 Engineering
Engineering
Optimally Scaling Kafka Consumer Applications

Earlier this year, we took you on a journey on how we built and deployed our event sourcing and stream processing framework at Grab. We’re happy to share that we’re able to reliably maintain our uptime and continue to service close to 400 billion events a week. We haven’t stopped there though. To ensure that we can scale our framework as the Grab business continuously grows, we have spent efforts optimising our infrastructure.
In this article, we will dive deeper into our Kubernetes infrastructure setup for our stream processing framework. We will cover why and how we focus on optimal scalability and availability of our infrastructure.
Quick Architecture Recap
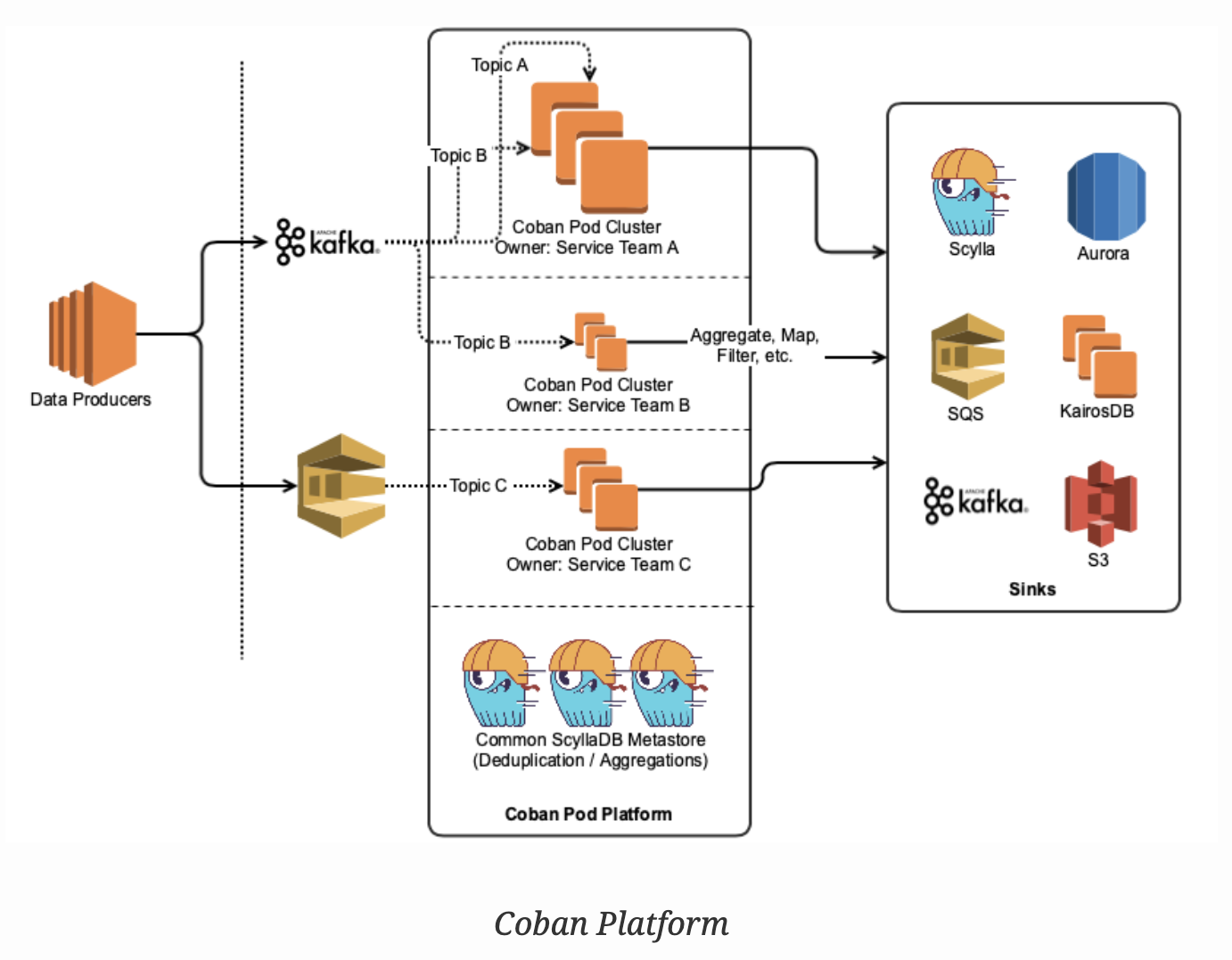
The Coban platform provides lightweight Golang plugin architecture-based data processing pipelines running in Kubernetes. These are essentially Kafka consumer pods that consume data, process it, and then materialise the results into various sinks (RDMS, other Kafka topics).
