
Migrating Existing Datastores
At Grab we take pride in creating solutions that impact millions of people in Southeast Asia and as they say, with great power comes great responsibility. As an app with 55 million downloads and 1.2 million drivers, it’s our responsibility to keep our systems up-and-running. Any downtime causes drivers to miss earning and passengers to miss their appointments.
It all started when in early 2017, Grab Identity team realised that given the rate at which our user base was growing, we wouldn’t be able to sustain the load with our existing single Redis node architecture. We used Redis as a cache to store authentication tokens required for secure mobile client to server communication. These tokens are permanently backed up in an underlying MySQL store. The existing Redis instance was filling at crazy speeds and we were growing at a rate at which we had a maximum of 2 months to react before we would start to ‘choke’ i.e. running out of memory to store more data or run operations on the above mentioned Redis node.
It was the moment of truth for us, and forced us to re-evaluate the design and revisit architectural decisions. We had to move away from our existing Redis node and do it fast. We had several options:
- Move to a larger Redis instance: While definitely an option, we now had the opportunity to solve for the existing flaw of a single point of failure in our design. In spite of having replication groups set up, in cases of failure it can take a few minutes before a slave gets promoted as master and until that happens, service write operations would remain impacted. Our priority was moving in the direction of higher availability.
- Move away from Redis: Well, that was one of the options, but it was not the time to re-evaluate other caching solutions from scratch.
- Setup a custom Redis cluster, backed by Redis Replication Groups: This option did address availability concerns, but raised additional concerns:
- We had to rely on client-side sharding, so clients would be slightly more complex.
- In case of having to add a new shard, the migration was going to be very tricky. Remember, it was a custom cluster so there would be no self-balancing offered. We might end up moving selected user information from existing nodes to new nodes, pretty much cherry picking via some custom logic for this one time migration.
- Use AWS ElastiCache cluster:
- Server-side data sharding was available, meaning AWS would take care of the sharding strategy for us.
- Adding a new shard was not possible, oops!… BUT, anyhow a fresh setup might turn out to be more clean and deterministic than running custom rebalancing implementation as in the above option.
From all the mentioned options, it was clear to us that achieving a completely horizontally scalable model where data-sources could be increased on demand with ease, was not possible with the Redis-AWS combination (unless we ended up with a self-hosted Redis on EC2). This is when we started questioning some assumptions:
Did we need horizontal scalability for all the operations?
