
Search indexing optimisation
Modern applications commonly utilise various database engines, with each serving a specific need. At Grab Deliveries, MySQL database (DB) is utilised to store canonical forms of data, and Elasticsearch to provide advanced search capabilities. MySQL serves as the primary data storage for raw data, and Elasticsearch as the derived storage.

Efforts have been made to synchronise data between MySQL and Elasticsearch. In this post, a series of techniques will be introduced on how to optimise incremental search data indexing.
Background
The synchronisation of data from the primary data storage to the derived data storage is handled by Food-Puxian, a Data Synchronisation Platform (DSP). In a search service context, it is the synchronisation of data between MySQL and Elasticsearch.
The data synchronisation process is triggered on every real-time data update to MySQL, which will streamline the updated data to Kafka. DSP consumes the list of Kafka streams and incrementally updates the respective search indexes in Elasticsearch. This process is also known as Incremental Sync.
Kafka to DSP
DSP uses Kafka streams to implement Incremental Sync. A stream represents an unbounded, continuously updating data set, which is ordered, replayable and fault-tolerant.

The above diagram depicts the process of data synchronisation using Kafka. The Data Producer creates a Kafka stream for every operation done on MySQL and sends it to Kafka in real-time. DSP creates a stream consumer for each Kafka stream and the consumer reads data updates from respective Kafka streams and synchronises them to Elasticsearch.
MySQL to Elasticsearch
Indexes in Elasticsearch correspond to tables in MySQL. MySQL data is stored in tables, while Elasticsearch data is stored in indexes. Multiple MySQL tables are joined to form an Elasticsearch index. The below snippet shows the Entity-Relationship mapping in MySQL and Elasticsearch. Entity A has a one-to-many relationship with entity B. Entity A has multiple associated tables in MySQL, table A1 and A2, and they are joined into a single Elasticsearch index A.
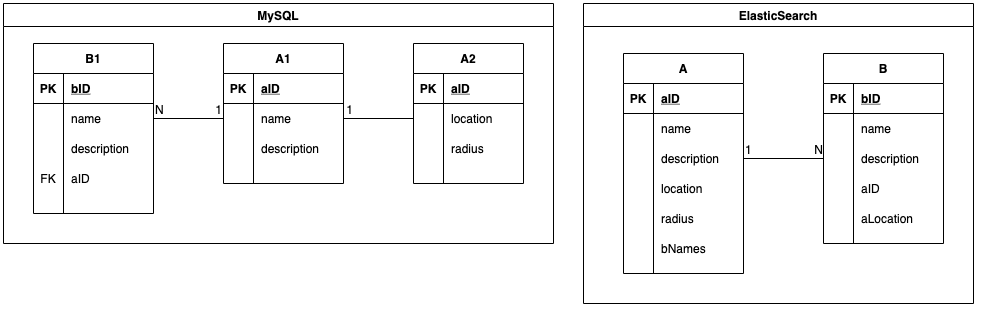
Sometimes a search index contains both entity A and entity B. In a keyword search query on this index, e.g. “Burger”, objects from both entity A and entity B whose name contains “Burger” are returned in the search response.
Original Incremental Sync
Original Kafka streams
The Data Producers create a Kafka stream for every MySQL table in the ER diagram above. Every time there is an insert, update, or delete operation on the MySQL tables, a copy of the data after the operation executes is sent to its Kafka stream. DSP creates different stream consumers for every Kafka stream since their data structures are different.
Stream Consumer infrastructure
Stream Consumer consists of 3 components.
- Event Dispatcher: Listens and fetches events from the Kafka stream, pushes them to the Event Buffer and starts a goroutine to run Event Handler for every event whose ID does not exist in the Event Buffer.
- Event Buffer: Caches events in memory by the primary key (aID, bID, etc). An event is cached in the Buffer until it is picked by a goroutine or replaced when a new event with the same primary key is pushed into the Buffer.
