
How We Prevented App Performance Degradation from Sudden Ride Demand Spikes
In Southeast Asia, when it rains, it pours. It’s a major mood dampener especially if you are stuck outside when the rain starts, you are about to have an awful day.
In the early days of Grab, if the rains came at the wrong time, like during morning rush hour, then we engineers were also in for a terrible day.
In those days, demand for Grab’s ride services grew much faster than our ability to scale our tech system and this often meant clocking late nights just to ensure our system could handle the ever-growing demand. When there’s a massive, sudden spike in ride bookings, our system often struggled to manage the load.
There were also other contributors to demand spikes, for example when public transport services broke down or when a major event such as an international concert ends and event-goers all need a ride at the same time.
Upon reflection, we realised there were two integral aspects to these incidents.
Firstly, they were localised events. The increase in demand came from a particular geographical location; in some cases a very small area. These localised events had the potential to cause so much load on our system that it impacted the experience of other users outside the geolocation.
Secondly, the underlying problem was a lack of drivers (supply) in that particular geographical area.
At Grab, our goal has always been to get everyone a ride when and where they needed it, but in this situation, it was just not possible. We needed to find a way to ensure this localised demand spike did not affect our ability to meet the needs of other users.
Enter the Spampede Filter
The Spampede (a play of the words spam and stampede) filter was inspired by another concept you may have read on this blog, circuit breakers.
In software, as in electronics, circuit breakers are designed to protect a system by short-circuiting in the face of adverse conditions.
Let’s break this down.
There are two key concepts here: short-circuiting and adverse conditions.
Firstly, short-circuiting, in this context means performing minimal processing on a particular booking, and by doing so, reducing the overall load on the system. Secondly, adverse conditions, in this, we refer to a large number of unfulfilled requests for a particular service, from a small geographical area, within a short time window. With these two concepts in mind, we devised the following process.
Spampede Design
First, we needed to track unallocated requests in a location-aware manner. To do this, we convert the requested pickup location of an unallocated request using the Geohash Integer algorithm.
After the conversion, the resulting value is an exact location. We can convert this location into a “bucket” or area by reducing the precision.
This method is by no means smart or aware of the local geography, but it is incredibly CPU efficient and requires no external resources like network API calls.
Now that we can track unallocated requests, we needed a way for the tracking to be time-aware. After all, traffic conditions, driver locations, and passenger demand are continually changing. We could have implemented something precise like a sliding window sum, but that would have introduced a lot of complexity and a significantly higher CPU and memory cost.
By using the Unix timestamp, we converted the current time to a “bucket” of time by using the straightforward formula:
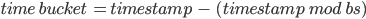
where bs is the size of the time buckets in seconds
With location and time buckets calculated, we can track the unallocated bookings using Redis. We could have used any data store, but Redis was familiar and battle-proven to us.
To do this, we first constructed the Redis key by combining the service type, the geographic location, and the time bucket. With this key, we call the INCR command, which increments the value stored in that location and returns the new value.
If the value returned is 1, this indicates that this is the first value stored for this bucket combination, and we would then make a second call, this time to EXPIRE. With this second call, we would set a time to live (TTL) on the Redis item, allowing the data to be self-cleaning.
You will notice that we are blindly calling increment and only making a second call if needed. This pattern is more efficient and resource-friendly than using a more traditional, load-check-store pattern.
The next step was the configuration. Specifically, setting how many unallocated bookings could happen in a particular location and time bucket before the circuit opened. For this, we decided on Redis again. Again, we could have used anything, but we were already using Redis and, as mentioned previously, quite familiar with it.
Finally, the last piece. We introduced code at the beginning of our booking processing, most importantly, before any calls to any other services and before any significant processing was done. This code compared the location, time, and requested service to the currently configured Spampede setting, along with the previously unallocated bookings. If the maximum had already been reached, then we immediately stopped processing the booking.
This might sound harsh- to immediately refuse a booking request without even trying to fulfil it. But the goal of the Spampede filter is to prevent excessive, localised demand from impacting all of the users of the system.
Conclusion
Reading about this as a programmer, it probably feels strange, intentionally dropping bookings and impacting the business this way.
After all, we want nothing more than to help people get to where they need to be. This process is a system safety mechanism to ensure that the system stays alive and able to do just that.
I would be remiss if I didn’t highlight the critical software-engineering takeaway here is a combination of the Observer effect and the underlying goals of the CAP theorem. Observing a system will influence the system due to the cost of instrumentation and monitoring.
Generally, the higher the accuracy or consistency of the monitoring and limits, the higher the resource cost.
In this case, we have intentionally chosen the most resource-efficient options and traded accuracy for more throughput.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!