
Processing ETL tasks with Ratchet
Overview
At Grab, the Lending team is focused towards building products that help finance various segments of users, such as Passengers, Drivers, or Merchants, based on their needs. The team builds products that enable users to avail funds in a seamless and hassle-free way. In order to achieve this, multiple lending microservices continuously interact with each other. Each microservice handles different responsibilities, such as providing offers, storing user information, disbursing availed amounts to a user’s account, and many more.
In this tech blog, we will discuss what Data and Extract, Transform and Load (ETL) pipelines are and how they are used for processing multiple tasks in the Lending Team at Grab. We will also discuss Ratchet, which is a Go library, that helps us in building data pipelines and handling ETL tasks. Let’s start by covering the basis of Data and ETL pipelines.
What is a Data Pipeline?
A Data pipeline is used to describe a system or a process that moves data from one platform to another. In between platforms, data passes through multiple steps based on defined requirements, where it may be subjected to some kind of modification. All the steps in a Data pipeline are automated, and the output from one step acts as an input for the next step.

What is an ETL Pipeline?
An ETL pipeline is a type of Data pipeline that consists of 3 major steps, namely extraction of data from a source, transformation of that data into the desired format, and finally loading the transformed data to the destination. The destination is also known as the sink.
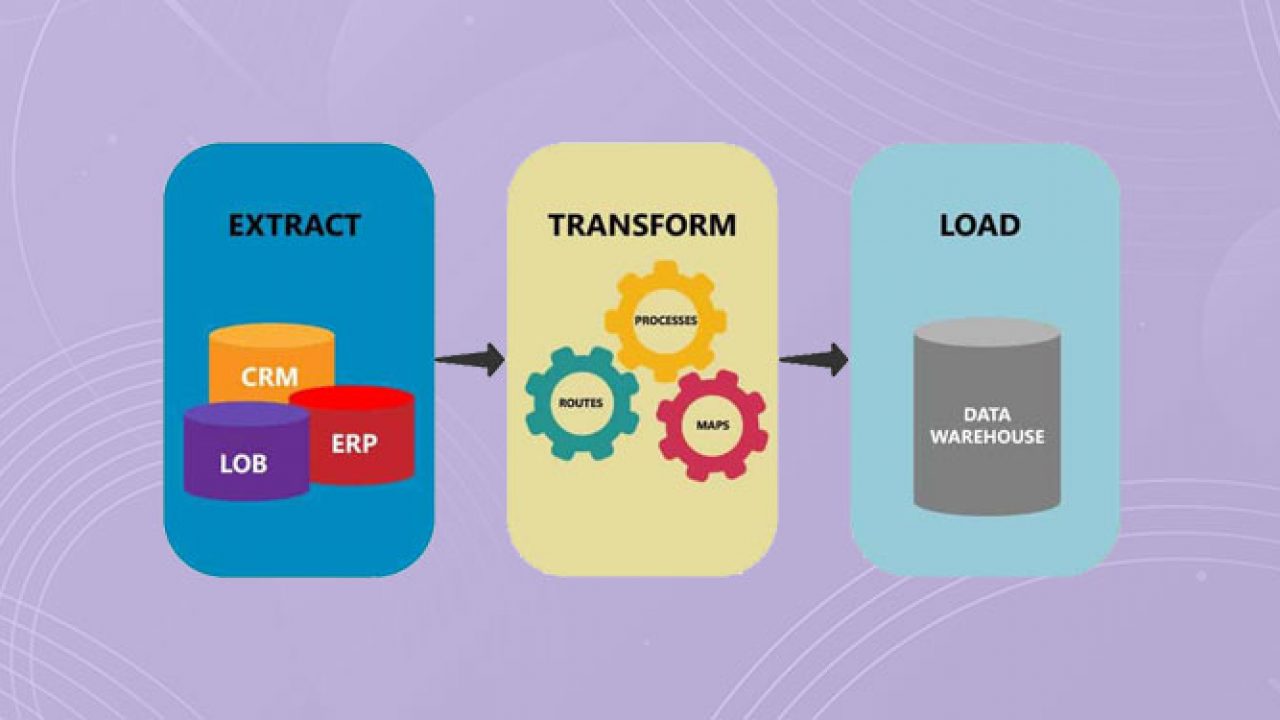
The combination of steps in an ETL pipeline provides functions to assure that the business requirements of the application are achieved.
Let’s briefly look at each of the steps involved in the ETL pipeline.
