
Preventing Pipeline Calls from Crashing Redis Clusters
Introduction
On Feb 15th, 2019, a slave node in Redis, an in-memory data structure storage, failed requiring a replacement. During this period, roughly only 1 in 21 calls to Apollo, a primary transport booking service, succeeded. This brought Grab rides down significantly for the one minute it took the Redis Cluster to self-recover. This behaviour was totally unexpected and completely breached our intention of having multiple replicas.
This blog post describes Grab’s outage post-mortem findings.
Understanding the Infrastructure
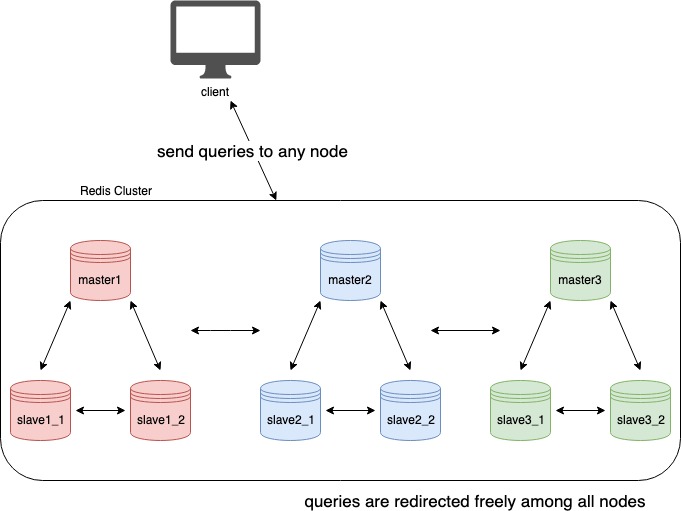
With Grab’s continuous growth, our services must handle large amounts of data traffic involving high processing power for reading and writing operations. To address this significant growth, reduce handler latency, and improve overall performance, many of our services use Redis - a common in-memory data structure storage - as a cache, database, or message broker. Furthermore, we use a Redis Cluster, a distributed implementation of Redis, for shorter latency and higher availability.
Apollo is our driver-side state machine. It is on almost all requests’ critical path and is a primary component for booking transport and providing great service for consumer bookings. It stores individual driver availability in an AWS ElastiCache Redis Cluster, letting our booking service efficiently assign bookings to drivers. It’s critical to keep Apollo running and available 24/7.
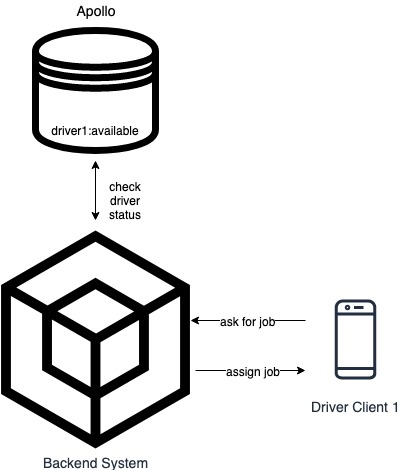
Because of Apollo’s significance, its Redis Cluster has 3 shards each with 2 slaves. It hashes all keys and, according to the hash value, divides them into three partitions. Each partition has two replications to increase reliability.
We use the Go-Redis client, a popular Redis library, to direct all written queries to the master nodes (which then write to their slaves) to ensure consistency with the database.
For reading related queries, engineers usually turn on the ReadOnly flag and turn off the RouteByLatency flag. These effectively turn on ReadOnlyFromSlaves in the Grab gredis3 library, so the client directs all reading queries to the slave nodes instead of the master nodes. This load distribution frees up master node CPU usage.
