
Serving Driver-partners Data at Scale Using Mirror Cache
Since the early beginnings, driver-partners have been the centrepiece of the wide-range of services or features provided by the Grab platform. Over time, many backend microservices were developed to support our driver-partners such as earnings, ratings, insurance, etc. All of these different microservices require certain information, such as name, phone number, email, active car types, and so on, to curate the services provided to the driver-partners.
We built the Drivers Data service to provide drivers-partners data to other microservices. The service attracts a high QPS and handles 10K requests per second during peak hours. Over the years, we have tried different strategies to serve driver-partners data in a resilient and cost-effective manner, while accounting for low response time. In this blog post, we talk about mirror cache, an in-memory local caching solution built to serve driver-partners data efficiently.
What We Started With
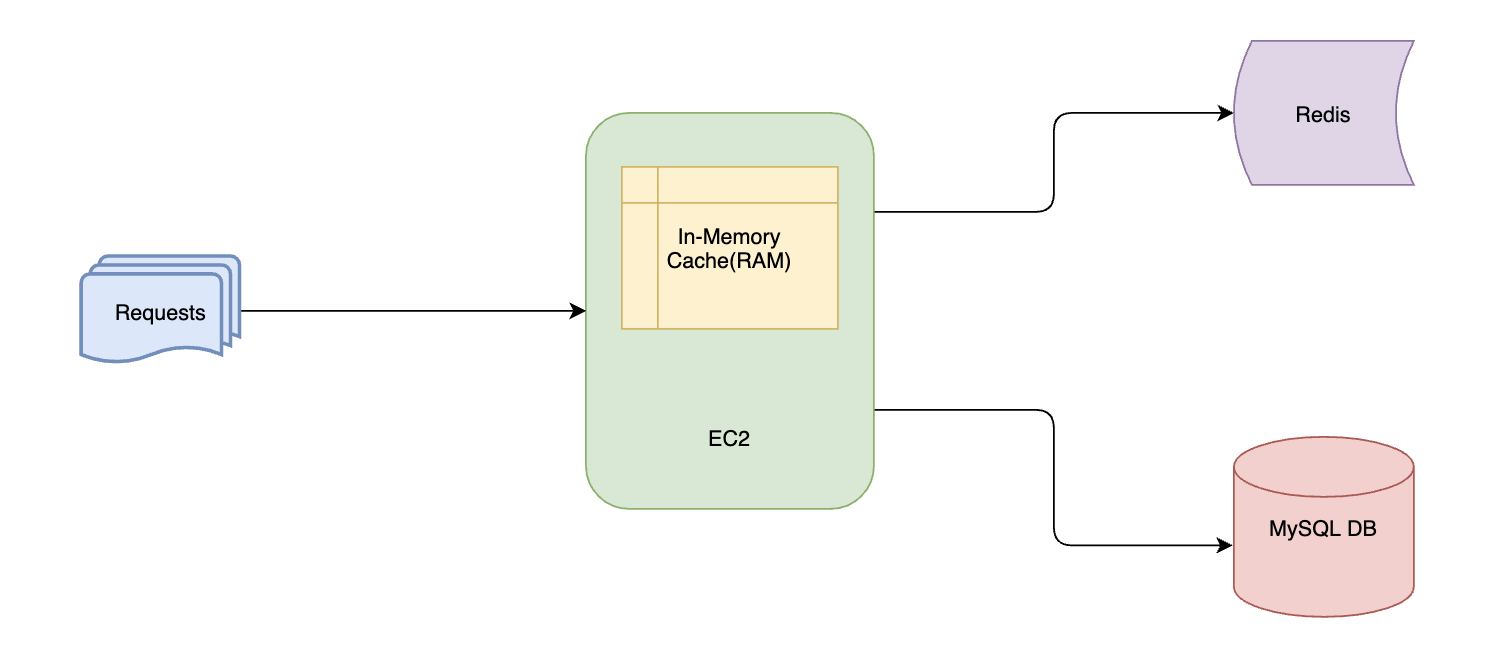
Our Drivers Data service previously used MySQL DB as persistent storage and two caching layers - standalone local cache (RAM of the EC2 instances) as primary cache and Redis as secondary for eventually consistent reads. With this setup, the cache hit ratio was very low.