- Event Handler: Reads an event from the Event Buffer and the goroutine started by the Event Dispatcher handles it.
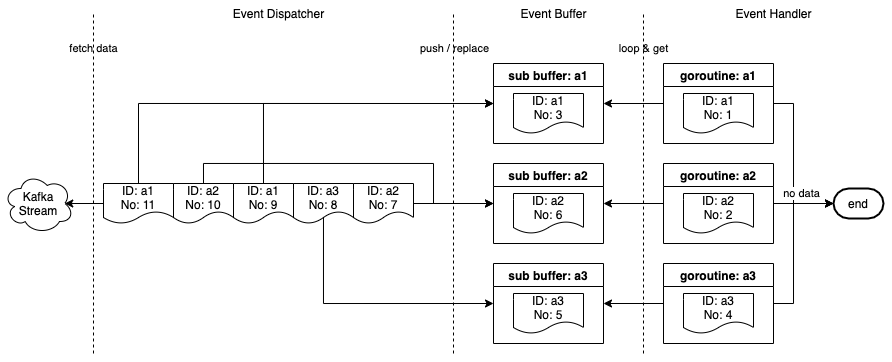
Event Buffer procedure
Event Buffer consists of many sub buffers, each with a unique ID which is the primary key of the event cached in it. The maximum size of a sub buffer is 1. This allows the Event Buffer to deduplicate events having the same ID in the buffer.
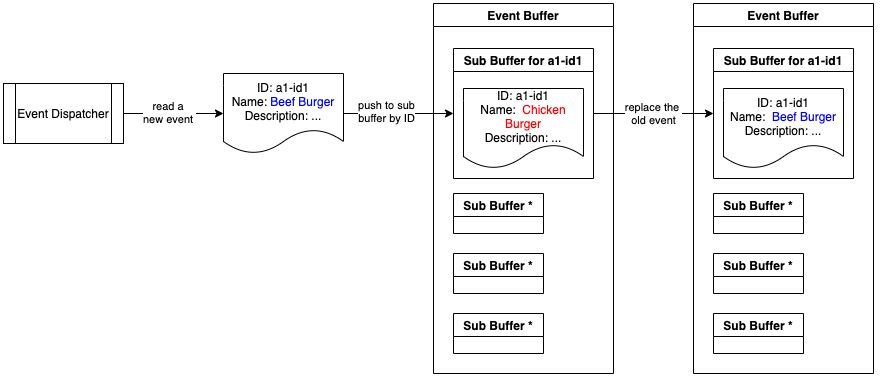
The below diagram shows the procedure of pushing an event to the Event Buffer. When a new event is pushed to the buffer, the old event sharing the same ID will be replaced. The replaced event is therefore not handled.
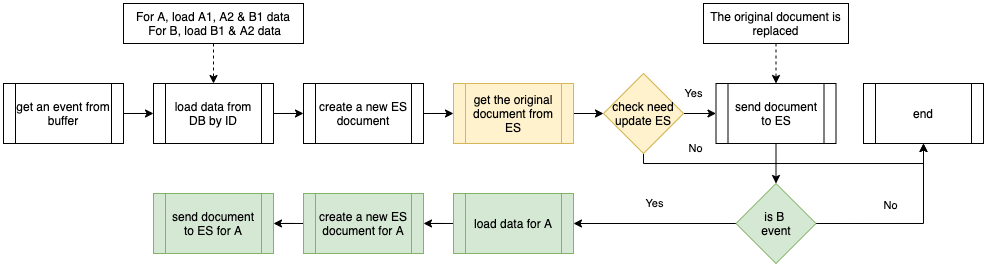
Event Handler procedure
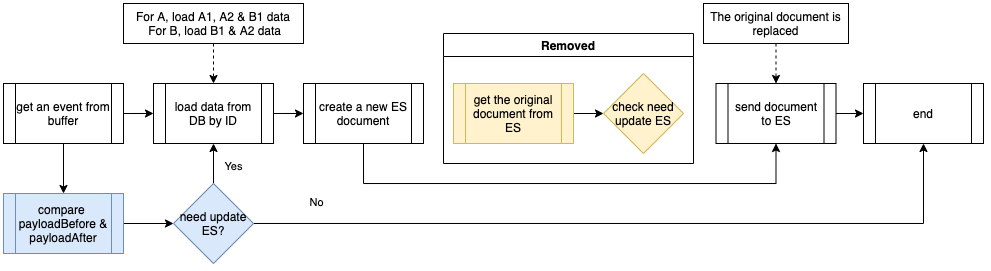
The below flowchart shows the procedures executed by the Event Handler. It consists of the common handler flow (in white), and additional procedures for object B events (in green). After creating a new Elasticsearch document by data loaded from the database, it will get the original document from Elasticsearch to compare if any field is changed and decide whether it is necessary to send the new document to Elasticsearch.
