
Introducing Grab-Kit: Distributed Service Design at Grab
As Grab rapidly expands its services, we at Engineering continue to look for ways to work smarter and deliver qualitative and relevant services quickly and efficiently. This helps us to stay true to our commitment to outserve our partners and consumers.
As we evolved from a single monolithic application to a microservices-based architecture, we were faced with a new challenge. How do we support exponential growth while maintaining consistency, coordination, and quality?
Here is what we came up with.
A Framework to Solve it All
Our Grab Developer Experience team came up with the following solution: Grab-Kit - a framework for building Go microservices. Grab-Kit is designed to create a fully functional microservice scaffolding in seconds, allowing engineers to focus on the business logic straight away!
Grab-Kit provides abstraction from all aspects of distributed system design by simplifying the creation and operation of microservices through scaffolding, using smart library configuration defaults, automatic initialisation, context propagation, and runtime framework configuration. Moreover, it standardises communication across services.
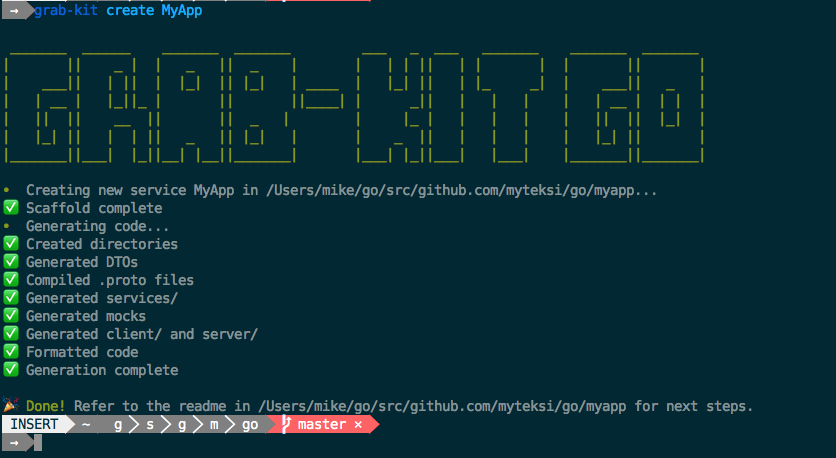
We no longer need to spend long hours generating boilerplate code, initialising common libraries, creating dashboards and alarms, or creating Data Access Objects (DAOs). Instead, we can concentrate on delivering scalable and agile services that are essential for the success of our engineers and in turn delight our consumers.
The Heart of Grab-Kit
The inspiration behind the Grab-Kit framework is Go-Kit. However, Grab-Kit goes beyond the ideas proposed by Go-Kit, for example, our Grab-Kit has added automatic code generation, which saves efforts required in writing boilerplate code for both server and client service sides. While Go-Kit proposes techniques for microservices, there is still a lot of manual work involved in implementing them. In contrast, Grab-Kit actually helps us focus on the business logic by doing this work for us while codifying all best engineering practices around distributed service design.
Continue reading to see what we love most about Grab-Kit.
Standardisation
The underlying intention of Grab-Kit is to gain consistency across services in the following components:
Service Definitions
Problems
Services have multiple sources and configurations, and produce inconsistent APIs, SDKs, error handling, transport layer, and so on.
Solution
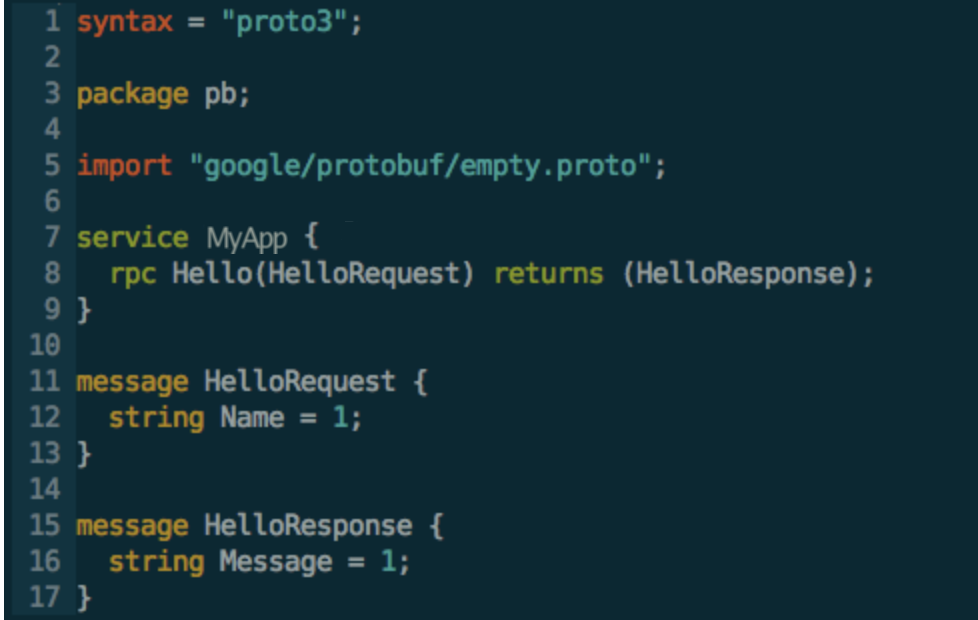
Reaching a level of consistency relies on having a single source of truth. Grab-Kit defines the service definition in a proto definition file (.proto file) and considers this file as the single source of truth.
