How we reduced peak memory and CPU usage of the product configuration management SDK
Introduction
GrabX is Grab’s central platform for product configuration management. It has the capacity to control any component within Grab’s backend systems through configurations that are hosted directly on GrabX.
GrabX clients read these configurations through an SDK, which reads the configurations in a way that’s asynchronous and eventually consistent. As a result, it takes about a minute for any updates to the configurations to reach the client SDKs.
In this article, we discuss our analysis and the steps we took to reduce the peak memory and CPU usage of the SDK.
Observations on potential SDK improvements
Our GrabX clients noticed that the GrabX SDK tended to require high memory and CPU usage. From this, we saw opportunities for further improvements that could:
- Optimise the tail latencies of client services.
- Enable our clients to use their resources more effectively.
- Reduce operation costs and improve the efficiency of using the GrabX SDK.
- Accelerate the adoption of GrabX by Grab’s internal services.
SDK design
At a high-level, creating, updating, and serving configuration values via the GrabX SDK involved the following process:
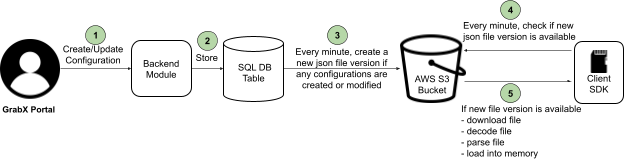
- The process begins when GrabX clients either create or update configurations. This is done through the GrabX web portal or by making an API call.
- Once the configurations are created or updated, the GrabX backend module takes over. It stores the new configuration into an SQL database table.
-
The GrabX backend ensures that the latest configuration data is available to client SDKs.
a. The GrabX backend checks every minute for any newly created or updated configurations.
b. If there are new or updated configurations, GrabX backend creates a new JSON file. This file contains all existing and newly created configurations. It’s important to note that all configurations across all services are stored in a single JSON file.
c. The backend module uploads this newly created JSON file to an AWS S3 bucket.
d. The backend module assigns a version number to the new JSON file and updates a text file in the AWS S3 bucket. This text file stores the latest JSON file version number. The client SDK refers to this version file to check if a newer version of the configuration data is available.
- The client SDK performs a check on the version file every minute to determine if a newer version is available. This mechanism is crucial to maintain data consistency across all instances of a service. If any instance fell out of sync, it would be brought back in sync within a minute.
- If a new version of the configuration JSON file is available, the client SDK downloads this new file. Following the download, it loads the configuration data into memory. Storing the configuration data in memory reduces the read latency for the configurations.
Areas of improvement for existing SDK design
In this section we outline the areas of improvement we identified within the SDK design.
Service-based data partitioning
We saw an opportunity for service-based data partitioning. The configuration data for all services was consolidated into a single JSON file. Upon studying the data read patterns of client services, we observed that most services primarily needed to access configuration data specific to their own service. However, the present design required storing configuration data for all other services. This resulted in unnecessary memory consumption.
Retaining only new version of configuration in the same file
By using a single JSON file for storing old and new configuration data, we saw a significant increase in the size of the JSON file.
The SDK only needs the full data when it starts; the more common case is that it needs to stay updated with the latest configuration. Even in that scenario, the SDK needed to fetch a complete new JSON file every minute no matter the size of the updates. Consequently, the process of downloading, decoding, and loading high volumes of data at a high frequency (every minute) caused the client SDK to spike in memory and CPU usage.
More efficient JSON decoding
An additional factor which contributed to memory and CPU usage during the decoding phase was the inefficiency of the default JSON decode library to decode this large (>100MB) JSON file. Decoding this JSON file was heavy on available CPU resources, which tended to starve the service of its ability to handle incoming requests. This manifested as increasing the P99 latency of the service.
Implemented solution
We proposed modifications to the existing SDK design, which we discuss in this section.
Partition data by service
The proposed solution involved partitioning the data based on services. We chose this approach because a single configuration typically belonged to a single service, and most services primarily needed to read configurations that pertained to their own service.