When object B event is being handled, on top of the common handler flow, it also cascades the update to the related object A in the Elasticsearch index. We name this kind of operation Cascade Update.
Issues in the original infrastructure
Data in an Elasticsearch index can come from multiple MySQL tables as shown below.
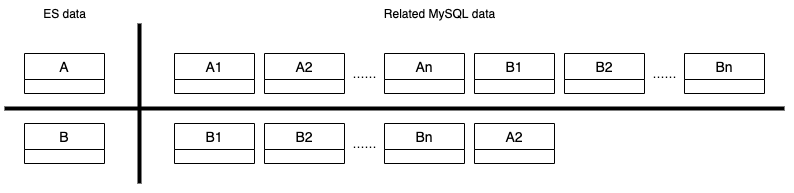
The original infrastructure came with a few issues.
- Heavy DB load: Consumers read from Kafka streams, treat stream events as notifications then use IDs to load data from the DB to create a new Elasticsearch document. Data in the stream events are not well utilised. Loading data from the DB every time to create a new Elasticsearch document results in heavy traffic to the DB. The DB becomes a bottleneck.
- Data loss: Producers send data copies to Kafka in application code. Data changes made via MySQL command-line tool (CLT) or other DB management tools are lost.
- Tight coupling with MySQL table structure: If producers add a new column to an existing table in MySQL and this column needs to be synchronised to Elasticsearch, DSP is not able to capture the data changes of this column until the producers make the code change and add the column to the related Kafka Stream.
- Redundant Elasticsearch updates: Elasticsearch data is a subset of MySQL data. Producers publish data to Kafka streams even if changes are made on fields that are not relevant to Elasticsearch. These stream events that are irrelevant to Elasticsearch would still be picked up.
- Duplicate cascade updates: Consider a case where the search index contains both object A and object B. A large number of updates to object B are created within a short span of time. All the updates will be cascaded to the index containing both objects A and B. This will bring heavy traffic to the DB.
Optimised Incremental Sync
MySQL Binlog
MySQL binary log (Binlog) is a set of log files that contain information about data modifications made to a MySQL server instance. It contains all statements that update data. There are two types of binary logging:
- Statement-based logging: Events contain SQL statements that produce data changes (inserts, updates, deletes).
- Row-based logging: Events describe changes to individual rows.
The Grab Caspian team (Data Tech) has built a Change Data Capture (CDC) system based on MySQL row-based Binlog. It captures all the data modifications made to MySQL tables.
Current Kafka streams
The Binlog stream event definition is a common data structure with three main fields: Operation, PayloadBefore and PayloadAfter. The Operation enums are Create, Delete, and Update. Payloads are the data in JSON string format. All Binlog streams follow the same stream event definition. Leveraging PayloadBefore and PayloadAfter in the Binlog event, optimisations of incremental sync on DSP becomes possible.

Stream Consumer optimisations
Event Handler optimisations
Optimisation 1
Remember that there was a redundant Elasticsearch updates issue mentioned above where the Elasticsearch data is a subset of the MySQL data. The first optimisation is to filter out irrelevant stream events by checking if the fields that are different between PayloadBefore and PayloadAfter are in the Elasticsearch data subset.