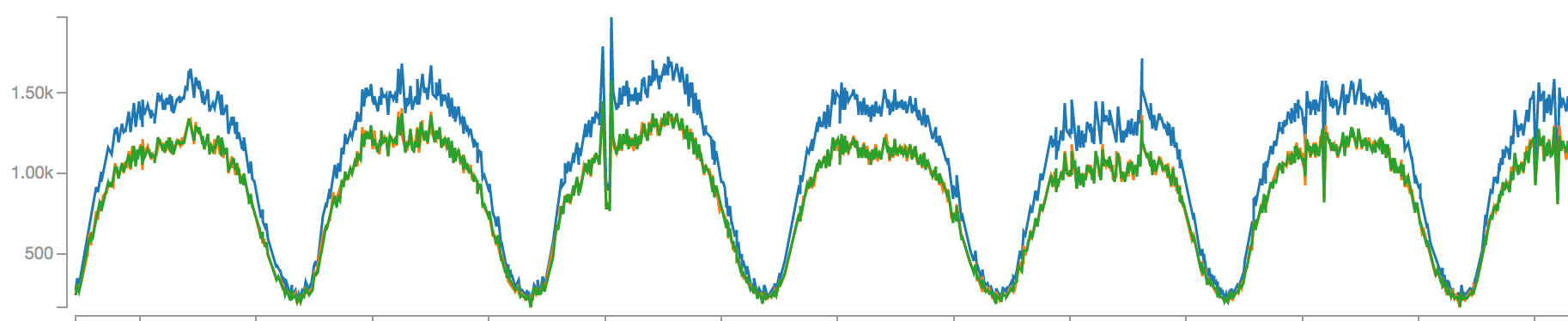
And we had the answer to this. In a typical authentication system, the scale of writes is significantly lower compared to that of reads. A token that was provisioned in 1 request, would end up being used to authenticate another N requests and our graphs validated this:
Write load
VS
Read load
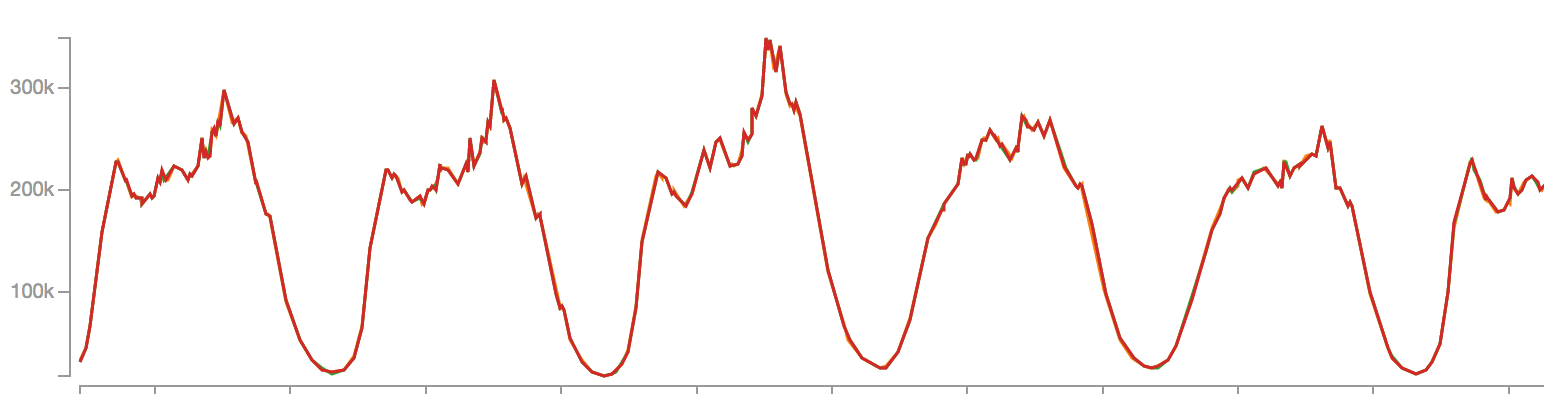
It was a clear difference of ~200 times in peak load. So, what if we can achieve horizontal scalability in read cases, and be a bit futuristic in provisioning shards to cover write load?
We had our answer and our winner in the process. AWS ElastiCache did offer support for adding new nodes on demand. These new nodes would act as the read-replica of the master node in the same shard, meaning we can potentially provide horizontal scalability for read operations. To decide on the number of shards, we projected our rate of growth based on what we saw in the previous 6 months, factored in future plans with some additional buffer and decided to go with 3 shards, with 2 replicas for each master; 9 nodes in total.
Now that we had finalised the direction, we had to move and define milestones for ourselves. We decided a few targets for this move:
- No downtime: This was one of the audacious targets that we set for ourselves. We wanted to avoid even a single second of downtime of our systems and that was no easy thing. Why so? For some perspective: this service was handling a peak load of 20k per sec, which meant a 10 second downtime would impact ~200k requests, roughly translating to 50k users. Importantly, unlike other businesses, it was not an option to carry out maintenance tasks such as these at low load times. This policy stems from the belief that at odd hours our availability becomes even more critical for the consumers. They are more dependent on our services and rely on us to help them provide safe transport, when other means are probably not available. Imagine someone counting on us for his/her 4:00AM flight.
- Zero collateral damage during this move, meaning that no existing tokens should be invalidated or missed in the new source. This implied that during the move, data in the new datasource had to be in perfect sync with the old datasource.
- No security loopholes, we wanted to ensure that all the invalidated tokens remain invalid and not leave even a tiny window to reuse those.
In a nutshell, we planned to switch the datasource for the 20k QPS system, without any user experience impact, while in a live running mode.
We made our combat plan as comprehensive as possible; outlining each step with maximum precision and caution. Our migration plan comprised of the following six steps.
Step 1: One time data migration from old Redis Node to Redis Cluster
This was relatively simple, since the new cluster was not handling live traffic. We just had to make sure that we did not end up impacting performance of the existing node during the migration. SCAN, DUMP and RESTORE did the trick for us, without any clear impact on performance.
