 Engineering
Engineering
Plumbing At Scale
Event Sourcing and Stream Processing Pipelines at Grab

When you open the Grab app and hit book, a series of events are generated that define your personalised experience with us: booking state machines kick into motion, driver-partners are notified, reward points are computed, your feed is generated, etc. While it is important for you to know that a request has been received, a lot happens asynchronously in our back-end services.
As custodians and builders of the streaming platform at Grab operating at massive scale (think terabytes of data ingress each hour), the Coban team’s mission is to provide a NoOps, managed platform for seamless, secure access to event streams in real-time, for every team at Grab.

Streaming systems are often at the heart of event-driven architectures, and what starts as a need for a simple message bus for asynchronous processing of events quickly evolves into one that requires a more sophisticated stream processing paradigms. Earlier this year, we saw common patterns of event processing emerge across our Go backend ecosystem, including:
- Filtering and mapping stream events of one type to another
- Aggregating events into time windows and materialising them back to the event log or to various types of transactional and analytics databases
Generally, a class of problems surfaced which could be elegantly solved through an event sourcing1 platform with a stream processing framework built over it, similar to the Keystone platform at Netflix2.
This article details our journey building and deploying an event sourcing platform in Go, building a stream processing framework over it, and then scaling it (reliably and efficiently) to service over 300 billion events a week.
Event Sourcing
Event sourcing is an architectural pattern where changes to an application state are stored as a sequence of events, which can be replayed, recomputed, and queried for state at any time. An implementation of the event sourcing pattern typically has three parts to it:
- An event log
- Processor selection logic: The logic that selects which chunk of domain logic to run based on an incoming event
- Processor domain logic: The domain logic that mutates an application’s state
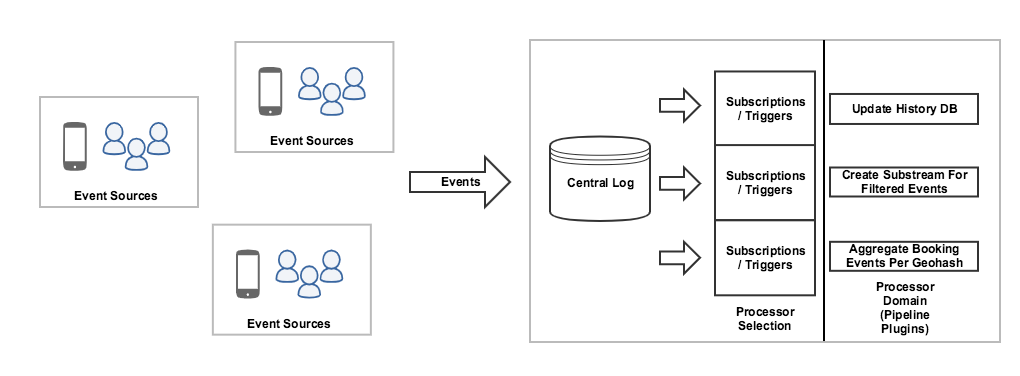
Event sourcing is a building block on which architectural patterns such as Command Query Responsibility Segregation3, serverless systems, and stream processing pipelines are built.
The Case For Stream Processing
Here are some use cases serviced by stream processing, built on event sourcing.
Asynchronous State Management
A pub-sub system allows for change events from one service to be fanned out to multiple interested subscribers without letting any one subscriber block the progress of others. Abstracting the event log and centralising it democratises access to this log to all back-end services. It enables the back-end services to apply changes from this centralised log to their own state, independent of downstream services, and/or publish their state changes to it.
Time Windowed Aggregations
Time-windowed aggregates are a common requirement for machine learning models (as features) as well as analytics. For example, personalising the Grab app landing page requires counting your interaction with various widget elements in recent history, not any one event in particular. Similarly, an analyst may not be interested in the details of a singular booking in real-time, but in building demand heatmaps segmented by geohashes. For latency-sensitive lookups, especially for the personalisation example, pre-aggregations are preferred instead of post-aggregations.
