
How We Designed the Quotas Microservice to Prevent Resource Abuse
How We Designed the Quotas Microservice to Prevent Resource Abuse
As the business has grown, Grab’s infrastructure has changed from a monolithic service to dozens of microservices. And that number will soon be expressed in hundreds. As our engineering team grows in parallel, having a microservice framework provides benefits such as higher flexibility, productivity, security, and system reliability. Teams define Service Level Agreements (SLA) with their clients, meaning specification of their service’s API interface and its related performance metrics. As long as the SLAs are maintained, individual teams can focus on their services without worrying about breaking other services.
However, migrating to a microservice framework can be tricky - due to the the large number of services and having to communicate between them. Problems that are simple to solve or don’t exist for a monolithic service such as service discovery, security, load balancing, monitoring, and rate limiting are challenging for a microservice based framework. Reliable, scalable, and high performing solutions for common system level issues are essential for microservice success, and there is a Grab-wide initiative to provide those common solutions.
As an important component of the initiative, we wrote a microservice called Quotas, a highly scalable API request rate limiting solution to mitigate the problems of service abuse and cascading service failures. In this article, we discuss the challenges Quotas addresses, how we designed it, and the end results.
What Quotas Try to Address
Rate limiting is a well known concept used by many companies for years. For example, telecommunication companies and content providers frequently throttle requests from abusive users by using popular rate-limiting algorithms such as leaky bucket, fixed window, sliding log, sliding window, etc. All of these avoid resource abuse and protect important resources. Companies have also developed rate limiting solutions for inter-service communications, such as Doorman (https://github.com/youtube/doorman/blob/master/doc/design.md), Ambassador (https://www.getambassador.io/reference/services/rate-limit-service), etc, just to name a few.
Rate limiting can be enforced locally or globally. Local rate limiting means an instance accumulates API request information and makes decisions locally, with no coordination required. For example, a local rate limiting strategy can specify that each service instance can serve up to 1000 requests per second for an API, and the service instance will keep a local time-aware request counter. Once the number of received requests exceeds the threshold, it will reject new requests immediately until the next time bucket with available quota. Global rate limiting means multiple instances share the same enforcement policy. With global rate limiting, regardless of the service instance a client calls, it will be subjected to the same global API quota. Global rate limiting ensures there is a global view and it is preferred in many scenarios. In a cloud context, with auto scaling policy setup, the number of instances for a service can increase significantly during peak traffic hours. If only local rate limiting is enforced, the accumulative effect can still put great pressure on critical resources such as databases, network, or downstream services and the cumulative effects can cause service failures.
However, to support global rate limiting in a distributed environment is not easy, and it becomes even more challenging when the number of services and instances increases. To support a global view, Quotas needs to know how many requests a client service A (i.e., service A is a client of Quotas) is getting now on an endpoint comparing to the defined thresholds. If the number of requests is already over the thresholds, Quotas service should help to block a new request before service A executes its main logic. By doing that, Quotas service helps service A protect resources such as CPU, memory, database, network, and its downstream services, etc. To track the global request counts on service endpoints, a centralised data store such as Redis or Dynamo is generally used for the aggregation and decision making. In addition, decision latency and scalability become major concerns if each request needs to make a call to the rate limiting service (i.e., Quotas) to decide if the request should be throttled. And if that is the case, the rate limiting service will be on the critical path of every request and it will be a major concern for services. That is the scenario we absolutely wanted to avoid when designing Quotas service.
Designing Quotas
Quotas ensures Grab internal services can guarantee their service level agreement (SLA) by throttling “excessive” API requests made to them, thereby avoiding cascading failures . By rejecting these calls early through throttling, services can be protected from depleting critical resources such as databases, computation resources, etc.
The two main goals for Quotas are:
-
Help client services throttle excessive API requests in a timely fashion.
-
Minimise latency impacts on client services, i.e., client services should only see negligible latency increase on API response time.
We followed these design guidelines:
-
Providing a thin client implementation. Quotas service should keep most of the processing logic at the service side. Once we release a client SDK, it’s very hard to track who’s using what version and to update every client service with a new client SDK version. Also, more complex client side logic increases the chances of introducing bugs.
-
To allow scaling of Quotas service, we use an asynchronous processing pipeline instead of a synchronous one (i.e., client service makes calls Quotas for every API request). By asynchronously processing events, a client service can immediately decide whether to throttle an API request when it comes in, without delaying the response too much.