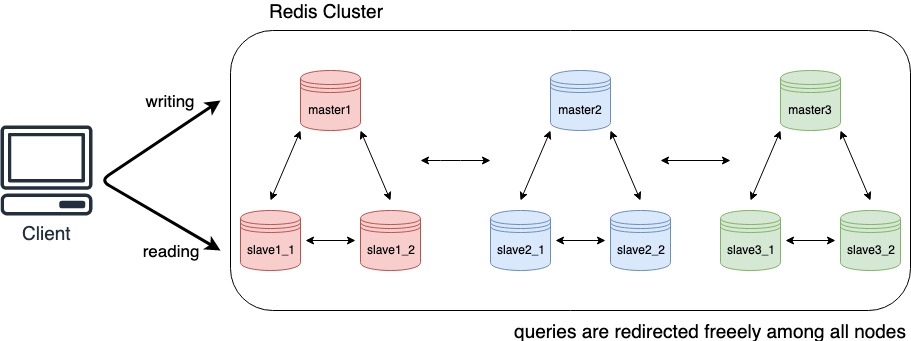
When designing a system, we consider potential hardware outages and network issues. We also think of ways to ensure our Redis Cluster is highly efficient and available; setting the above-mentioned flags help us achieve these goals.
Ideally, this Redis Cluster configuration would not cause issues even if a master or slave node breaks. Apollo should still function smoothly. So, why did that February Apollo outage happen? Why did a single down slave node cause a 95+% call failure rate to the Redis Cluster during the dim-out time?
Let’s start by discussing how to construct a local Redis Cluster step by step, then try and replicate the outage. We’ll look at the reasons behind the outage and provide suggestions on how to use a Redis Cluster client in Go.
How to Set Up a Local Redis Cluster
1. Download and install Redis from here.
2. Set up configuration files for each node. For example, in Apollo, we have 9 nodes, so we need to create 9 files like this with different port numbers(x).
// file_name: node_x.conf (do not include this line in file)
port 600x
cluster-enabled yes
cluster-config-file cluster-node-x.conf
cluster-node-timeout 5000
appendonly yes
appendfilename node-x.aof
dbfilename dump-x.rdb
3. Initiate each node in an individual terminal tab with:
$PATH/redis-4.0.9/src/redis-server node_1.conf
4. Use this Ruby script to create a Redis Cluster. (Each master has two slaves.)
$PATH/redis-4.0.9/src/redis-trib.rb create --replicas 2127.0.0.1:6001..... 127.0.0.1:6009
>>> Performing Cluster Check (using node 127.0.0.1:6001)
M: 7b4a5d9a421d45714e533618e4a2b3becc5f8913 127.0.0.1:6001
slots:0-5460 (5461 slots) master
2 additional replica(s)
S: 07272db642467a07d515367c677e3e3428b7b998 127.0.0.1:6007
slots: (0 slots) slave
replicates 05363c0ad70a2993db893434b9f61983a6fc0bf8
S: 65a9b839cd18dcae9b5c4f310b05af7627f2185b 127.0.0.1:6004
slots: (0 slots) slave
replicates 7b4a5d9a421d45714e533618e4a2b3becc5f8913
M: 05363c0ad70a2993db893434b9f61983a6fc0bf8 127.0.0.1:6003
slots:10923-16383 (5461 slots) master
2 additional replica(s)
S: a78586a7343be88393fe40498609734b787d3b01 127.0.0.1:6006
slots: (0 slots) slave
replicates 72306f44d3ffa773810c810cfdd53c856cfda893
S: e94c150d910997e90ea6f1100034af7e8b3e0cdf 127.0.0.1:6005
slots: (0 slots) slave
replicates 05363c0ad70a2993db893434b9f61983a6fc0bf8
M: 72306f44d3ffa773810c810cfdd53c856cfda893 127.0.0.1:6002
slots:5461-10922 (5462 slots) master
2 additional replica(s)
S: ac6ffbf25f48b1726fe8d5c4ac7597d07987bcd7 127.0.0.1:6009
slots: (0 slots) slave
replicates 7b4a5d9a421d45714e533618e4a2b3becc5f8913
S: bc56b2960018032d0707307725766ec81e7d43d9 127.0.0.1:6008
slots: (0 slots) slave
replicates 72306f44d3ffa773810c810cfdd53c856cfda893
[OK] All nodes agree about slots configuration.