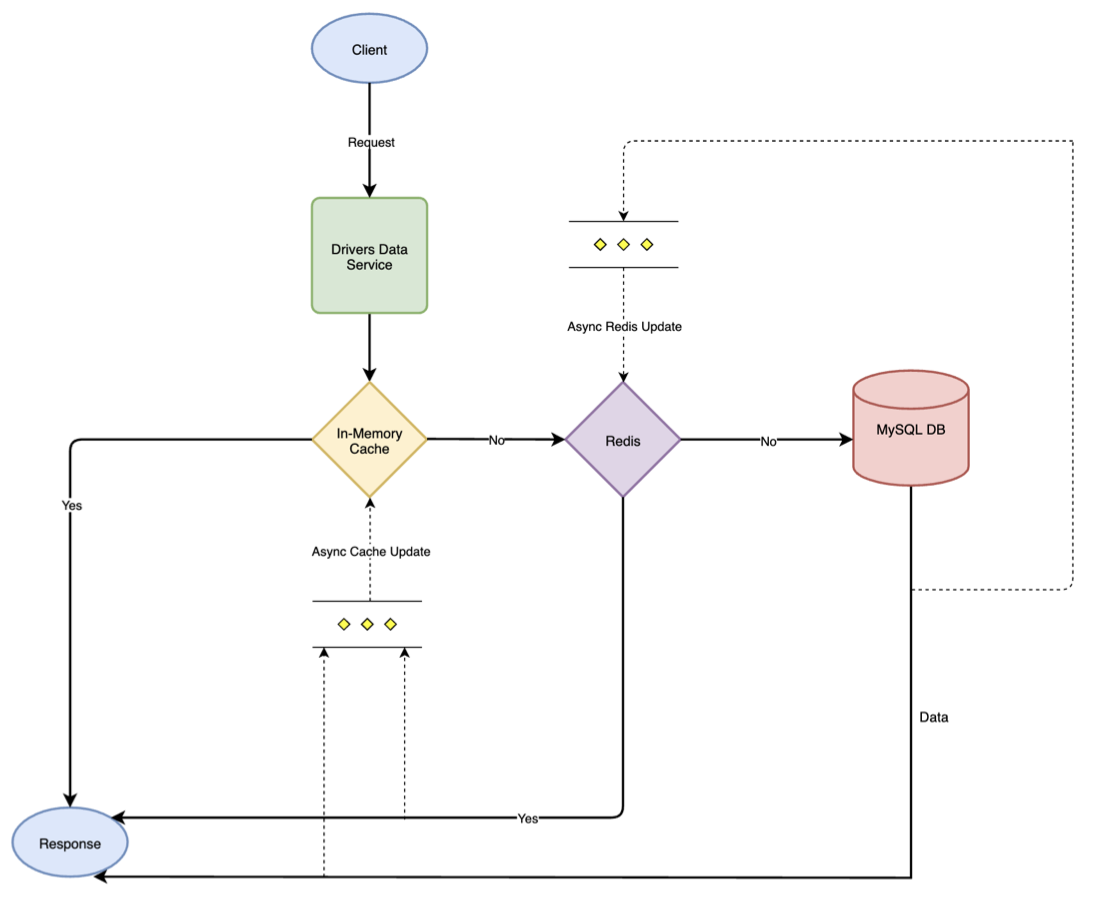
We opted for a cache aside strategy. So when a client request comes, the Drivers Data service responds in the following manner:
- If data is present in the in-memory cache (local cache), then the service directly sends back the response.
- If data is not present in the in-memory cache and found in Redis, then the service sends back the response and updates the local cache asynchronously with data from Redis.
- If data is not present either in the in-memory cache or Redis, then the service responds back with the data fetched from the MySQL DB and updates both Redis and local cache asynchronously.