Since the payloads in the Binlog event are JSON strings, a data structure only with fields that are present in Elasticsearch data is defined to parse PayloadBefore and PayloadAfter. By comparing the parsed payloads, it is easy to know whether the change is relevant to Elasticsearch.
The below diagram shows the optimised Event Handler flows. As shown in the blue flow, when an event is handled, PayloadBefore and PayloadAfter are compared first. An event will be processed only if there is a difference between PayloadBefore and PayloadAfter. Since the irrelevant events are filtered, it is unnecessary to get the original document from Elasticsearch.
Achievements
- No data loss. Changes made via MySQL CLT or other DB manage tools can be captured.
- No dependency on MySQL table definition. All the data is in JSON string format.
- No redundant Elasticsearch updates and DB reads.
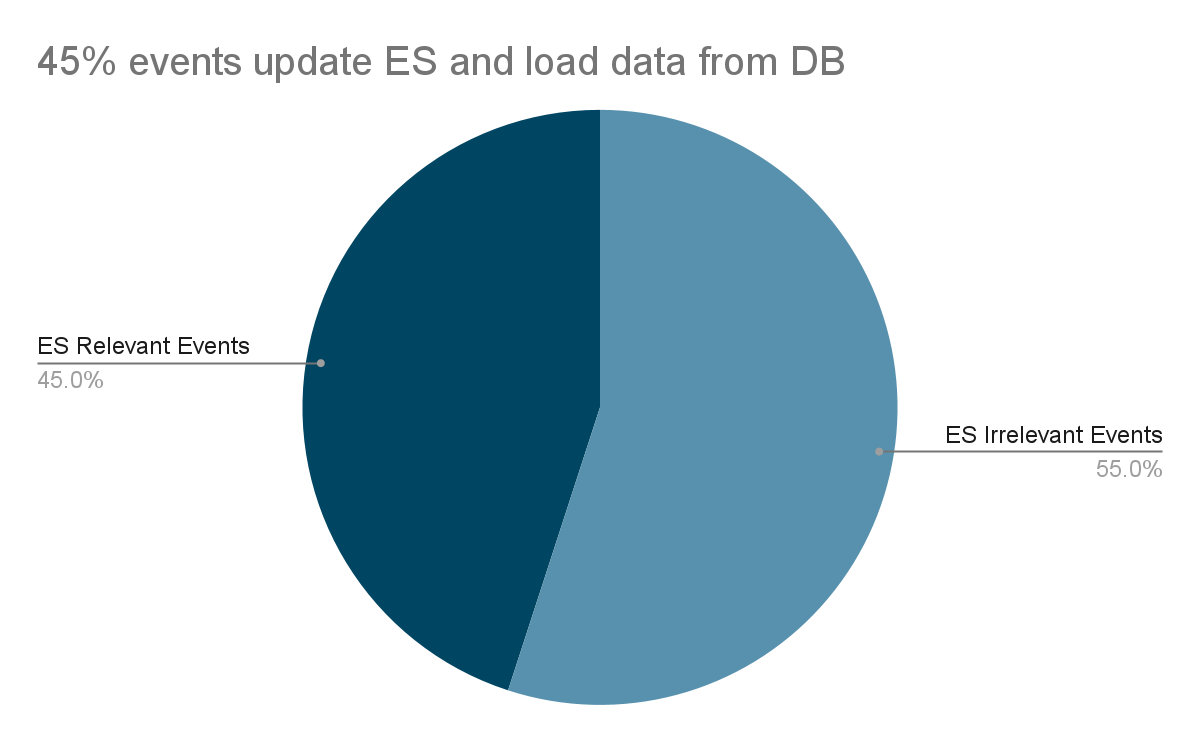
- Elasticsearch reads traffic reduced by 90%: Not a need to get the original document from Elasticsearch to compare with the newly created document anymore.