Stream Joins, Filtering, Mapping
Event logs are typically sharded by some notion of topics to logically divide events of interest around a theme (booking events, profile updates, etc.). Building bigger topics out of smaller ones, as well as smaller ones from bigger ones are common ways to compose “substreams” of the log of interest directed towards specific services. For example, a promo service may only be interested in listening to booking events for promotional bookings.
Realtime Business Intelligence
Outputs of stream processing workloads are also plugged into realtime Business Intelligence (BI) and stream analytics solutions upstream, as raw data for visualizations on operations dashboards.
Archival
For offline analytics, as well as reconciliation and disaster recovery, having an archive in a cold store helps for certain mission critical streams.
Platform Requirements
Any processing platform for event sourcing and stream processing has certain expectations around its functionality.
Scaling and Elasticity
Stream/Event Processing pipelines need to be elastic and responsive to changes in traffic patterns, especially considering that user activity (rides, food, deliveries, payments) varies dramatically during the course of a day or week. A spike in food orders on rainy days shouldn’t cause indefinite order processing latencies.
NoOps
For a platform team, it’s important that users can easily onboard and manage their pipeline lifecycles, at their preferred cadence. To scale effectively, the process of scaffolding, configuring, and deploying pipelines needs to be standardised, and infrastructure managed. Both the platform and users are able to leverage common standards of telemetry, configuration, and deployment strategies, and users benefit from a lack of infrastructure management overhead.
Multi-tenancy
Our platform has quickly scaled to support hundreds of pipelines. Workload isolation, independent processing uptime guarantees, and resource allocation and cost audit are important requirements necessitating multi-tenancy, which help amortise platform overhead costs.
Resiliency
Whether latency sensitive or latency tolerant, all workloads have certain expectations on processing uptime. From a user’s perspective, there must be guarantees on pipeline uptimes and data completeness, upper bounds on processing delays, instrumentation for alerting, and self-healing properties of the platform for remediation.
Tunable Tradeoffs
Some pipelines are latency sensitive, and rely on processing completeness seconds after event ingress. Other pipelines are latency tolerant, and can tolerate disruption to processing lasting in tens of minutes. A one size fits all solution is likely to be either cost inefficient or unreliable. Having a way for users to make these tradeoffs consciously becomes important for ensuring efficient processing guarantees at a reasonable cost. Similarly, in the case of upstream failures or unavailability, being able to tune failure modes (like wait, continue, or retry) comes in handy.
Stream Processing Framework
While basic event sourcing covers simple use cases like archival, more complicated ones benefit from a common framework that shifts the mental model for processing from per event processing to stream pipeline orchestration. Given that Go is a “paved road” for back-end development at Grab, and we have service code and bindings for streaming data in a mono-repository, we built a Go framework with a subset of capabilities provided by other streaming frameworks like Flink4.
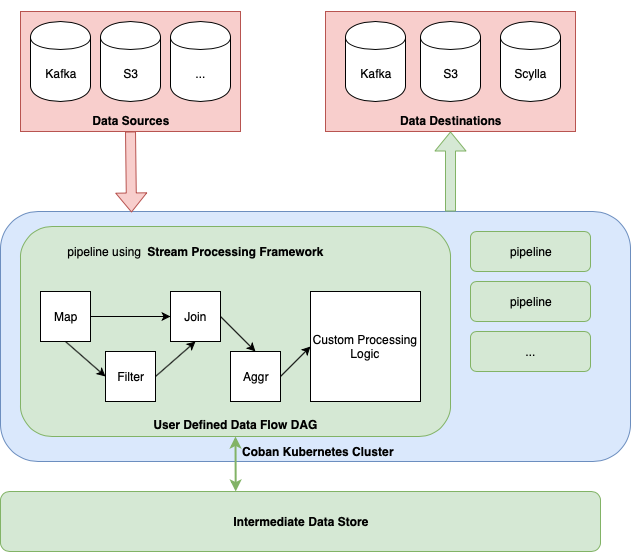
Capabilities
Some capabilities built into the framework include:
- Deduplication: Enables pipelines to idempotently reprocess data in case of rewinds/replays, and provides some processing guarantees within a time window for certain use cases including sinking to datastores.