Anatomy of a Processing Pod
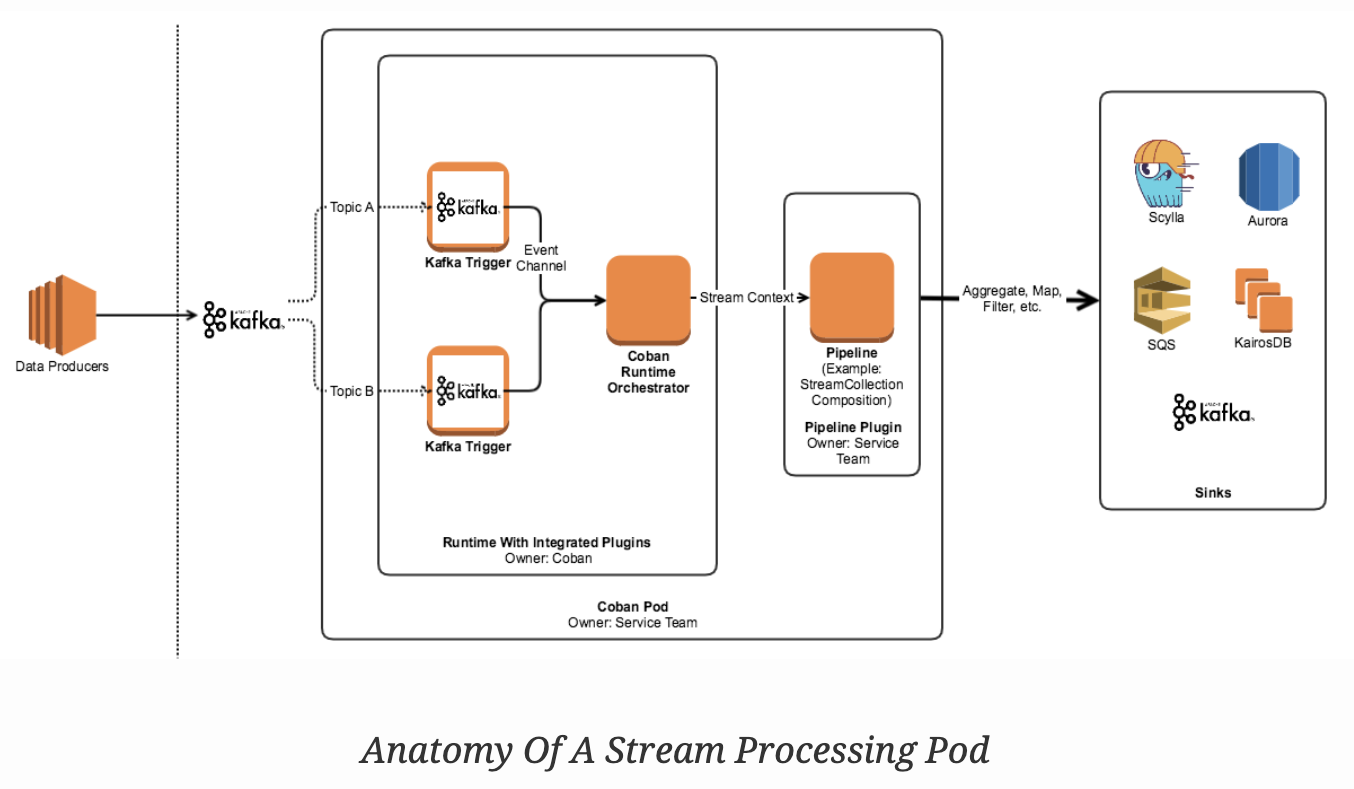
Each stream processing pod (the smallest unit of a pipeline’s deployment) has three top level components:
- Trigger: An interface that connects directly to the source of the data and converts it into an event channel.