- 55% of irrelevant stream events are filtered out.
- The DB load is reduced by 55%
Optimisation 2
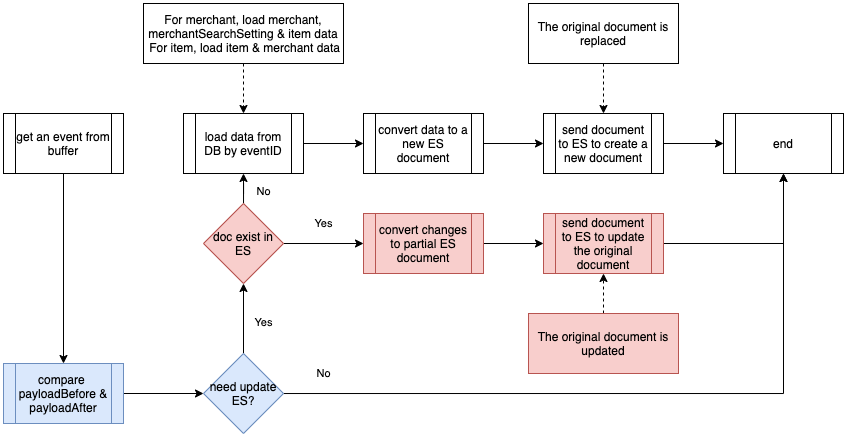
The PayloadAfter in the event provides updated data. This makes us think about whether a completely new Elasticsearch document is needed each time, with its data read from several MySQL tables. The second optimisation is to change to a partial update using data differences from the Binlog event.
The below diagram shows the Event Handler procedure flow with a partial update. As shown in the red flow, instead of creating a new Elasticsearch document for each event, a check on whether the document exists will be performed first. If the document exists, which happens for the majority of the time, the data is changed in this event, provided the comparison between PayloadBefore and PayloadAfter is updated to the existing Elasticsearch document.
Achievements
- Change most Elasticsearch relevant events to partial update: Use data in stream events to update Elasticsearch.
- Elasticsearch load reduced: Only fields that have been changed will be sent to Elasticsearch.
- DB load reduced: DB load reduced by 80% based on Optimisation 1.
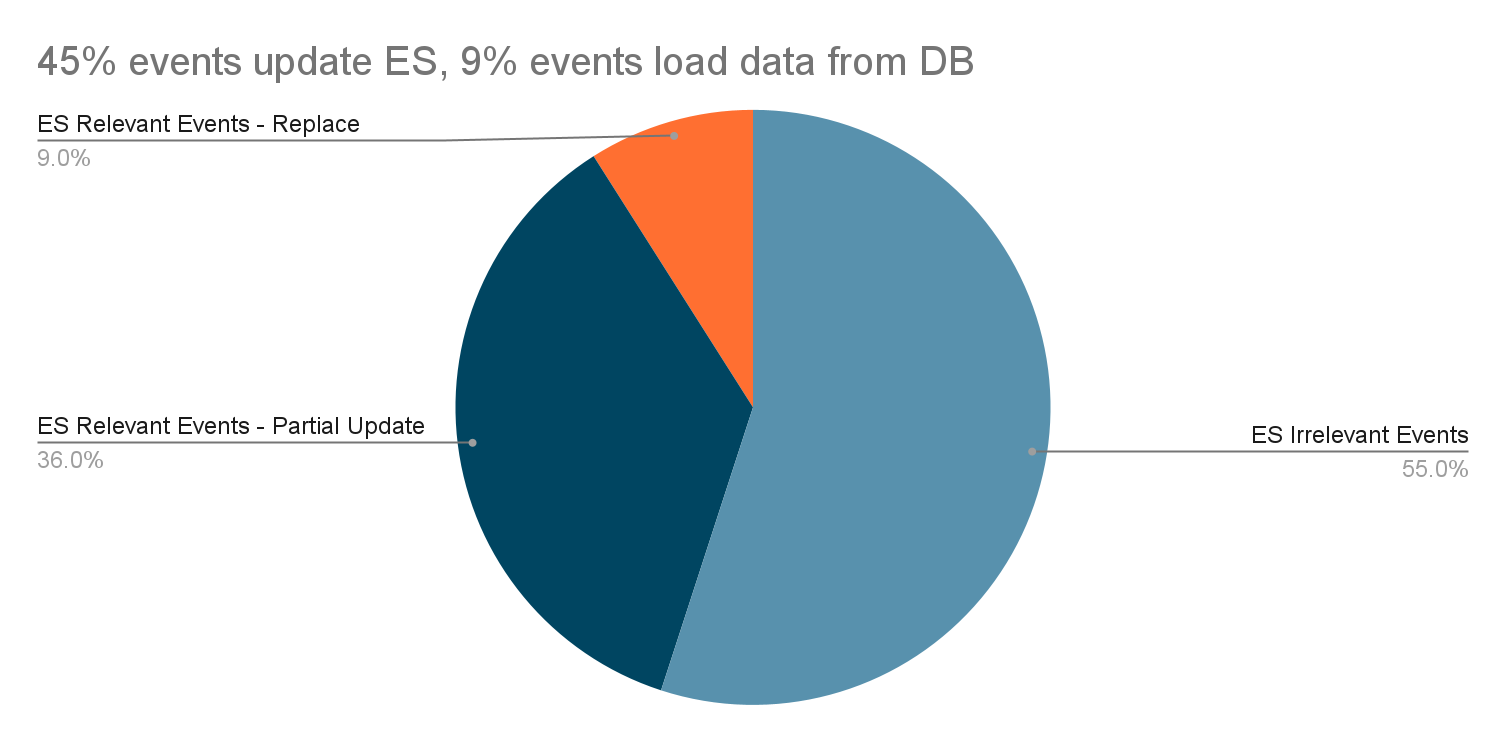
Event Buffer optimisation