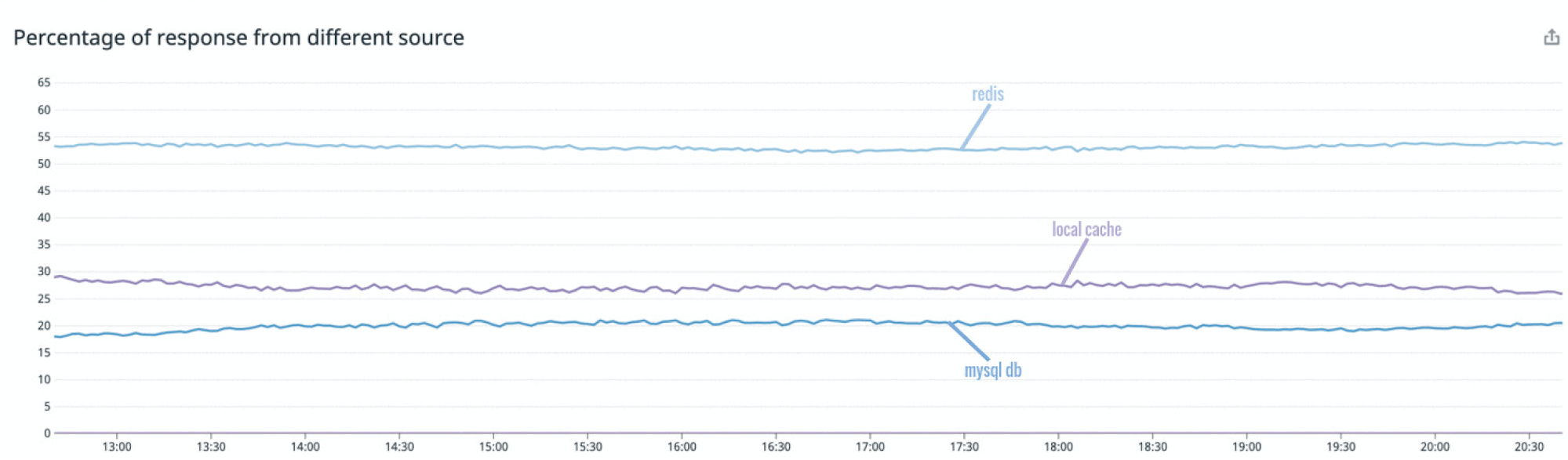
The measurement of the response source revealed that during peak hours ~25% of the requests were being served via standalone local cache, ~20% by MySQL DB, and ~55% via Redis.
The low cache hit rate is caused by the driver-partners data loading patterns: low frequency per driver over time but the high frequency in a short amount of time. When a driver-partner is a candidate for a booking or is involved in an ongoing booking, different services make multiple requests to the Drivers Data service to fetch that specific driver-partner information. The frequency of calls for a specific driver-partner reduces if he/she is not involved in the booking allocation process or is not doing any booking at the moment.
While low frequency per driver over time impacts the Redis cache hit rate, high frequency in short amounts of time mostly contributes to in-memory cache hit rate. In our investigations, we found that local caches of different nodes in the Drivers Data service cluster were making redundant calls to Redis and DB for fetching the same data that are already present in a node local cache.
Making in-memory cache available on every instance while the data is in active use, we could greatly increase the in-memory cache hit rate, and that’s what we did.
Mirror Cache Design Goals
We set the following design goals:
- Support a local least recently used (LRU) cache use-case.
- Support active cache invalidation.
- Support best effort replication between local cache instances (EC2 instances). If any instance successfully fetches the latest data from the database, then it should try to replicate or mirror this latest data across all the other nodes in the cluster. If replication fails and the item is expired or not found, then the nodes should fetch it from the database.
- Support async data replication across nodes to ensure updates for the same key happens only with more recent data. For any older updates, the current data in the cache is ignored. The ordering of cache updates is not guaranteed due to the async replication.
- Ability to handle auto-scaling.
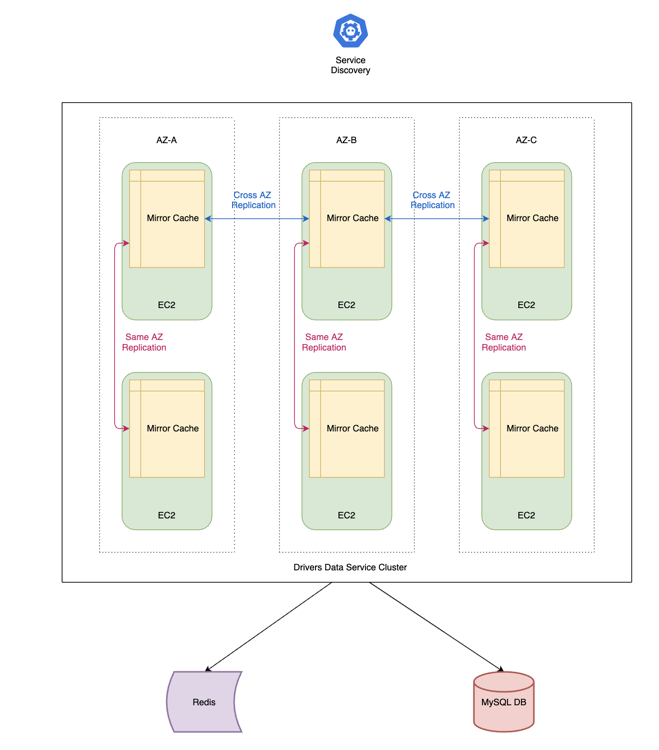
The Building Blocks
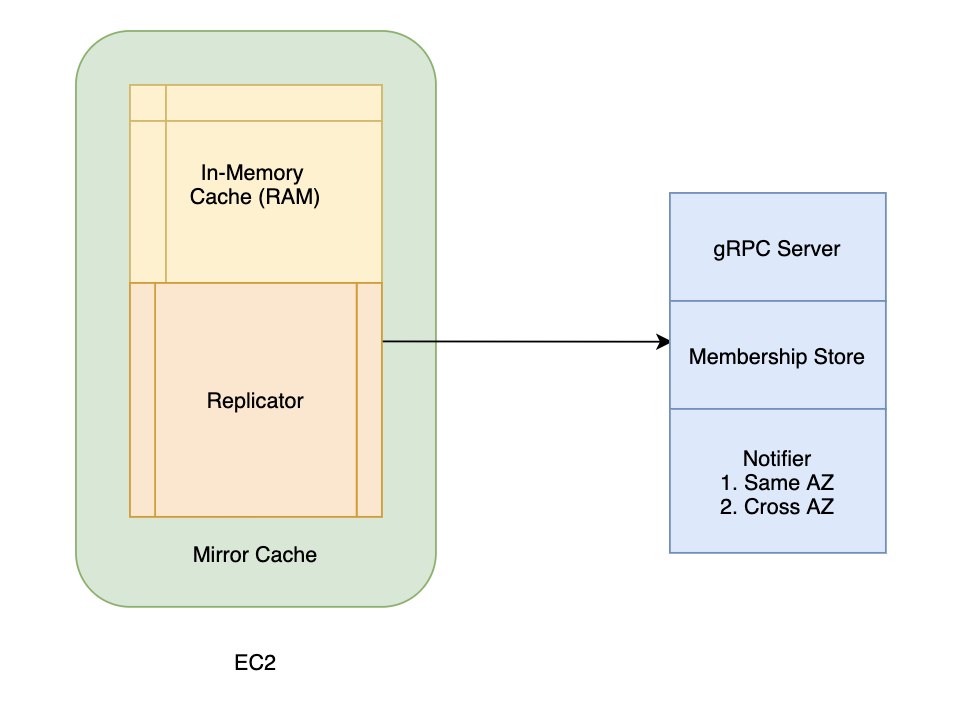
The mirror cache library runs alongside the Drivers Data service inside each of the EC2 instances of the cluster. The two main components are in-memory cache and replicator.
In-memory Cache
