
Data mesh at Grab part I: Building trust through certification
Introduction
At Grab, our journey towards a more robust and scalable data ecosystem has been a continuous evolution.
Considering the size of our data lake and complexity of our ecosystem, with businesses spanning across ride hailing, food delivery, and financial services, we have been long past the point where a single centrally managed data warehouse could serve all these data needs. Over its first decade, Grab experienced dramatic growth. Like most growing businesses, teams in Grab prioritised delivering new features to meet the demands of their users. This meant that the task of data maintenance had to take a back seat so that development and stabilisation works can be focused to keep up with the growth. However, to prepare Grab for the next 10 years, especially for a future where AI is likely to play an important role, our leadership understood the need for high quality data foundation and gave a mandate to our data teams to uplevel our entire enterprise data ecosystem.
Acknowledging the rising need for data-driven insights and the continuous expansion of our data repository, we initiated our data mesh journey, named the Signals Marketplace, in 2024.
However, this journey was far from simple. We encountered several critical challenges that required a significant transformation in our approach to data management. Some of the challenges encountered include:
-
High volume and variety of data being generated: Grab’s diverse operations created both opportunities and complexities. Effectively harnessing this wealth of information required a scalable, streamlined and accessible approach.
-
Gaps in data ownership: As our data landscape expanded, maintaining data quality and reliability became increasingly difficult without clear lines of ownership and accountability. This often led to ad-hoc discussions and delays in resolving data related issues. Since it was difficult to trust the reliability of an existing pipeline, teams were likely to create duplicate pipelines just so they have something they can control.
-
Unscalable reliance on central Data Engineering (DE) team: Our traditional reliance on a central DE team to curate and serve all data needs was becoming a bottleneck. This centralised model struggled to keep pace with the distributed nature of data creation and consumption across various product and engineering teams.
-
Lack of communication between data consumers and producers: Data producers are unaware of downstream dependencies of their data which led to several instances of critical pipelines breaking because of upstream changes.
-
No single source of truth: While we did have a central data warehouse, it still left a lot of data gaps across Grab’s many business lines. Teams would struggle to identify the correct data definitions and reliable sources of truth.
-
Varied sophistication of data practitioners: Different teams have different levels of expertise in regards to data. Some teams had dedicated data engineers, but many didn’t.
To address these challenges, we made a strategic decision to adopt a data mesh architecture. Data mesh is a decentralised approach to data management that treats data as a product, owned and served by domain specific teams. This paradigm shift empowers teams closest to the data to take responsibility for its quality, reliability, and accessibility.
Our primary goal in adopting a data mesh was to significantly increase the reusability and reliability of our data assets across the organisation. By fostering a culture of data ownership and providing the necessary tools and processes, we aimed to unlock the full potential of our data to drive innovation and better serve our users and partners.
Certification
A cornerstone of our data mesh implementation is the concept of data certification. We believe that clearly identifying high quality, trustworthy datasets is crucial for both data producers and consumers.
Why certification?
Certification offers significant benefits to both sides of the data ecosystem. Data producers can clearly define and communicate the expectations and guarantees associated with their certified data assets, like defining Service Level Agreements (SLAs) for engineering services. This includes aspects like schema, data quality, and freshness. For data consumers, certification provides the confidence to readily discover and utilise these assets. Knowing that they come with stronger reliability guarantees and clear documentation, data consumers can confidently “shop” for certified data products, reducing the need for extensive validation and ad-hoc inquiries.