-
Allowing for horizontal scaling through config changes. This is very important since the goal is to onboard all Grab internal services.
Figure 1 is a high-level system diagram for Quotas’ client and server side interactions. Kafka sits at the core of the system design. Kafka is an open-source distributed streaming platform under the Apache license and it’s widely adopted by the industry (https://kafka.apache.org/intro). Kafka is used in Quotas system design for the following purposes:
-
Quotas client services (i.e., services B and C in Figure 1) send API usage information through a dedicated Kafka topic and Quotas service consumes the events and performs its business logic.
-
Quotas service sends rate-limiting decisions through application-specific Kafka topics and the Quotas client SDKs running on the client service instances consume the rate-limiting events and update the local in-memory cache for rate-limiting decisions. For example, Quotas service uses topic names such as “rate-limiting-service-b” for rate-limiting decisions with service B and “rate-limiting-service-c” for service C.
-
An archiver is running with Kafka to archive the events to AWS S3 buckets for additional analysis.
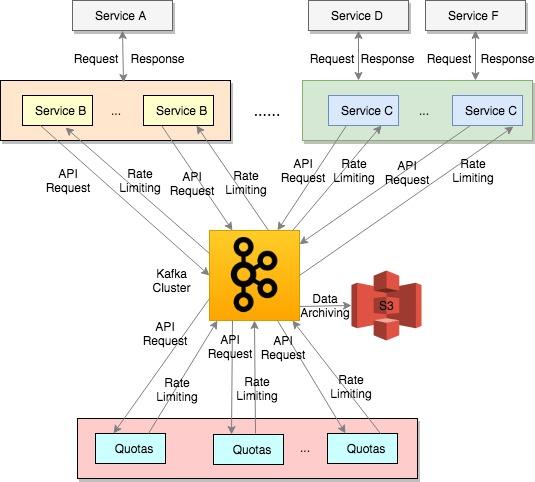 Figure 1: Quotas High-level System Design
Figure 1: Quotas High-level System Design
The details of Quotas client side logic is shown in Figure 2 using service B as an example. As it shows, when a request comes in (e.g., from service A), service B will perform the following logic:
- Quotas middleware running with service B
- intercepts the request and calls Quotas client SDK for the rate limiting decision based on API and client information.
- If it throttles the request, service B returns a response code indicating the request is throttled.
- If it doesn't throttle the request, service B handles it with its normal business logic.
- asynchronously sends the API request information to a Kafka topic for processing.
- intercepts the request and calls Quotas client SDK for the rate limiting decision based on API and client information.
- Quotas client SDK running with service B
- consumes the application-specific rate-limiting Kafka stream and updates its local in-memory cache for new rate-limiting decisions. For example, if the previous decision is true (i.e., enforcing rate limiting), and the new decision from the Kafka stream is false, the local in-memory cache will be updated to reflect the change. After that, if a new request comes in from service A, it will be allowed to go through and served by service B.
- provides a single public API to read the rate limiting decision based on API and client information. This public API reads the decisions from its local in-memory cache.
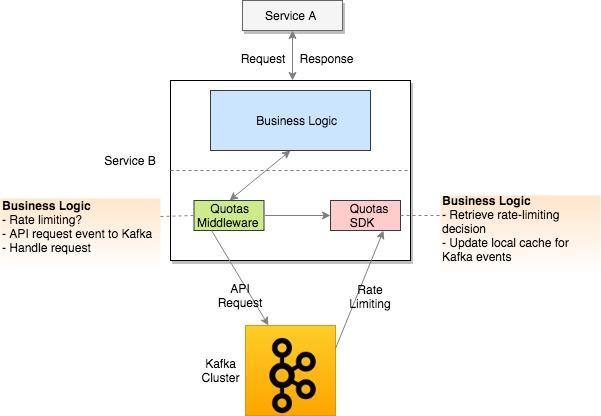 Figure 2: Quotas Client Side Logic
Figure 2: Quotas Client Side Logic
Figure 3 shows the details of Quotas server side logic. It performs the following business logic:
-
Consumes the Kafka stream topic for API request information
-
Performs aggregations on the API usages
-
Stores the stats in a Redis cluster periodically
-
Makes a rate-limiting decision periodically
-
Sends the rate-limiting decisions to an application-specific Kafka stream
-
Sends the stats to DataDog for monitoring and alerting periodically
In addition, an admin UI is available for service owners to update thresholds and the changes are picked up immediately for the upcoming rate-limiting decisions.