Instead of replacing the old event, we merge the new event with the old event when the new event is pushed to the Event Buffer.
The size of each sub buffer in Event Buffer is 1. In this optimisation, the stream event is not treated as a notification anymore. We use the Payloads in the event to perform Partial Updates. The old procedure of replacing old events is no longer suitable for the Binlog stream.
When the Event Dispatcher pushes a new event to a non-empty sub buffer in the Event Buffer, it will merge event A in the sub buffer and the new event B into a new Binlog event C, whose PayloadBefore is from Event A and PayloadAfter is from Event B.
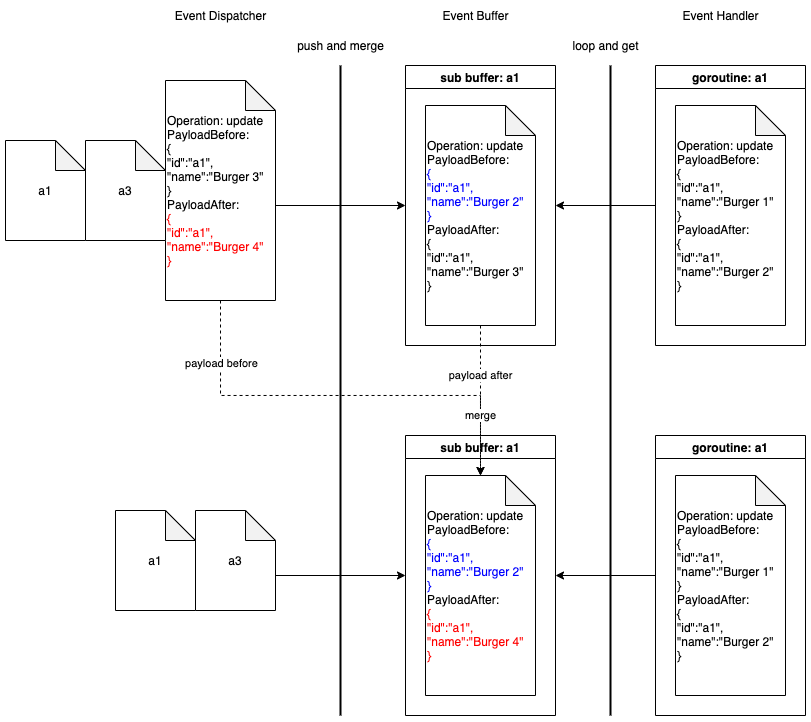
Cascade Update optimisation
Optimisation
We used a new stream to handle cascade update events. When the producer sends data to the Kafka stream, data sharing the same ID will be stored at the same partition. Every DSP service instance has only one stream consumer. When Kafka streams are consumed by consumers, one partition will be consumed by only one consumer. So the Cascade Update events sharing the same ID will be consumed by one stream consumer on the same EC2 instance. With this special mechanism, the in-memory Event Buffer is able to deduplicate most of the Cascade Update events sharing the same ID.
