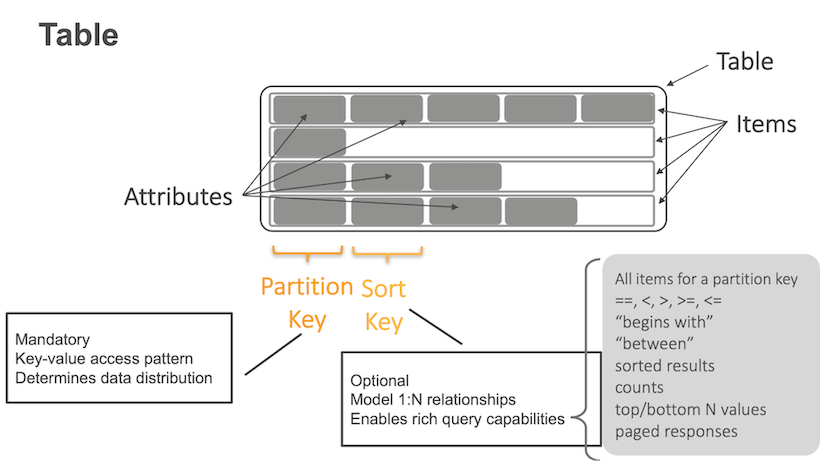
In each DynamoDB table, it has many items with attributes. In each item, it has a partition key and sort key. The partition key is used for key-value queries, and the sort key is used for range queries. In our case, the table contains multiple order items. The partition key is order ID. We can easily support key-value queries by the partition key.
| order_id (PK) | state | pax_id | created_at | pax_id_gsi |
|---|---|---|---|---|
| order1 | Ongoing | Alice | 9:00am | |
| order2 | Ongoing | Alice | 9:30am | |
| order3 | Completed | Alice | 8:30am |
Batch queries like ‘Get ongoing orders by passenger id’ are supported by DynamoDB Global Secondary Index (GSI). A GSI is like a normal DynamoDB table, which also has keys and attributes.
In our case, we have a GSI table where the partition key is the pax_id_gsi. The attribute pax_id_gsi is linked to the main table. It is eventually consistent with the main table that is maintained by DynamoDB. If the Order Platform queries ongoing orders for Alice, two items will be returned from the GSI table.
| pax_id_gsi (PK) | created_at (SK) | order_id |
|---|---|---|
| Alice | 9:00am | order1 |
| Alice | 9:30am | order2 |
We also make use of an advanced feature of GSI named sparse index to support ongoing order queries. When we update order status from ongoing to completed, at the same time, we set the pax_id_gsi to empty, so that the linked item in the GSI will be automatically deleted by DynamoDB. At any time, the GSI table only stores the ongoing orders. We use a sparse index mechanism to control our table size for better performance and to be more cost effective.
The next problem is data retention. This is achieved with the DynamoDB Time To Live (TTL) feature. DynamoDB will auto-scan expired items and delete them. But the challenge is when we add TTL to big tables, it will bring a heavy load to the background scanner and might result in an outage. Our solution is to only add a TTL attribute to the new items in the table. Then, we manually delete the items without TTL attributes, and run a script to delete items with TTL attributes that are too old. After this process, the table size will be quite small, so we can enable the TTL feature on the TTL attribute that we previously added without any concern. The retention period of our DynamoDB data is three months.
Costwise, DynamoDB is charged by storage size and the provision of the read write capability. The provision capability is actually auto scalable. The cost is on-demand. So it’s generally cheaper than RDS.
OLAP database
We use MySQL RDS as the database to support historical and statistical OLAP queries.
Why not Aurora? We choose RDS mainly because it is a mature database solution. Even if Aurora can provide better high-availability, RDS is enough to support our less critical use cases. Costwise, Aurora charges by data storage and the number of requested Input/Output Operations per Second (IOPS). RDS charges only by data storage. As we are using General Purpose (SSD) storage, IOPS is free and supports up to 16k IOPS.
We use MySQL partitioning for data retention. The order table is partitioned by creation time monthly. Since the data access pattern is mostly by month, the partition key can reduce cross-partition queries. Partitions older than six months are dropped at the beginning of each month.
Data ingestion pipeline
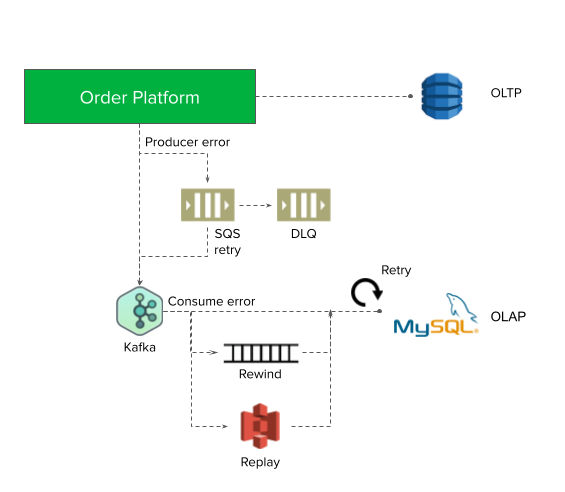
A Kafka stream is used to process data in the data ingestion pipeline. We choose the Kafka stream, because it has 99.95% SLA. It is not restricted by the OLTP and OLAP database types.
Even if Kafka can provide 99.95% SLA, there is still the chance of stream producer failures. When the producer fails, we will store the message in an Amazon Simple Queue Service (SQS) and retry. If the retry also fails, it will be moved to the SQS dead letter queue (DLQ), to be consumed at a later time.
On the stream consumer side, we use back-off retry at both stream and database levels to ensure consistency. In a worst-case scenario, we can rewind the stream events from Kafka.
It is important for the data ingestion pipeline to handle duplicate messages and out-of-order messages.
Duplicate messages are handled by the database level unique key (for example, order ID + creation time).
For the out-of-order messages, we implemented the following two mechanisms:
- Version update: we only update the most recently updated data. The precision of the update time is in microseconds, which is enough for most of the use cases.
- Upsert: if the update events occur before the create events, we simulate an upsert operation.
Impact
After launching our solution this year, we have saved significantly on cloud costs. In the earlier solution, Order Platform synchronously writes to DynamoDB and Aurora and the data is kept forever.
Conclusion
In terms of stability, we use DynamoDB as the critical OLTP database to ensure high availability for online order processing. Scalability wise, we use RDS as the OLAP database to support our quickly evolving business requirements by using a rich, multiple index. Cost efficiency is achieved by data retention in both databases. For consistency, we built a single source of truth OLTP database and an OLAP database that is eventually consistent with the help of the data ingestion pipeline.
What’s next?
Currently, the database solution is running on the production environment. Even though the database solution is proven to be stable, scalable and consistent, we still see some potential areas of improvement.
We use MySQL RDS for OLAP data storage. Even though MySQL is stable and cost effective, it is difficult to serve more complicated queries like free text search. Hence, we plan to explore other NoSQL databases like ElasticSearch.
We hope this post helps you understand how we store Grab orders and fulfil the queries from the Grab Order Platform.
References
Amazon Web Services. (2019, 28 April) Build with DynamoDB: S1 E1 – Intro to Amazon DynamoDB [Video]. YouTube.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!