- Filtering and Mapping: An ability to filter a source stream data and map them onto target streams.
- Aggregation: An ability to generate and execute aggregation logic such as sum, avg, max, and min in a window.
- Windowing: An ability to window processing into tumbling, sliding, and session windows.
- Join: An ability to combine two streams together with certain join keys in a window.
- Processor Chaining: Various functionalities can be chained to build more complicated pipelines from simpler ones. For example: filter a large stream into a smaller one, aggregate it over a time window, and then map it to a new stream.
- Rewind: The ability to rewind the processing logic by a few hours through configuration.
- Replay: The ability to replay archived data into the same or a separate pipeline via configuration.
- Sinks: A number of connectors to standard Grab stores are provided, with concerns of auth, telemetry, etc. managed in the runtime.
- Error Handling: Providing an easy way to indicate whether to wait, skip, and/or retry in case of upstream failures is an important tuning parameter that users need for making sensible tradeoffs in dimensions of back pressure, latency, correctness, etc.
Architecture
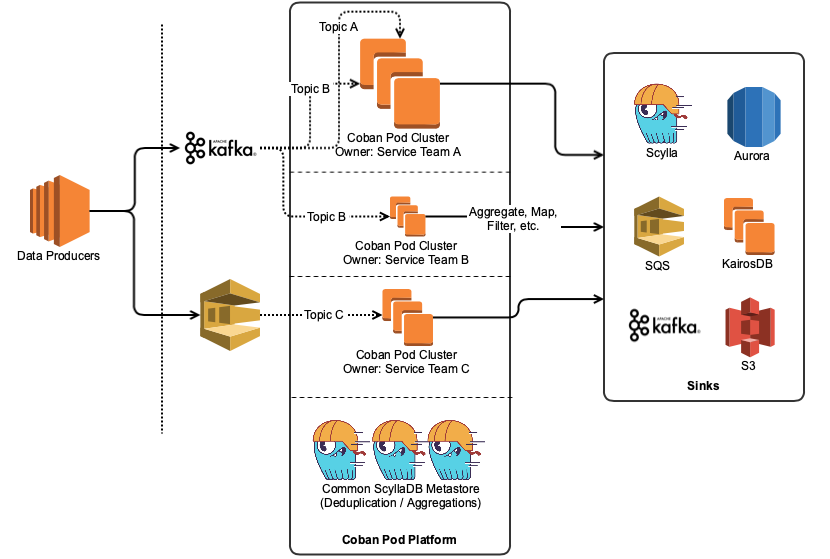
Our event log is primarily a bunch of critical Kafka clusters, which are being polled by various pipelines deployed by service teams on the platform for incoming events. Each pipeline is an isolated deployment, has an identity, and the ability to connect to various upstream sinks to materialise results into, including the event log itself. There is also a metastore available as an intermediate store for processing pipelines, so the pipelines themselves are stateless with their lifecycle completely beholden to the whims of their owners.