- Runtime: This is the app’s entry point and the orchestrator of the pod. It manages the worker pools, triggers, event channels, and lifecycle events.
- Pipeline plugin: This is provided by the user, and conforms to a contract that the platform team publishes. It contains the domain logic for the pipeline and houses the pipeline orchestration defined by a user based on our Stream Processing Framework.
Optimal Scaling
We initially architected our Kubernetes setup around horizontal pod autoscaling (HPA), which scales the number of pods per deployment based on CPU and memory usage. HPA keeps CPU and memory per pod specified in the deployment manifest and scales horizontally as the load changes.
These were the areas of application wastage we observed on our platform:
- As Grab’s traffic is uneven, we’d always have to provision for peak traffic. As users would not (or could not) always account for ramps, they would be fairly liberal with setting limit values (CPU and memory), leading to resource wastage.
- Pods often had uneven traffic distribution despite fairly even partition load distribution in Kafka. The Stream Processing Framework(SPF) is essentially Kafka consumers consuming from Kafka topics, hence the number of pods scaling in and out resulted in unequal partition load per pod.
Vertically Scaling with Fixed Number of Pods
We initially kept the number of pods for a pipeline equal to the number of partitions in the topic the pipeline consumes from. This ensured even distribution of partitions to each pod providing balanced consumption. In order to abstract this from the end user, we automated the application deployment process to directly call the Kafka API to fetch the number of partitions during runtime.
After achieving a fixed number of pods for the pipeline, we wanted to move away from HPA. We wanted our pods to scale up and down as the load increases or decreases without any manual intervention. Vertical pod autoscaling (VPA) solves this problem as it relieves us from any manual operation for setting up resources for our deployment.
We just deploy the application and let VPA handle the resources required for its operation. It’s known to not be very susceptible to quick load changes as it trains its model to monitor the deployment’s load trend over a period of time before recommending an optimal resource. This process ensures the optimal resource allocation for our pipelines considering the historic trends on throughput.
We saw a ~45% reduction in our total resource usage vs resource requested after moving to VPA with a fixed number of pods from HPA.
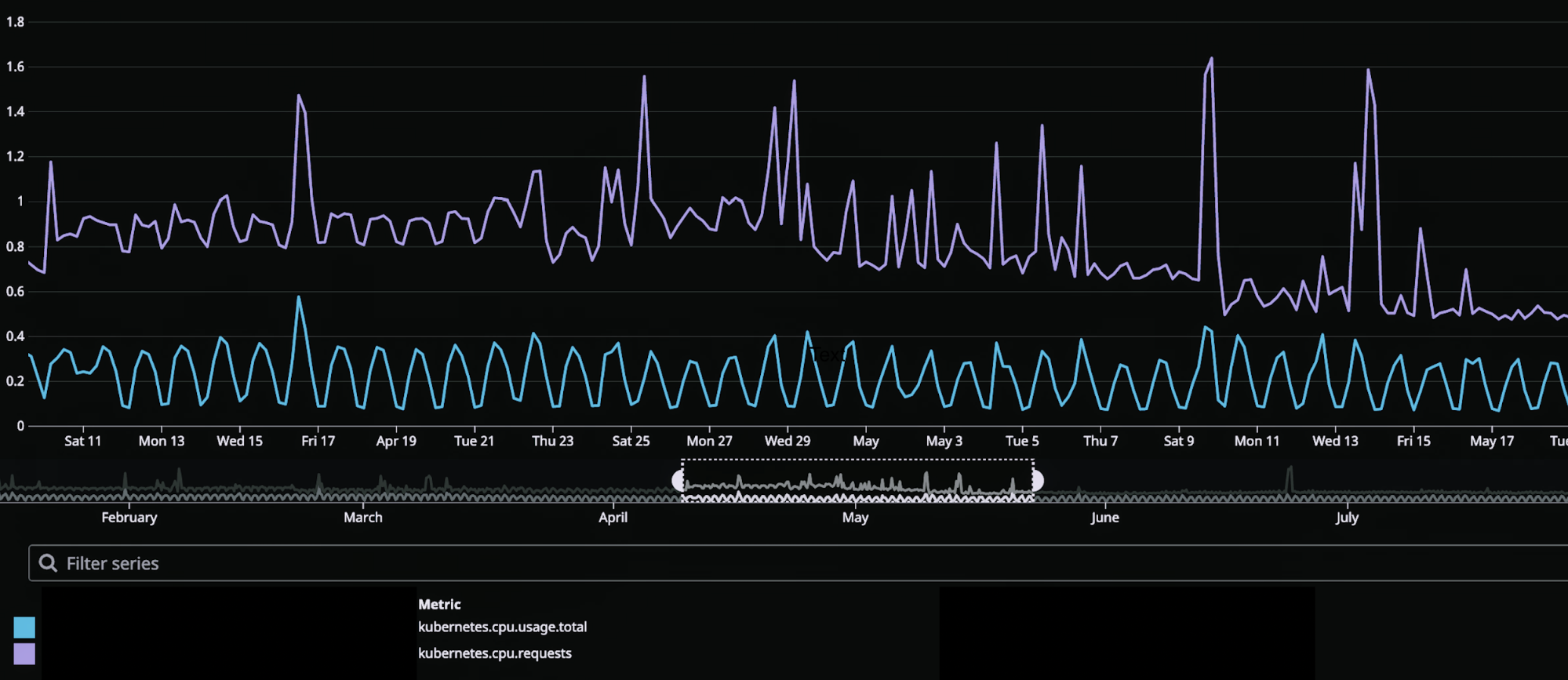
Managing Availability
We broadly classify our workloads as latency sensitive (critical) and latency tolerant (non-critical). As a result, we could optimise scheduling and cost efficiency using priority classes and overprovisioning on heterogeneous node types on AWS.