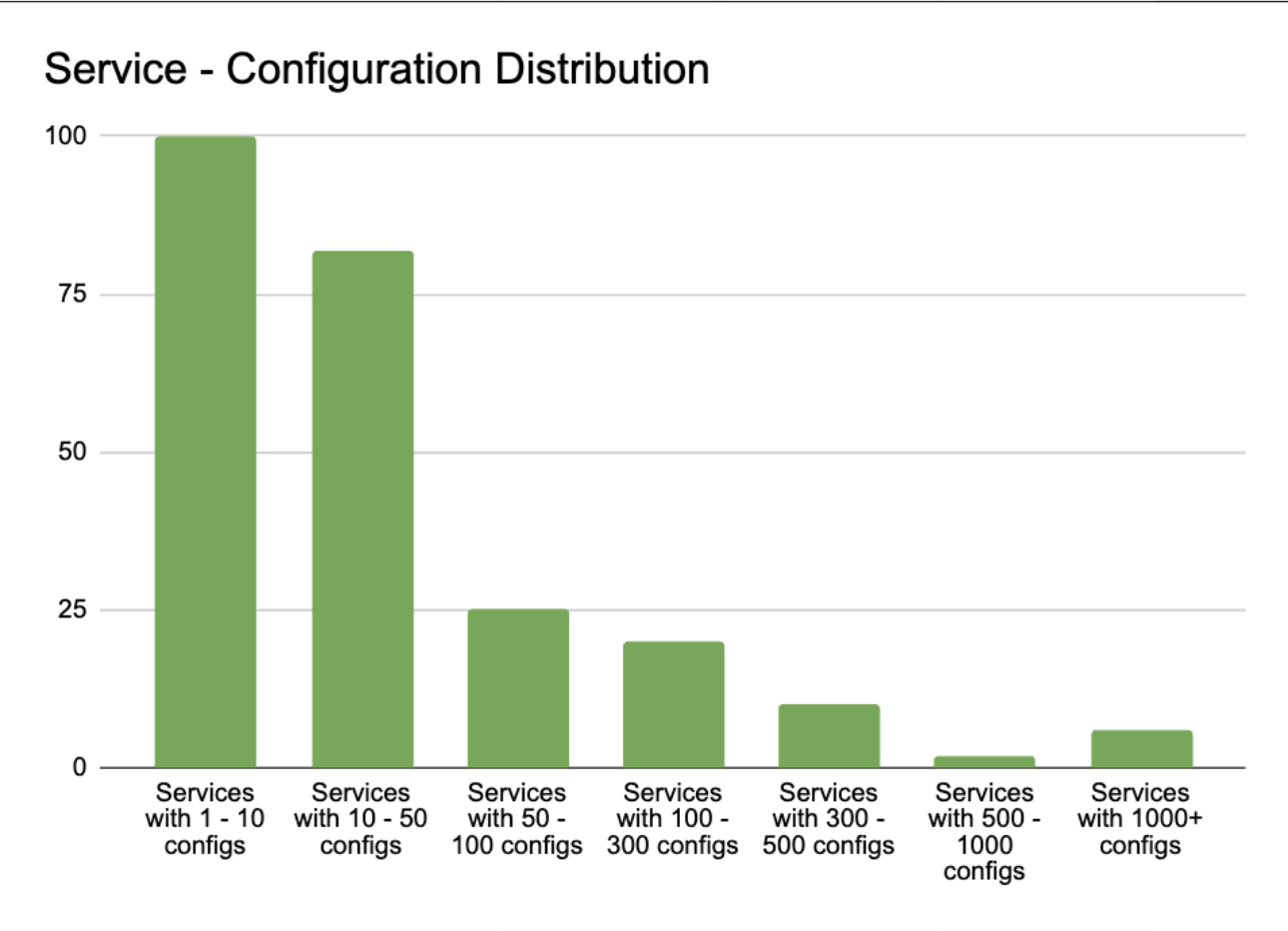
Upon analysing the distribution of service-configuration, we discovered that 98% of client services required less than 1% of the total configuration data. Despite this, they were required to maintain and reload 100% of the configuration data. Furthermore, the service with the largest number of configurations only required 20% of the total configuration data.
Therefore, we proposed a shift towards service-based partitioning of configuration data. This allowed individual client services to access only the data they needed to read.
Create separate JSON files for each configuration
Our proposal also included creating a separate JSON file for each configuration in a service. Previously, all data was stored in a single JSON file housed in an AWS S3 bucket, which supported a maximum of 3,500 write/update requests and 5,500 read requests per second.