5. Finally, we try to send queries to our Redis Cluster, e.g.
$PATH/redis-4.0.9/src/redis-cli -c -p 6001 hset driverID 100 state available updated_at 11111
What Happens When Nodes Become Unreachable?
Redis Cluster Server
As long as the majority of a Redis Cluster’s masters and at least one slave node for each unreachable master are reachable, the cluster is accessible. It can survive even if a few nodes fail.
Let’s say we have N masters, each with K slaves, and random T nodes become unreachable. This algorithm calculates the Redis Cluster failure rate percentage:
if T <= K:
availability = 100%
else:
availability = 100% - (1/(N*K - T))
If you successfully built your own Redis Cluster locally, try to kill any node with a simple command-c. The Redis Cluster broadcasts to all nodes that the killed node is now unreachable, so other nodes no longer direct traffic to that port.
If you bring this node back up, all nodes know it’s reachable again. If you kill a master node, the Redis Cluster promotes a slave node to a temp master for writing queries.
$PATH/redis-4.0.9/src/redis-server node_x.conf
With this information, we can’t answer the big question of why a single slave node failure caused an over 95% failure rate in the Apollo outage. Per the above theory, the Redis Cluster should still be 100% available. So, the Redis Cluster server could properly handle an outage, and we concluded it wasn’t the failure rate’s cause. So we looked at the client side and Apollo’s queries.
Golang Redis Cluster Client & Apollo Queries
Apollo’s client side is based on the Go-Redis Library.
During the Apollo outage, we found some code returned many errors during certain pipeline GET calls. When Apollo tried to send a pipeline of HMGET calls to its Redis Cluster, the pipeline returned errors.
First, we looked at the pipeline implementation code in the Go-Redis library. In the function defaultProcessPipeline, the code assigns each command to a Redis node in this line err:=c.mapCmdsByNode(cmds, cmdsMap).
func (c *ClusterClient) mapCmdsByNode(cmds []Cmder, cmdsMap *cmdsMap) error {
state, err := c.state.Get()
if err != nil {
setCmdsErr(cmds, err)
returnerr
}
cmdsAreReadOnly := c.cmdsAreReadOnly(cmds)
for_, cmd := range cmds {
var node *clusterNode
var err error
if cmdsAreReadOnly {
_, node, err = c.cmdSlotAndNode(cmd)
} else {
slot := c.cmdSlot(cmd)
node, err = state.slotMasterNode(slot)
}
if err != nil {
returnerr
}
cmdsMap.mu.Lock()
cmdsMap.m[node] = append(cmdsMap.m[node], cmd)
cmdsMap.mu.Unlock()
}
return nil
}
Next, since the readOnly flag is on, we look at the cmdSlotAndNode function. As mentioned earlier, you can get better performance by setting readOnlyFromSlaves to true, which sets RouteByLatency to false. By doing this, RouteByLatency will not take priority and the master does not receive the read commands.
func (c *ClusterClient) cmdSlotAndNode(cmd Cmder) (int, *clusterNode, error) {
state, err := c.state.Get()
if err != nil {
return 0, nil, err
}
cmdInfo := c.cmdInfo(cmd.Name())
slot := cmdSlot(cmd, cmdFirstKeyPos(cmd, cmdInfo))
if c.opt.ReadOnly && cmdInfo != nil && cmdInfo.ReadOnly {
if c.opt.RouteByLatency {
node, err:= state.slotClosestNode(slot)
return slot, node, err
}
if c.opt.RouteRandomly {
node:= state.slotRandomNode(slot)
return slot, node, nil
}
node, err:= state.slotSlaveNode(slot)
return slot, node, err
}
node, err:= state.slotMasterNode(slot)
return slot, node, err
}
Now, let’s try and better understand the outage.
- When a slave becomes unreachable, all commands assigned to that slave node fail.
- We found in Grab’s Redis library code that a single error in all cmds could cause the entire pipeline to fail.