Step 2: Application changes to write to new Redis Cluster in asynchronous mode in request path (alongside the old datastore). Shadow writing to the new cluster did not add latency to existing requests and allowed us to validate that all the service to cluster interactions were working as expected. Even in case of failure, the requests will not be impacted.
Step 3: Application to start writing to new Redis Cluster in synchronous mode in request path. Once step 2 was validated, it was time to make the next move. Any failure in cluster calls, would result in the failure of the API call in this step.
Step 4: Application to start reading from Redis Cluster in asynchronous mode and validate values against old Redis Node. This was a validation step to ensure the data being written in the new data source was in sync with the old source. Respective validation results were being tracked as metrics. This validation was being carried out as part of existing read APIs.
Step 5: Move all the Application reads from old Redis Node to new Redis Cluster. This was THE move, where we stopped reading from old data-source. By this point all the APIs were already backed by the redis-cluster.
Step 6: Stop writing to the old Redis Node. This was just a cleanup step, to remove any interactions with the old source.
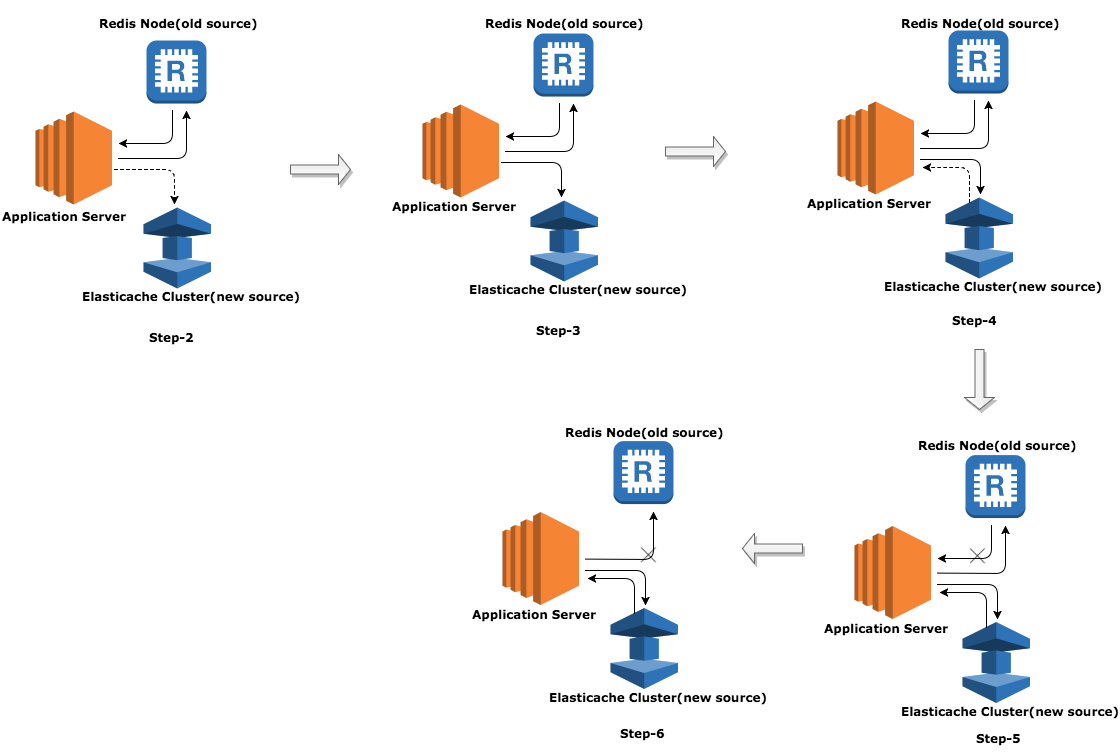
Each step was controlled by configuration flags. In case of unforeseen events or drastic situation, we had levers to move the system back to its original state. Additionally, at each step we added extensive metrics to make sure that we had solid data-points backing our move to confidently move to the next step. We moved smoothly from one step to another and there came a time when we moved to Step 6 and there, we had defused the bomb, timely.
What did we learn from this — in the software world, things are not always tough, problems may not require rocket-science tech all the time. Sometimes, it’s more about well thought-through planning, meticulous execution, coordinated steps, measured and data driven decision making, that’s all you need to have a winning strategy.