By storing each configuration in a separate JSON file, we were able to create a different S3 prefix for each configuration file. These S3 prefixes helped us to maximise S3 throughput by enhancing the read/write performance for each configuration. AWS S3 can handle at least 3,500 PUT/COPY/POST/DELETE requests or 5,500 GET/HEAD requests per second for each partitioned Amazon S3 prefix.
Therefore, with each configuration’s data stored in a separate S3 file with a different prefix, the GrabX platform could achieve a throughput of 5,500 read requests and 3,500 write/update requests per second per configuration. This was beneficial for boosting read/write capacity when needed.
Implement a service-level changelog
We proposed to create a changelog file at the service level. In other words, a changelog file was created for each service. This file was used to keep track of the latest update version, as well as previous service configuration update versions. This file also recorded the configurations which were created or updated in each version. This enables the SDK to accurately identify the configurations that were created or updated in each update version. This was useful to update the specific configurations belonging to a service on the client side.
Implement service-based SDK
We proposed that SDK client services should be allowed to subscribe to a list of services for which they need to read configuration data. The SDK was initialised with data of the subscribed services and received updates only for configurations corresponding to the subscribed services.
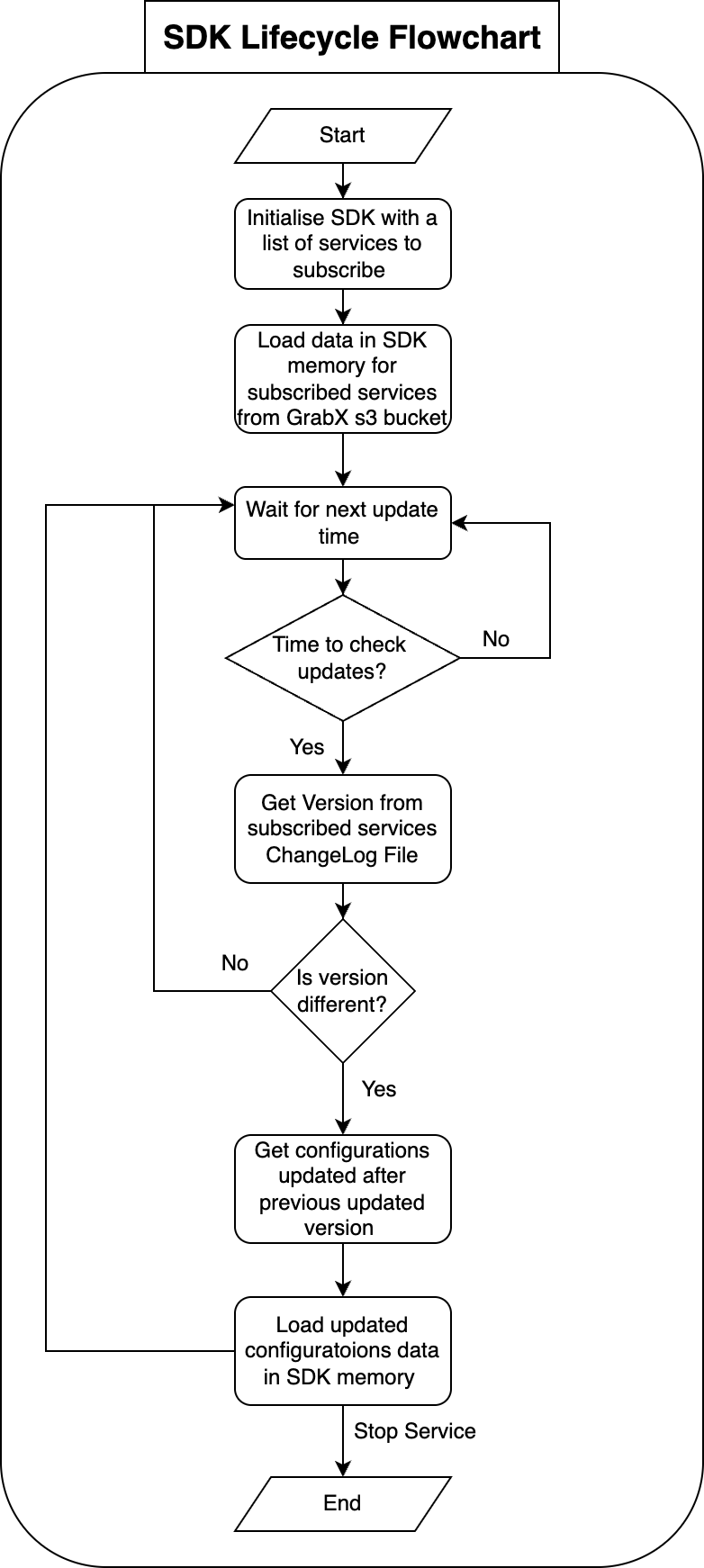
The SDK only sought updates for the subscribed services. The client SDK needed to read the changelog file for each of the subscribed services, comparing the latest changelog version against the SDK version number. Whenever a newer changelog version was available, the SDK updated the variables with the latest version.