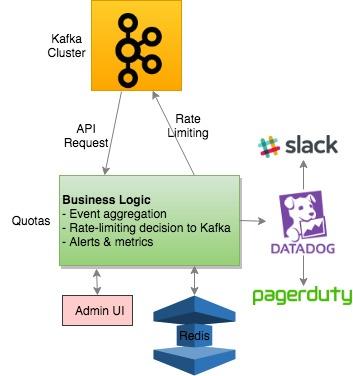 Figure 3: Quotas Server Side Logic
Figure 3: Quotas Server Side Logic
Implementation Decisions and Optimisations
On the client service side (service B in the above diagrams), the Quotas client SDK is initialised when service B instance is initialised. The Quotas client SDK is a wrapper that consumes Kafka rate-limiting events and writes/reads the in-memory cache. It exposes a single API to check the rate-limiting decisions on a client with a given API method. Also, service B is hooked up with Quotas middleware to intercept API requests. Internally, it calls the Quotas client SDK API to determine if it should allow/reject the requests before the actual business logic. Currently, Quotas middleware supports both gRPC and REST protocols.
Quotas utilises a company-wide streaming solution called Sprinkler for the Kafka stream Producer and Consumer implementations. It provides streaming SDKs built on top of sarama (an MIT-license Go library for Apache Kafka), providing asynchronous event sending/consuming, retry, and circuit breaking capabilities.
Quotas provides throttling capabilities based on the sliding window algorithm on the 1-second and 5-second levels. To support extremely high TPS demands, most of Quotas intermediate operations are designed to be done asynchronously. Internal benchmarks show the delay for enforcing a rate-limiting decision is up to 200 milliseconds. By combining 1-second and 5-second level settings, client services can more effectively throttle requests.
During system implementation, we find that if Quotas instances make a call to the Redis cluster every time it receives an event from the Kafka API usage stream, the Redis cluster will quickly become a bottleneck due to the amount of calculations. By aggregating API usage stats locally in-memory and calling Redis instances periodically (i.e., every 50 ms), we can significantly reduce Redis usage and still keep the overall decision latency at a relatively low level. In addition, we designed the hash keys in a way to make sure requests are evenly distributed across Redis instances.
Evaluation and Benchmarks
We did multiple rounds of load tests, both before and after launching Quotas, to evaluate its performance and find potential scaling bottlenecks. After the optimisation efforts, Quotas now gracefully handles 200k peak production TPS. More importantly, critical system resource usage for Quotas’ application server, Redis and Kafka are still at a relatively low level, suggesting that Quotas can support much higher TPS before the need to scale up.
Quotas current production settings are:
-
12 c5.2xlarge (8 vCPU, 16GB) AWS EC2 instances
-
6 cache.m4.large (2 vCPU, 6.42GB, master-slave) AWS ElasticCaches
-
Shared Kafka cluster with other application topics
Figures 4 & 5 show a typical day’s CPU usage for the Quotas application server and Redis Cache respectively. With 200k peak TPS, Quotas handles the load with peak application server CPU usage at about 20% and Redis CPU usage of 15%. Due to the nature of Quotas data usage, most of the data stored in Redis cache is time sensitive and stored with time-to-live (TTL) values.
However, because of how Redis expires keys (https://redis.io/commands/expire) and the amount of time-sensitive data Quotas stores in Redis, we have implemented a proprietary cron job to actively garbage collect expired Redis keys. By running the cron job every 15 minutes, Quotas keeps the Redis memory usage at a low level.
