
Automating Multi-Armed Bandit testing during feature rollout
A/B testing is an experiment where a random e-commerce platform user is given two versions of a variable: a control group and a treatment group, to discover the optimal version that maximizes conversion. When running A/B testing, you can take the Multi-Armed Bandit optimisation approach to minimise the loss of conversion due to low performance.
In the traditional software development process, Multi-Armed Bandit (MAB) testing and rolling out a new feature are usually separate processes. The novel Multi-Armed Bandit System for Recommendation solution, hereafter the Multi-Armed Bandit Optimiser, proposes automating the Multi-Armed Bandit testing simultaneously while rolling out the new feature.
Advantages
- Automates the MAB testing process during new feature rollouts.
- Selects the optimal parameters based on predefined metrics of each use case, which results in an end-to-end solution without the need for user intervention.
- Uses the Batched Multi-Armed Bandit and Monte Carlo Simulation, which enables it to process large-scale business scenarios.
- Uses a feedback loop to automatically collect recommendation metrics from user event logs and to feed them to the Multi-Armed Bandit Optimiser.
- Uses an adaptive rollout method to automatically roll out the best model to the maximum distribution capacity according to the feedback metrics.
Architecture
The following diagram illustrates the system architecture.
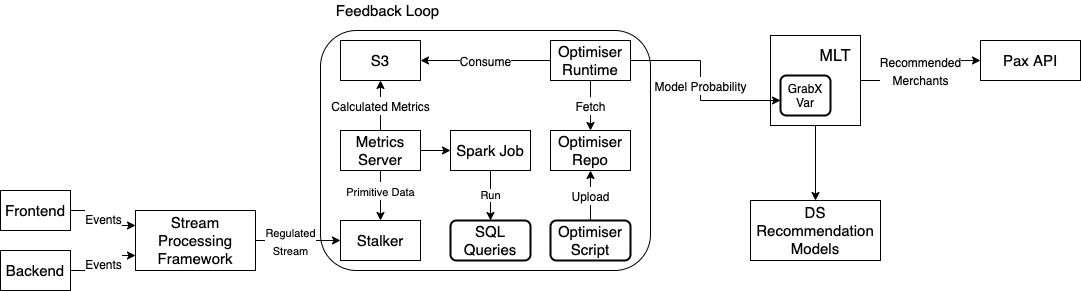 System architecture
System architecture
The novel Multi-Armed Bandit System for Recommendation solution contains three building blocks.
- Stream processing framework
A lightweight system that performs basic operations on Kafka Streams, such as aggregation, filtering, and mapping. The proposed solution relies on this framework to pre-process raw events published by mobile apps and backend processes into the proper format that can be fed into the feedback loop.
- Feedback loop
A system that calculates the goal metrics and optimises the model traffic distribution. It runs a metrics server which pulls the data from Stalker, which is a time series database that stores the processed events in the last one hour. The metrics server invokes a Spark Job periodically to run the SQL queries that computes the pre-defined goal metrics: the Clickthrough Rate, Conversion Rate and so on, provided by users. The output of the job is dumped into an S3 bucket, and is picked up by optimiser runtime. It runs the Multi-Armed Bandit Optimiser to optimise the model traffic distribution based on the latest goal metrics.
- Dynamic value receiver, or the GrabX variable
Multi-Armed Bandit Optimiser modules
The Multi-Armed Bandit Optimiser consists of the following modules:
- Reward Update
- Batched Multi-Armed Bandit Agent
- Monte-Carlo Simulation
- Adaptive Rollout
 Multi-Armed Bandit Optimiser modules
Multi-Armed Bandit Optimiser modules
The goal of the Multi-Armed Bandit Optimisation is to find the optimal Arm that results in the best predefined metrics, and then allocate the maximum traffic to that Arm.
The solution can be illustrated in the following problem. For K Arm, in which the action space A={1,2,…,K}, the Multi-Arm-Bandit Optimiser goal is to solve the one-shot optimisation problem of 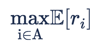 .
.
Reward Update module
The Reward Update module collects a batch of the metrics. It calculates the Success and Failure counts, then updates the Beta distribution of each Arm with the Batched Multi-Armed Bandit algorithm.
Multi-Armed Bandit Agent module
In the Multi-Armed Bandit Agent module, each Arm’s metrics are modelled as a Beta distribution which is sampled with Thompson Sampling. The Beta distribution formula is:
 .
.
The Batched Multi-Armed Bandit algorithm updates the Beta distribution with the batch metrics. The optimisation algorithm can be described in the following method.
 Batched Multi-Armed Bandit algorithm
Batched Multi-Armed Bandit algorithm
Monte-Carlo Simulation module
The Monte-Carlo Simulation module runs the simulation for N repeated times to find the best Arm over a configurable simulation window. Then, it applies the simulated results as each Arm’s distribution percentage for the next round.