Anatomy of a Processing Pipeline
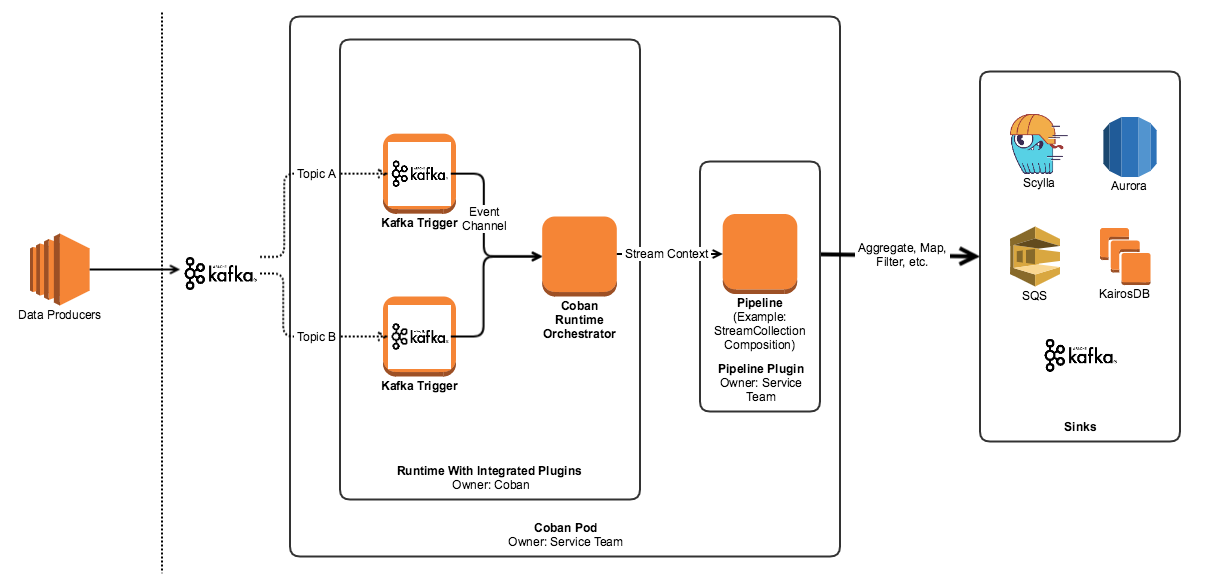
Anatomy of a Stream Processing Pod Each stream processing pod (the smallest unit of a pipeline’s deployment) has three top level components:
- Triggers: An interface that connects directly to the source of the data and converts it into an event channel.
- Runtime: This is the app’s entry point and the orchestrator of the pod. It manages the worker pools, triggers, event channels, and lifecycle events.
- The Pipeline plugin: The plugin is provided by the user, and conforms to a contract that the platform team publishes. It contains the domain logic for the pipeline and houses the pipeline orchestration defined by a user based on our Stream Processing Framework.
Deployment Infrastructure
Our deployment infrastructure heavily leverages Kubernetes on AWS. After a (pretty high) initial cost for infrastructure set up, we’ve found scaling to hundreds of pipelines a breeze with the Kubernetes provided controls. We package our stateless pipeline workloads into Kubernetes deployments, with each pod containing a unit of a stream pipeline, with sidecars that integrate them with our monitoring systems. Other cluster wide tooling deployed (usually as DaemonSets) deal with metric collection, log ingestion, and autoscaling. We currently use the Horizontal Pod Autoscaler5 to manage traffic elasticity, and the Cluster Autoscaler6 to manage worker node scaling.
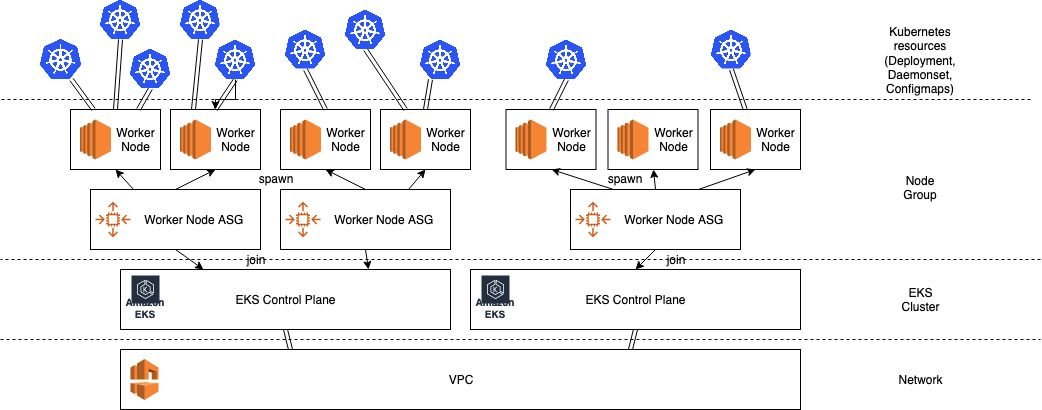
Metastore
Some pipelines require storage for use cases ranging from deduplication to stores for materialised results of time windowed aggregations. All our pipelines have access to clusters of ScyllaDB instances (which we use as our internal store), made available to pipeline authors via interfaces in the Stream Processing Framework. Results of these aggregations are then made available to backend services via our GrabStats service, which is a thin query layer over the latest pipeline results.