This approach significantly reduced the volume of data that the SDK needed to download, decode, and load into memory during both initialisation and each subsequent update.
Conclusion
In summary, we identified ways to optimise CPU and memory usage in the GrabX SDK. Our analysis revealed that frequent high resource consumption hindered the wider adoption of GrabX. We proposed a series of modifications, including partitioning data by service and creating separate JSON files for each configuration.
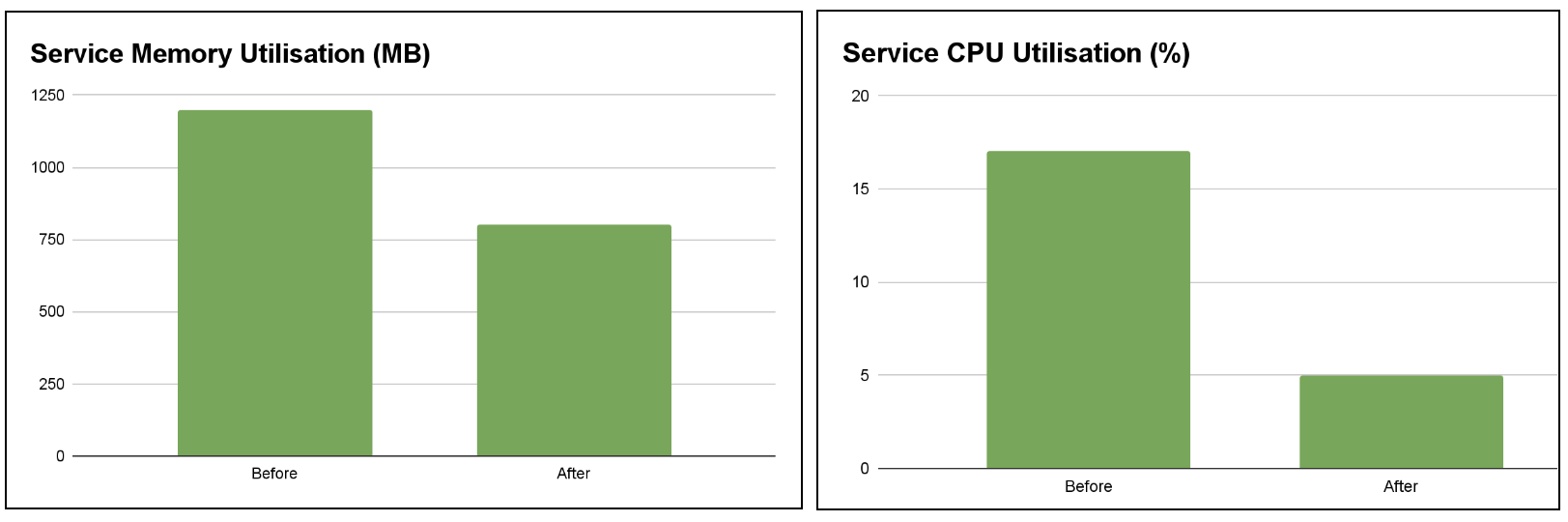
After benchmarking the proposed solution with a variety of configuration data sizes, we found that the solution has the potential to reduce memory utilisation by up to 70% and decrease the maximum CPU utilisation by more than 50%. These improvements significantly enhance the performance and scalability of the GrabX SDK.
Moving forward, we plan to continue optimising the GrabX SDK by exploring additional improvements, such as reducing its initialisation time. These efforts aim to make GrabX an even more robust and reliable solution for product configuration management within Grab’s ecosystem.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!