Data Extraction
Data extraction is used to fetch data from one or multiple sources with ease. The source of data can vary based on the requirement. Some of the commonly used data sources are:
- Database
- Web-based storage (S3, Google cloud, etc)
- Files
- User Feeds, CRM, etc.
The data format can also vary from one use case to another. Some of the most commonly used data formats are:
- SQL
- CSV
- JSON
- XML
Once data is extracted in the desired format, it is ready to be fed to the transformation step.
Data Transformation
Data transformation involves applying a set of rules and techniques to convert the extracted data into a more meaningful and structured format for use. The extracted data may not always be ready to use. In order to transform the data, one of the following techniques may be used:
- Filtering out unnecessary data.
- Preprocessing and cleaning of data.
- Performing validations on data.
- Deriving a new set of data from the existing one.
- Aggregating data from multiple sources into a single uniformly structured format.
Data Loading
The final step of an ETL pipeline involves moving the transformed data to a sink where it can be accessed for its use. Based on requirements, a sink can be one of the following:
- Database
- File
- Web-based storage (S3, Google cloud, etc)
An ETL pipeline may or may not have a loadstep based on its requirements. When the transformed data needs to be stored for further use, the loadstep is used to move the transformed data to the storage of choice. However, in some cases, the transformed data may not be needed for any further use and thus, the loadstep can be skipped.
Now that you understand the basics, let’s go over how we, in the Grab Lending team, use an ETL pipeline.
Why Use Ratchet?
At Grab, we use Golang for most of our backend services. Due to Golang’s simplicity, execution speed, and concurrency support, it is a great choice for building data pipeline systems to perform custom ETL tasks.
Given that Ratchet is also written in Go, it allows us to easily build custom data pipelines.
Go channels are connecting each stage of processing, so the syntax for sending data is intuitive for anyone familiar with Go. All data being sent and received is in JSON, providing a nice balance of flexibility and consistency.
Utilising Ratchet for ETL Tasks
We use Ratchet for multiple ETL tasks like batch processing, restructuring and rescheduling of loans, creating user profiles, and so on. One of the backend services, named Azkaban, is responsible for handling various ETL tasks.
Ratchet uses Data Processors for building a pipeline consisting of multiple stages. Data Processors each run in their own goroutine so all of the data is processed concurrently. Data Processors are organised into stages, and those stages are run within a pipeline. For building an ETL pipeline, each of the three steps (Extract, Transform and Load) use a Data Processor for implementation. Ratchet provides a set of built-in, useful Data Processors, while also providing an interface to implement your own. Usually, the transform stage uses a Custom Data Processor.
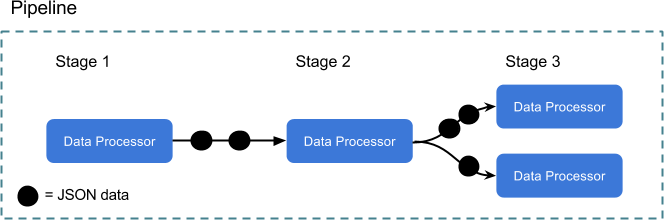
Let’s take a look at one of these tasks to understand how we utilise Ratchet for processing an ETL task.
Whitelisting Merchants Through ETL Pipelines
Whitelisting essentially means making the product available to the user by mapping an offer to the user ID. If a merchant in Thailand receives an option to opt for Cash Loan, it is done by whitelisting that merchant. In order to whitelist our merchants, our Operations team uses an internal portal to upload a CSV file with the user IDs of the merchants and other required information. This CSV file is generated by our internal Data and Risk team and handed over to the Operations team. Once the CSV file is uploaded, the user IDs present in the file are whitelisted within minutes. However, a lot of work goes in the background to make this possible.
Data Extraction
Once the Operations team uploads the CSV containing a list of merchant users to be whitelisted, the file is stored in S3 and an entry is created on the Azkaban service with the document ID of the uploaded file.
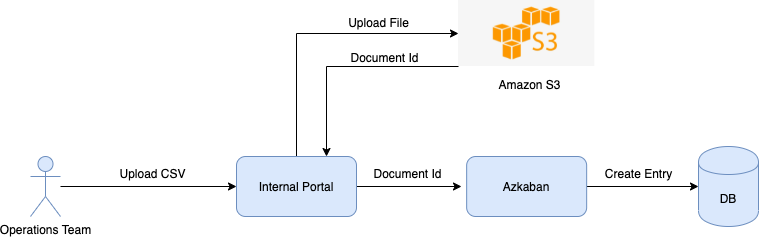
The data extraction step makes use of a Custom CSV Data Processor that uses the document ID to first create a PreSignedUrl and then uses it to fetch the data from S3. The data extracted is in bytes and we use commas as the delimiter to format the CSV data.