How is it done?
Grab-Kit automatically generates a .proto file when we run Grab-Kit create <service> for the first time; this file is then used by Grab-Kit to generate all other code such as boilerplates and data transfer objects (DTOs). Grab-Kit automatically generates DTOs for custom message types in the .proto file. It also generates the protocol buffers (protobuf) bindings for these types, so they can be converted between the Go DTO and protobuf types.
Middleware Stack
Problems
Teams manage multiple logs in various locations. The logs were in many different formats, making it difficult to search and filter them.
Traceability is another factor that prevented teams from monitoring service health efficiently. There was no indication on what happened to a request.
Solution
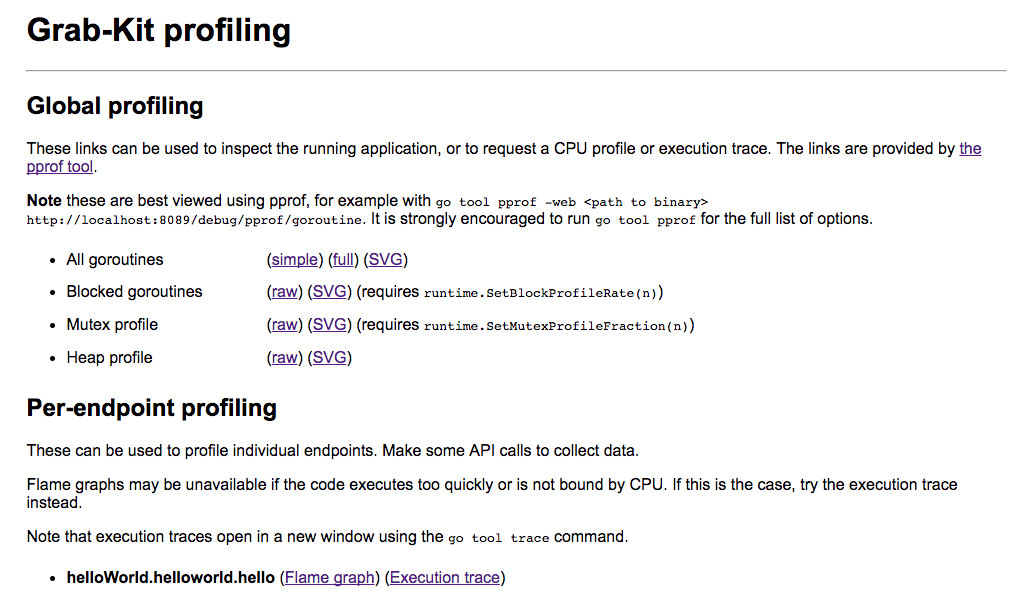
Grab-Kit uses a consistent middleware stack across all clients. It uses middleware for logging, circuit breaker, stats, panic recovery, profiling, caching, and so on. Grab-Kit provides easy, automatic profiling with flame graphs and execution traces available in development mode. Further, all service related metrics and logs are generated automatically.
How is it done?
Grab-Kit wraps endpoints with a standard middleware for logging and stats. It also compacts stack traces using the panicparse library. Grab-Kit’s output is much more readable than the default output.
In addition, the consistent middleware stack automatically starts the CPU profile and trace for each endpoint on developer mode.
Automated Dashboard Generation
Problems
Our services are monitored on dashboards and monitoring is important to ensure that our services are working as they should. However, it can be time consuming to create meaningful dashboards without fully understanding the available metrics in our libraries, or how to even use them.
Dashboards also need to be regularly maintained as changes to the metrics or keys used can lead to missing or inaccurate graphs.
Missing alerts can lead to production incidents going unnoticed, consequently costing Grab business opportunities.
Solution
With Grab-Kit, we can automatically create dashboards and add graphs (for monitoring and observing) for our services and all its upstream dependencies. In addition, we can keep the graphs up to date as the codebase changes.
How is it done?
We enable libraries to define the metrics published in a declarative manner (metrics.yaml). A tool (grab-kit dash) reads these files and uses the DataDog API to automatically create a dashboard with the given metrics. If a dashboard already exists, Grab-Kit adds any missing metrics and updates the existing ones, ensuring that the dashboard is always complete and in sync.