The flowchart below shows the optimised Event Handler procedure. Highlighted in green is the original flow while purple highlights the current flow with Cascade Update events. When handling an object B event, instead of cascading update the related object A directly, the Event Handler will send a Cascade Update event to the new stream. The consumer of the new stream will handle the Cascade Update event and synchronise the data of object A to the Elasticsearch.
Achievements
- Cascade Update events deduplicated by 80%.
- DB load introduced by cascade update is reduced.
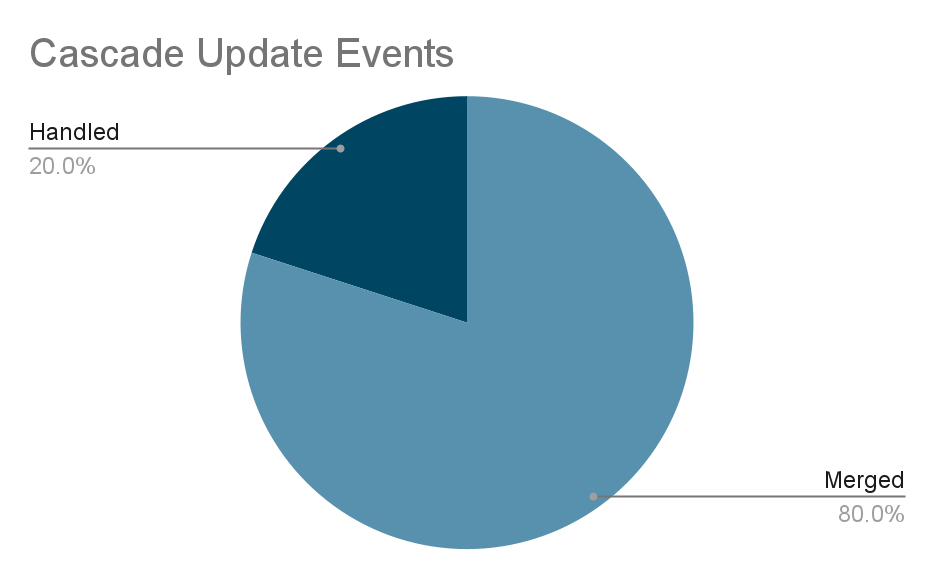
Summary
In this article four different DSP optimisations are explained. After switching to MySQL Binlog streams provided by the Coban team and optimising Stream Consumer, DSP has saved about 91% DB reads and 90% Elasticsearch reads, and the average queries per second (QPS) of stream traffic processed by Stream Consumer increased from 200 to 800. The max QPS at peak hours could go up to 1000+. With a higher QPS, the duration of processing data and the latency of synchronising data from MySQL to Elasticsearch was reduced. The data synchronisation ability of DSP has greatly improved after optimisation.
Special thanks to Jun Ying Lim and Amira Khazali for proofreading this article.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!