Data Transformation
In order to transform the data, we define a Custom Data Processor that we call a Transformer for each ETL pipeline. Transformers are responsible for applying all necessary transformations to the data before it is ready for loading. The transformations applied in the merchant whitelisting transformers are:
- Convert data from bytes to struct.
- Check for presence of all mandatory fields in the received data.
- Perform validation on the data received.
- Make API calls to external microservices for whitelisting the merchant.
As mentioned earlier, the CSV file is uploaded manually by the Operations team. Since this is a manual process, it is prone to human errors. Validation of data in the data transformation step helps avoid these errors and not propagate them further up the pipeline. Since CSV data consists of multiple rows, each row passes through all the steps mentioned above.
Data Loading
Whenever the merchants are whitelisted, we don’t need to store the transformed data. As a result, we don’t have a loadstep for this ETL task, so we just use an Empty Data Processor. However, this is just one of many use cases that we have. In cases where the transformed data needs to be stored for further use, the loadstep will have a Custom Data Processor, which will be responsible for storing the data.
Connecting All Stages
After defining our Data Processors for each of the steps in the ETL pipeline, the final piece is to connect all the stages together. As stated earlier, the ETL tasks have different ETL pipelines and each ETL pipeline consists of 3 stages defined by their Data Processors.
In order to connect these 3 stages, we define a Job Processor for each ETL pipeline. A Job Processor represents the entire ETL pipeline and encompasses Data Processors for each of the 3 stages. Each Job Processor implements the following methods:
SetSource: Assigns the Data Processor for the Extraction stage.SetTransformer: Assigns the Data Processor for the Transformation stage.SetDestination: Assigns the Data Processor for the Load stage.Execute: Runs the ETL pipeline.
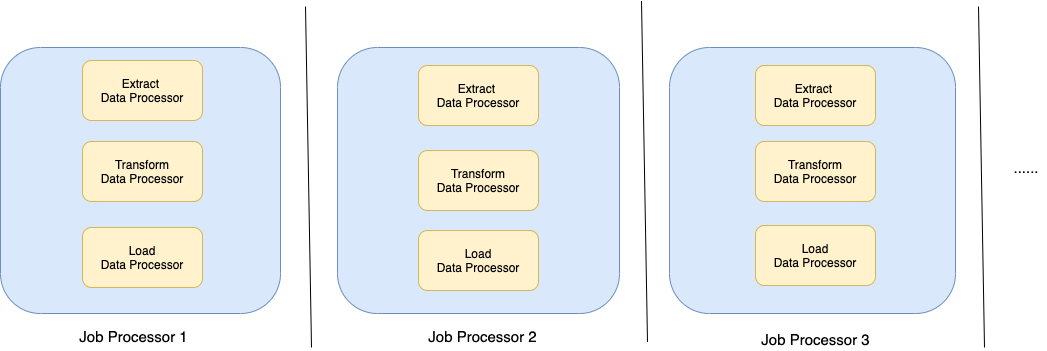
When the Azkaban service is initialised, we run the SetSource(), SetTransformer() and SetDestination() methods for each of the Job Processors defined. When an ETL task is triggered, the Execute() method of the corresponding Job Processor is run. This triggers the ETL pipeline and gradually runs the 3 stages of ETL pipeline. For each stage, the Data Processor assigned during initialisation is executed.
Conclusion
ETL pipelines help us in streamlining various tasks in our team. As showcased through the example in the above section, an ETL pipeline breaks a task into multiple stages and divides the responsibilities across these stages.
In cases where a task fails in the middle of the process, ETL pipelines help us determine the cause of the failure quickly and accurately. With ETL pipelines, we have reduced the manual effort required for validating data at each step and avoiding propagation of errors towards the end of the pipeline.
Through the use of ETL pipelines and schedulers, we at Lending have been able to automate the entire pipeline for many tasks to run at scheduled intervals without any manual effort involved at all. This has helped us tremendously in reducing human errors, increasing the throughput of the system and making the backend flow more reliable. As we continue to automate more and more of our tasks that have tightly defined stages, we foresee a growth in our ETL pipelines usage.
References
https://www.alooma.com/blog/what-is-a-data-pipeline
http://rkulla.blogspot.com/2016/01/data-pipeline-and-etl-tasks-in-go-using
https://medium.com/swlh/etl-pipeline-and-data-pipeline-comparison-bf89fa240ce9
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!