Following is an example workflow for creating dashboards and updating existing ones:
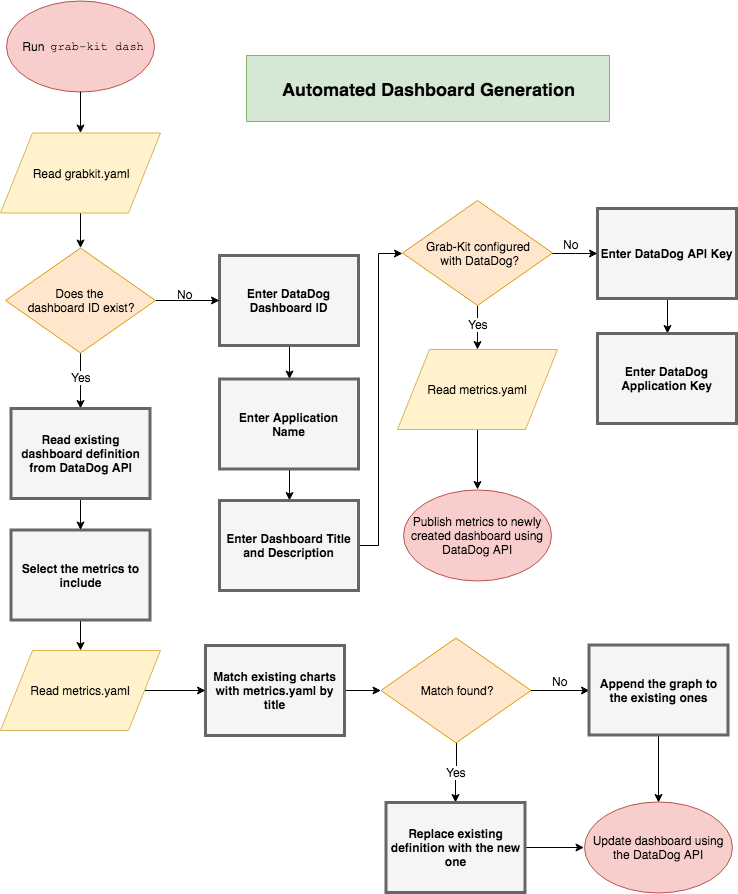
We’ve gone with the modular approach because not all libraries -are relevant to a particular service. This means that Grab-Kit can selectively publish graphs from just the libraries used by the service. For example, if service X doesn’t use Elasticsearch, then it doesn’t need the Elasticsearch metrics.
There is a group of ‘core’ metrics included by default, and additional ones can be selected by the service owner.
Final Thoughts
With Grab-Kit’s out-of-the-box support for microservice features such as authentication and authorisation, throttling, client-side load balancing, logging, metering, and so on, we’ve seen a huge increase in our productivity. Our friends in the GrabFood team now save up to 70% development time on creating a new service. We have also recorded improvements in stability and availability of our services.
More and more teams have adopted Grab-Kit since the Grab Developer Experience team released it in November 2017. We see a marginal growth in adoption every month as illustrated in the following chart:
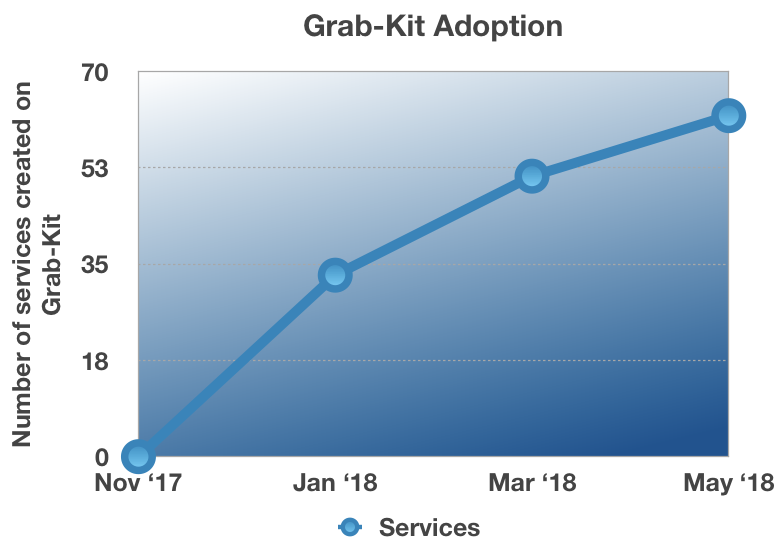
At Grab, we are on a never-ending journey to deliver robust services that meet our consumers’ requirements. We continue to standardise and streamline our engineering best practices around distributed service design through Grab-Kit. The future is in Grab-Kit!
Should you have any questions or require more details about Grab-Kit, please don’t hesitate to leave a comment.