Kubernetes Priority Classes
The main cost of running EKS in AWS is attributed to the EC2 machines that form the worker nodes for the Kubernetes cluster. Running On-Demand brings all the guarantees of instance availability but it is definitely very expensive. Hence, our first action to drive cost optimisation was to include Spot instances in our worker node group.
With the uncertainty of losing a spot instance, we started assigning priority to our various applications. We then let the user choose the priority of their pipeline depending on their use case. Different priorities would result in different node affinity to different kinds of instance groups (On-Demand/Spot). For example, Critical pipelines (latency sensitive) run on On-Demand worker node groups and Non-critical pipelines (latency tolerant) on Spot instance worker node groups.
We use priority class as a method of preemption, as well as a node affinity that chooses a certain priority pipeline for the node group to deploy to.
Overprovisioning
With spot instances running we realised a need to make our cluster quickly respond to failures. We wanted to achieve quick rescheduling of evicted pods, hence we added overprovisioning to our cluster. This means we keep some noop pods occupying free space running in our worker node groups for the quick scheduling of evicted or deploying pods.
The overprovisioned pods are the lowest priority pods, thus can be preempted by any pod waiting in the queue for scheduling. We used cluster proportional autoscaler to decide the right number of these overprovisioned pods, which scales up and down proportionally to cluster size (i.e number of nodes and CPU in worker node group). This relieves us from tuning the number of these noop pods as the cluster scales up or down over the period keeping the free space proportional to current cluster capacity.
Lastly, overprovisioning also helped improve the deployment time because there is no dependency on the time required for Auto Scaling Groups (ASG) to add a new node to the cluster every time we want to deploy a new application.
Future Improvements
Evolution is an ongoing process. In the next few months, we plan to work on custom resources for combining VPA and fixed deployment size. Our current architecture setup works fine for now, but we would like to create a more tuneable in-house CRD(Custom Resource Definition) for VPA that incorporates rightsizing our Kubernetes deployment horizontally.
Authored By Shubham Badkur on behalf of the Coban team at Grab - Ryan Ooi, Karan Kamath, Hui Yang, Yuguang Xiao, Jump Char, Jason Cusick, Shrinand Thakkar, Dean Barlan, Shivam Dixit, Andy Nguyen, and Ravi Tandon.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!