The in-memory cache is used to store multiple key/value pairs in RAM. There is a TTL associated with each key/value pair. We wanted to use a cache that can provide high hit ratio, memory bound, high throughput, and concurrency. After evaluating several options, we went with dgraph’s open-source concurrent caching library Ristretto as our in-memory local cache. We were particularly impressed by its use of the TinyLFU admission policy to ensure a high hit ratio.
Replicator
The replicator is responsible for mirroring/replicating each key/value entry among all the live instances of the Drivers Data service. The replicator has three main components: Membership Store, Notifier, and gRPC Server.
Membership Store
The Membership Store registers callbacks with our service discovery service to notify mirror cache in case any nodes are added or removed from the Drivers Data service cluster.
It maintains two maps - nodes in the same AZ (AWS availability zone) as itself (the current node of the Drivers Data service in which mirror cache is running) and the nodes in the other AZs.
Notifier
Each service (Drivers Data) node runs a single instance of mirror cache. So effectively, each node has one notifier.
- Combine several (key/value) pairs updates to form a batch.
- Propagate the batch updates among all the nodes in the same AZ as itself.
- Send the batch updates to exactly one notifier (node) in different AZs who, in turn, are responsible for updating all the nodes in their own AZs with the latest batch of data. This communication technique helps to reduce cross AZ data transfer overheads.
In the case of auto-scaling, there is a warm-up period during which the notifier doesn’t notify the other nodes in the cluster. This is done to minimise duplicate data propagation. The warm-up period is configurable.
gRPC Server
An exclusive gRPC server runs for mirror cache. The different nodes of the Drivers Data service use this server to receive new cache updates from the other nodes in the cluster.
Here’s the structure of each cache update entity:
message Entity {
string key = 1; // Key for cache entry.
bytes value = 2; // Value associated with the key.
Metadata metadata = 3; // Metadata related to the entity.
replicationType replicate = 4; // Further actions to be undertaken by the mirror cache after updating its own in-memory cache.
int64 TTL = 5; // TTL associated with the data.
bool delete = 6; // If delete is set as true, then mirror cache needs to delete the key from it's local cache.