Compute Isolation
A nice property of packaging pipelines as Kubernetes deployments is a good degree of compute workload isolation for pipelines. While node resources of pipeline pods are still shared (and there are potential noisy neighbour issues on matters like logging throughput), the pipeline pods of various pods can be scheduled and rescheduled across a wide range of nodes safely and swiftly, with minimal impact to pods of other pipelines.
Redundancy
Stateless processing pods mean we can set up backup or redundant Kubernetes clusters in hot-hot, hot-warm, or hot-cold modes. We use this to ensure high processing availability despite limited control plane guarantees from any single cluster. (Since EKS SLAs for the Kubernetes control plane guarantee only 99.9% uptime today7.) Transparent to our users, we make the deployment systems aware of multiple available targets for scheduling.
Availability vs Cost
As alluded to in the “Platform Requirements” section, having a way of trading off availability for cost becomes important where the requirements and criticality of each processing pipeline are very different. Given that AWS spot instances are a lot cheaper8 than on-demand ones, we use user annotated Kubernetes priority classes to determine deployment targets for pipelines. For latency tolerant pipelines, we schedule them on Spot instances which are routinely between 40-90% cheaper than on demand instances on which latency sensitive pipelines run. The caveat is that Spot instances occasionally disappear, and these workloads are disrupted until a replacement node for their scheduling can be found.
What’s Next?
- Expand the ecosystem of triggers to support custom sources of data i.e. the “event log”, as well as push based (RPC driven) versus just pull based triggers
- Build a control plane for API integration with pipeline lifecycle management
- Move some workloads to use the Vertical Pod Autoscaler9 in Kubernetes instead of horizontal scaling, as most of our workloads have a limit on parallelism (which is their partition count in Kafka topics)
- Move from Go plugins for pipelines to plugins over RPC, like what HashiCorp does10, to enable processing logic in non-Go languages.
- Use either pod gossip or a service mesh with a control plane to set up quotas for shared infrastructure usage per pipeline. This is to protect upstream dependencies and the metastore from surges in event backlogs.
- Improve availability guarantees for pipeline pods by occasionally redistributing/rescheduling pods across nodes in our Kubernetes cluster to prevent entire workloads being served out of a few large nodes.
Authored By Karan Kamath on behalf of the Coban team at Grab- Zezhou Yu, Ryan Ooi, Hui Yang, Yuguang Xiao, Ling Zhang, Roy Kim, Matt Hino, Jump Char, Lincoln Lee, Jason Cusick, Shrinand Thakkar, Dean Barlan, Shivam Dixit, Shubham Badkur, Fahad Pervaiz, Andy Nguyen, Ravi Tandon, Ken Fishkin, and Jim Caputo.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Footnotes
Coban Sewu Waterfall Photo by Dwinanda Nurhanif Mujito on Unsplash
Cover Photo by tian kuan on Unsplash
-
https://martinfowler.com/eaaDev/EventSourcing.html ↩
-
https://medium.com/netflix-techblog/keystone-real-time-stream-processing-platform-a3ee651812a ↩
-
https://martinfowler.com/bliki/CQRS.html ↩
-
https://flink.apache.org ↩
-
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/ ↩
-
https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler ↩
-
https://aws.amazon.com/eks/sla/ ↩
-
https://aws.amazon.com/ec2/pricing/ ↩
-
https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler ↩
-
https://github.com/hashicorp/go-plugin ↩