- In addition, engineers return a failure in their code if
err != nil. This explains the high failure rate during the outage.
func (w *goRedisWrapperImpl) getResultFromCommands(cmds []goredis.Cmder) ([]gredisapi.ReplyPair, error) {
results := make([]gredisapi.ReplyPair, len(cmds))
var err error
for idx, cmd := range cmds {
results[idx].Value, results[idx].Err = cmd.(*goredis.Cmd).Result()
if results[idx].Err == goredis.Nil {
results[idx].Err = nil
continue
}
if err == nil && results[idx].Err != nil {
err = results[idx].Err
}
}
return results, err
}
Our next question was, “Why did it take almost one minute for Apollo to recover?”. The Redis Cluster broadcasts instantly to its other nodes when one node is unreachable. So we looked at how the client assigns jobs.
When the Redis Cluster client loads the node states, it only refreshes the state once a minute. So there’s a maximum one minute delay of state changes between the client and server. Within that minute, the Redis client kept sending queries to that unreachable slave node.
func (c *clusterStateHolder) Get() (*clusterState, error) {
v := c.state.Load()
if v != nil {
state := v.(*clusterState)
if time.Since(state.createdAt) > time.Minute {
c.LazyReload()
}
return state, nil
}
return c.Reload()
}
What happened to the write queries? Did we lose new data during that one min gap? That’s a very good question! The answer is no since all write queries only went to the master nodes and the Redis Cluster client with a watcher for the master nodes. So, whenever any master node becomes unreachable, the client is not oblivious to the change in state and is well aware of the current state. See the Watcher code.
How to Use Go Redis Safely?
Redis Cluster Client
One way to avoid a potential outage like our Apollo outage is to create another Redis Cluster client for pipelining only and with a true RouteByLatency value. The Redis Cluster determines the latency according to ping calls to its server.
In this case, all pipelining queries would read through the master nodesif the latency is less than 1ms (code), and as long as the majority side of partitions are alive, the client will get the expected results. More load would go to master with this setting, so be careful about CPU usage in the master nodes when you make the change.
Pipeline Usage
In some cases, the master nodes might not handle so much traffic. Another way to mitigate the impact of an outage is to check for errors on individual queries when errors happen in a pipeline call.
In Grab’s Redis Cluster library, the function Pipeline(PipelineReadOnly) returns a response with an error for individual reply.
func (c *clientImpl) Pipeline(ctx context.Context, argsList [][]interface{}) ([]gredisapi.ReplyPair, error) {
defer c.stats.Duration(statsPkgName, metricElapsed, time.Now(), c.getTags(tagFunctionPipeline)...)
pipe := c.wrappedClient.Pipeline()
cmds := make([]goredis.Cmder, len(argsList))
for i, args := range argsList {
cmd := goredis.NewCmd(args...)
cmds[i] = cmd
_ = pipe.Process(cmd)
}
_, _ = pipe.Exec()
return c.wrappedClient.getResultFromCommands(cmds)
}
func (w *goRedisWrapperImpl) getResultFromCommands(cmds []goredis.Cmder) ([]gredisapi.ReplyPair, error) {
results := make([]gredisapi.ReplyPair, len(cmds))
var err error
for idx, cmd := range cmds {
results[idx].Value, results[idx].Err = cmd.(*goredis.Cmd).Result()
if results[idx].Err == goredis.Nil {
results[idx].Err = nil
continue
}
if err == nil && results[idx].Err != nil {
err = results[idx].Err
}
}
return results, err
}
type ReplyPair struct {
Value interface{}
Err error
}
Instead of returning nil or an error message when err != nil, we could check for errors for each result so successful queries are not affected. This might have minimised the outage’s business impact.
Go Redis Cluster Library
One way to fix the Redis Cluster library is to reload nodes’ status when an error happens.In the go-redis library, defaultProcessor has this logic, which can be applied to defaultProcessPipeline.
In Conclusion
We’ve shown how to build a local Redis Cluster server, explained how Redis Clusters work, and identified its potential risks and solutions. Redis Cluster is a great tool to optimise service performance, but there are potential risks when using it. Please carefully consider our points about how to best use it. If you have any questions, please ask them in the comments section.