To handle different scenarios, we designed two strategies.
- Max strategy: We count each Arm’s Success count’s result in Monte-Carlo Simulation, and then compute the next round distribution according to the success rate.
- Mean strategy: We average each Arm’s Beta distribution probabilities’s result in Monte-Carlo Simulation, and then compute the next round distribution according to the averaged probabilities of each Arm.
Adaptive Rollout module
The Adaptive Rollout module rolls out the sampled distribution of each Multi-Armed Bandit Arm, in the form of Multi-Armed Bandit Arm Model ID and distribution, to the experimentation platform’s configuration variable. The resulting variable is then read from the online service. The process repeats as it collects feedback from the Adaptive Rollout metrics’ results in the feedback loop.
Multi-Armed Bandit for Recommendation Solution
In the GrabFood Recommended for You widget, there are several food recommendation models that categorise lists of merchants. The choice of the model is controlled through experiments at rollout, and the results of the experiments are analysed offline. After the analysis, data scientists and product managers rectify the model choice based on the experiment results.
The Multi-Armed Bandit System for Recommendation solution improves the process by speeding up the feedback loop with the Multi-Armed Bandit system. Instead of depending on offline data which comes out at T+N, the solution responds to minute-level metrics, and adjusts the model faster.
This results in an optimal solution faster. The proposed Multi-Armed Bandit for Recommendation solution workflow is illustrated in the following diagram.
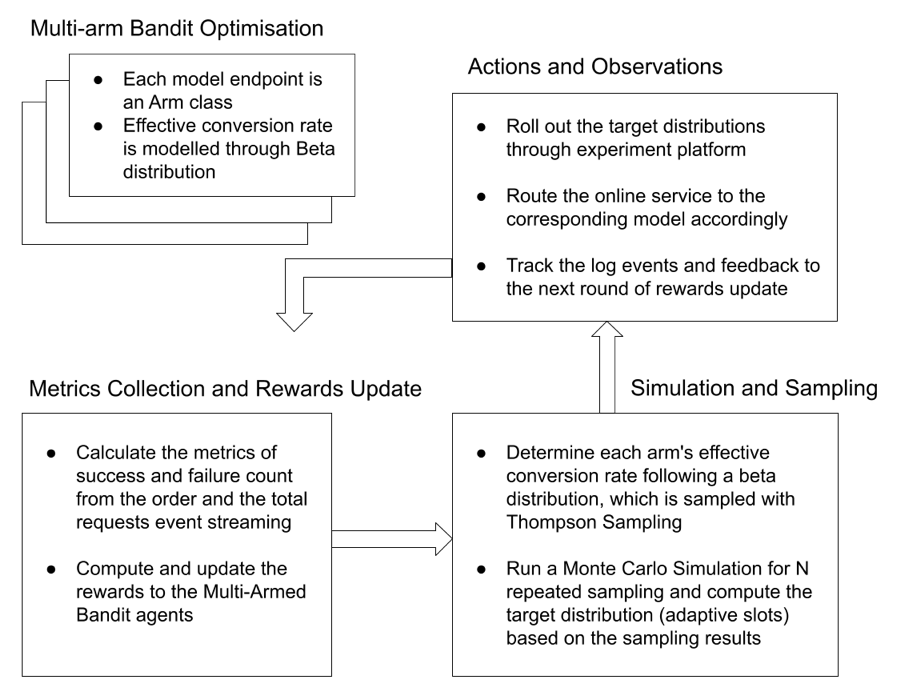 Multi-Armed Bandit for Recommendation solution workflow
Multi-Armed Bandit for Recommendation solution workflow
Optimisation metrics
The GrabFood recommendation uses the Effective Conversion Rate metrics as the optimisation objective. The Effective Conversion Rate is defined as the total number of checkouts through the Recommended for You widget, divided by the total widget viewed and multiplied by the coverage rate.
The events of views, clicks, and checkouts are collected over a 30-minute aggregation window and the coverage. A request with a checkout is considered as a success event, while a non-converted request is considered as a failure event.
Multi-Armed Bandit strategy
With the Multi-Armed Bandit Optimiser, the Beta distribution is selected to model the Effective Conversion Rate. The use of the mean strategy in the Monte-Carlo Simulation results in a more stable distribution.
Rollout policy
The Multi-Armed Bandit Optimiser uses the eater ID as the unique entity, applies a policy and assigns different percentages of eaters to each model, based on computed distribution at the beginning of each loop.
Fallback logic
The Multi-Armed Bandit Optimiser first runs model validation to ensure all candidates are suitable for rolling out. If the scheduled MAB job fails, it falls back to a default distribution that is set to 50-50% for each model.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!