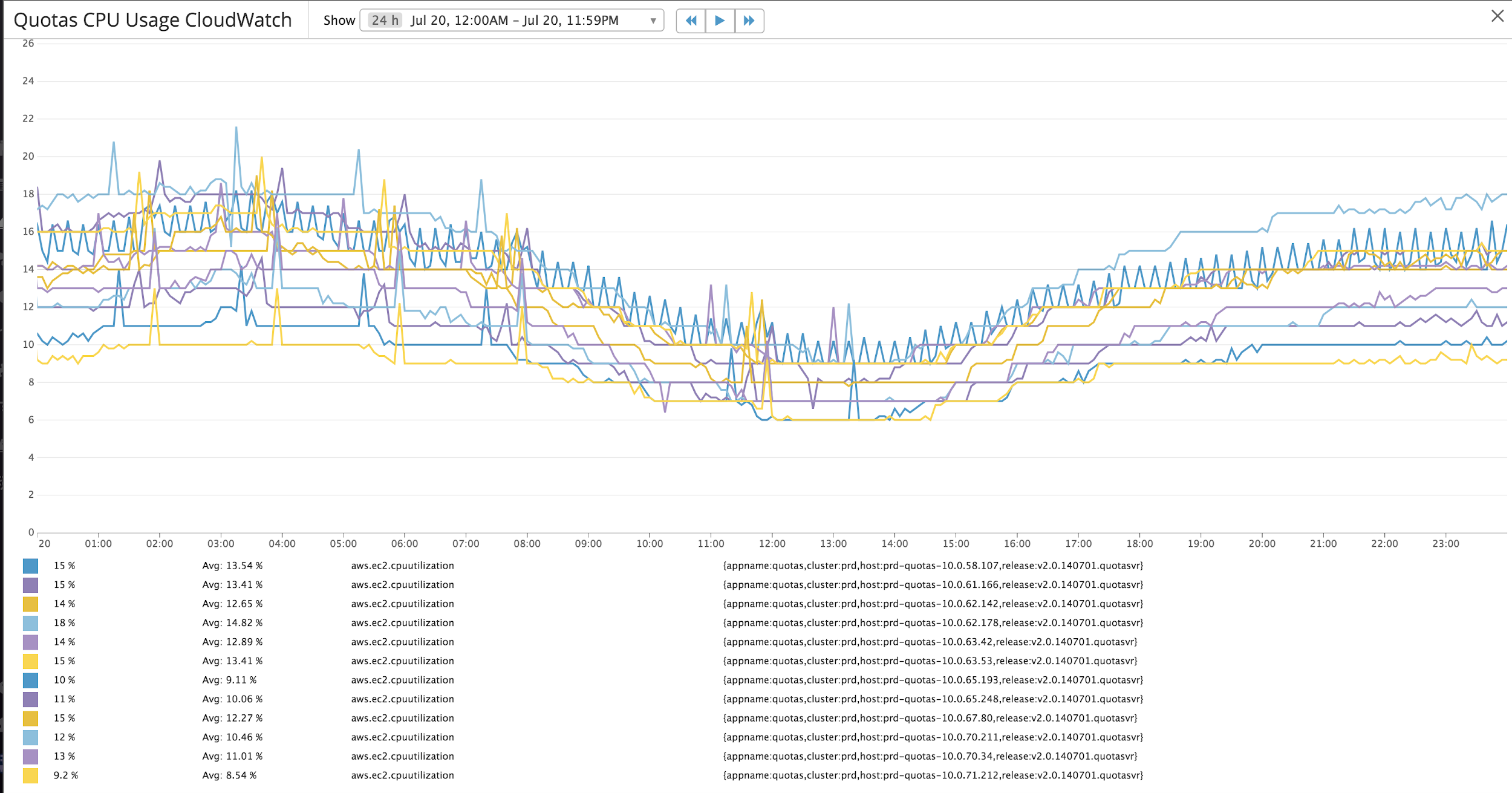 Figure 4: Quotas CPU Usage
Figure 4: Quotas CPU Usage
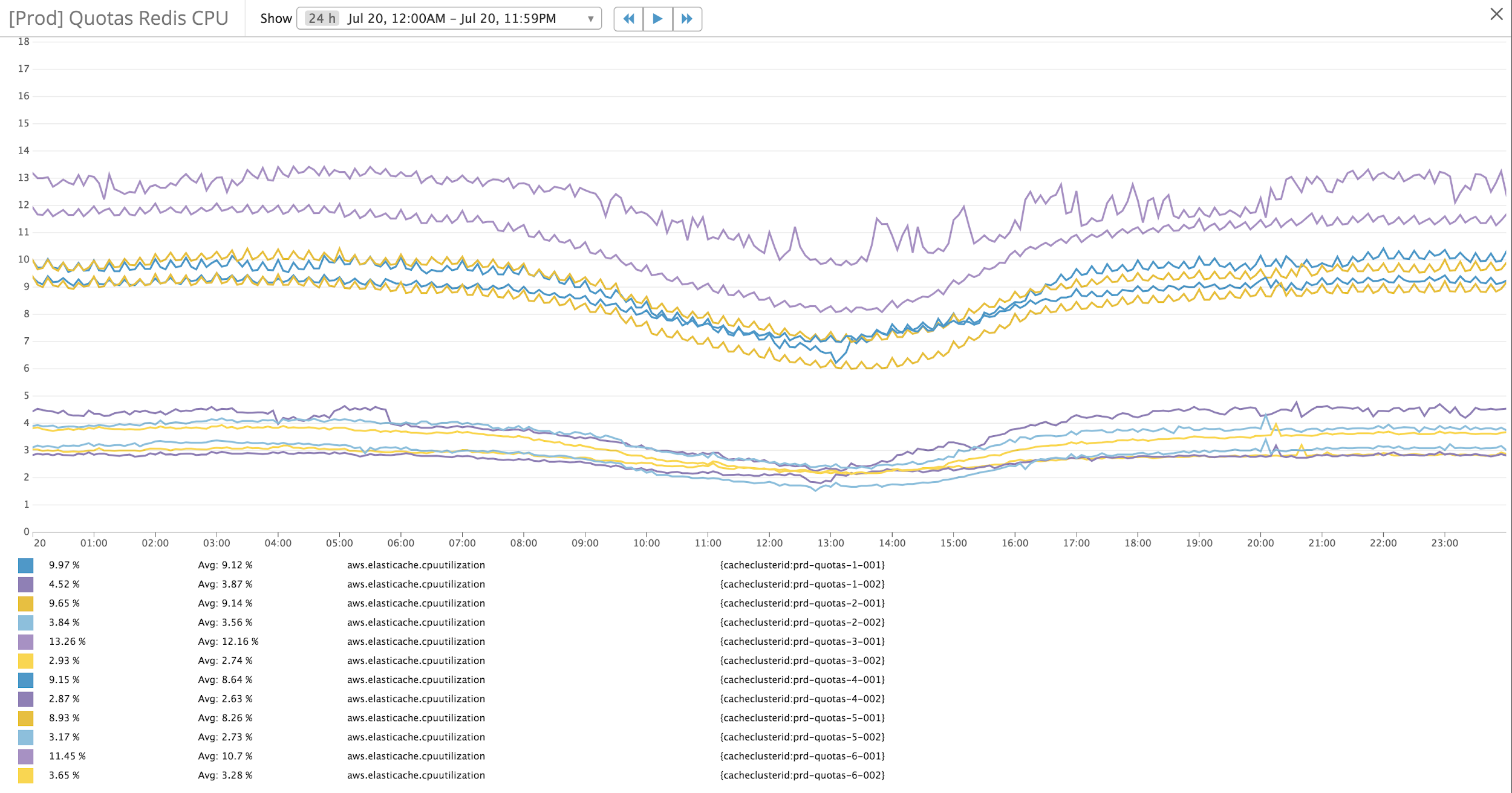 Figure 5: Quotas Redis CPU Usage
Figure 5: Quotas Redis CPU Usage
We have conducted load tests to identify the potential issues for scaling Quotas. The tests have shown that we can horizontally scale Quotas to support extremely high TPS using only configuration changes:
-
Kafka is well known for its high throughput, low-latency, high scalability characteristics. By either increasing the number of partitions on Quotas API usage topic or adding more Kafka nodes, the system can evenly distribute and handle additional load.
-
All Quotas application servers form a consumer group (CG) to consume the Kafka API usage topic (partitioned based on the number of instance expectations). Whenever an instance starts or goes offline, the topic partitions are re-distributed among the application servers. This allows balanced topic partition consumptions and thus somewhat evenly distributed application server CPU and memory usages.
-
We have also implemented a consistent hashing based algorithm to support multiple Redis instances. It supports easy Redis instances addition or removal by configuration changes. With well chosen hash keys, load can be evenly distributed to the Redis instances.
With the above design and implementations, all the critical Quotas components can be easily scaled and extended when a bottleneck occurs either at Kafka, application server, or Redis levels.
Roadmap for Quotas
Quotas is currently used by more than a dozen internal Grab services, and soon all Grab internal services will use it.
Quotas is part of the company-wide ServiceMesh effort to handle service discovery, load balancing, circuit breaker, retry, health monitoring, rate-limiting, security, etc. consistently across all Grab services.