}
enum replicationType {
Nothing = 0; // Stop propagation of the request.
SameRZ = 1; // Notify the nodes in the same Region and AZ.
}
message Metadata {
int64 updatedAt = 1; // Same as updatedAt time of DB.
}
The server first checks if the local cache should update this new value or not. It tries to fetch the existing value for the key. If the value is not found, then the new key/value pair is added. If there is an existing value, then it compares the updatedAt time to ensure that stale data is not updated in the cache.
If the replicationType is Nothing, then the mirror cache stops further replication. In case the replicationType is SameRZ then the mirror cache tries to propagate this cache update among all the nodes in the same AZ as itself.
Run at Scale
The behaviour of the service hasn’t changed and the requests are being served in the same manner as before. The only difference here is the replacement of the standalone local cache in each of the nodes with mirror cache. It is the responsibility of mirror cache to replicate any cache updates to the other nodes in the cluster.
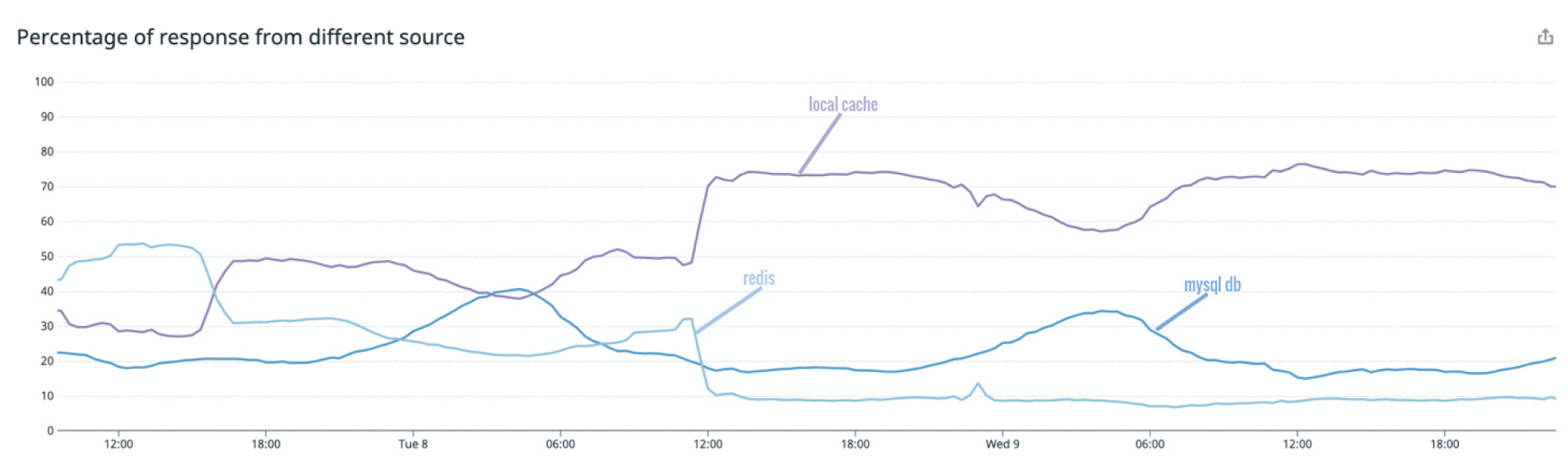
After mirror cache was fully rolled out to production, we rechecked our metrics related to the response source and saw a huge improvement. The graph showed that during peak hours ~75% of the response was from in-memory local cache. About 15% of the response was served by MySQL DB and a further 10% via Redis.
The local cache hit ratio was at 0.75, a jump of 0.5 from before and there was a 5% drop in the number of DB calls too.
Limitations and Future Improvements
Mirror cache is eventually consistent, so it is not a good choice for systems that need strong consistency.
Mirror cache stores all the data in volatile memory (RAM) and they are wiped out during deployments, resulting in a temporary load increase to Redis and DB.
Also, many new driver-partners are added every day to the Grab system, and we might need to increase the cache size to maintain a high hit ratio. To address these issues we plan to use SSD in the future to store a part of the data and use RAM only to store hot data.
Conclusion
Mirror cache really helped us scale the Drivers Data service better and serve driver-partners data to the different microservices at low latencies. It also helped us achieve our original goal of an increase in the local cache hit ratio.
We also extended mirror cache in some other services and found similar promising results.
A huge shout out to Haoqiang Zhang and Roman Atachiants for their inputs into the final design. Special thanks to the Driver Backend team at Grab for their contribution.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!