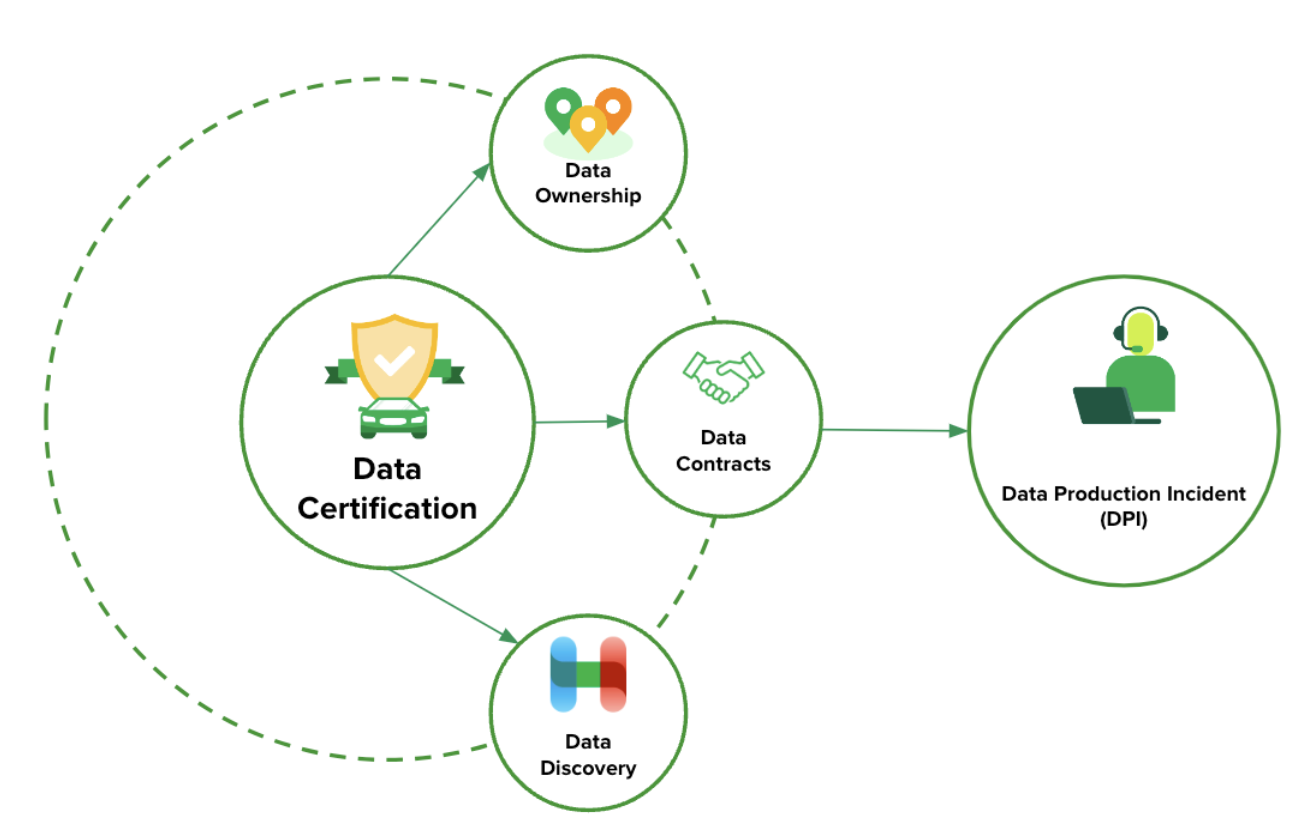
To achieve widespread data certification, we focused on several key enablers:
-
Ownership: Establishing decentralised ownership and accountability is fundamental and non-trivial. We clearly identified teams which we call Data Domains, individuals responsible as Business Data Owners (BDOs), and Technical Data Owners (TDOs) for the upkeep, usability, documentation, and associated Service Level Objective (SLOs) of each data product. This step was bootstrapped by leveraging the identification of the data asset creator’s team. However, if the creator had changed teams or left the company, the initial mapping of Domain <> Data Asset needs to be reviewed by the Domain Leads.
-
Data contract: We introduced data contracts as formal agreements between data producers and consumers. These contracts define the schema, SLA guarantees (including freshness, completeness, and retention policies), notice period for changes, and communication channels for a data product. Data certification helps set clear expectations and ensures reliability across data pipelines.
Data operational excellence
To further enhance accountability and ensure adherence to data contracts, we implemented automated Data Production Incidents (DPIs) for breached contracts. When data quality tests are done on data availability, timeliness, consistency, completeness, accuracy, validity, or other reliability guarantees fail, a DPI ticket is automatically created and assigned to the TDO. This system aims to standardise and drive accountability in investigating and fixing issues related to reliability guarantees within Data Contracts. The goal is for teams to acknowledge and fix the root cause of the DPIs.
Operationalisation and outcomes
To drive the adoption of data certification and the principles of data mesh across Grab, we focused on the following north star metric: percentage of queries hitting certified assets (%). This metric serves as a direct indicator of the reusability and trust in our certified data products. It also helps teams prioritise their certification efforts towards the most frequently used tables. It essentially pushes every data team in two synergistic directions:
- To certify their most used datasets.
- To query only certified datasets as much as possible.
Operationalisation
The successful operationalisation of our data mesh and certification efforts relied on several key factors listed below:
-
Executive buy-in: Strong leadership support was crucial in driving this organisational change and emphasising the importance of data as a product.
-
Organisation-wide push with clear measurable reporting: We implemented an organisation-wide initiative with clearly defined goals and measurable targets for data certification. Progress is tracked and reported to ensure accountability and drive momentum.
-
Dashboard to guide Grabbers target most used tables: Dashboards and tooling likely within Hubble, provided visibility into data usage patterns, guiding teams to prioritise the certification of their most popular and impactful datasets.
Outcomes
As a result of these efforts, we have observed significant positive outcomes:
-
75% of Grab queries hitting certified assets: We achieved a significant milestone with 75% of Grab’s data queries now targeting certified assets. This indicates a strong adoption of certified data products and a growing trust in their reliability.
-
Active deprecation of assets: The focus on data ownership and the push for certification has also led to increased visibility into our data landscape, allowing us to identify and actively deprecate redundant and duplicated data assets. Deprecated tables increases 400% year over year (YoY). This not only improves efficiency but also reduces the complexity and cost of maintaining our data infrastructure.
-
Accelerated innovation and cross-domain reusability: Prior to data mesh, every team often resorted to building their own data sources which leads to lower quality outcomes and slower turn around time. Today, internet of things datasets (IoT) like weather data collected by one team can now be reused by another team to optimise marketplace decisions — a practical step toward a more connected data ecosystem.
Beyond these individual instances, we observe a convergence across Grab towards most used datasets, with the number of P80 datasets (the top 80% of Grab’s most used data) reducing by over 58% since the start of the campaign.
What’s next
While we have made significant strides in our data mesh journey, we recognise that this is an ongoing evolution. This progress wouldn’t be as smooth sailing without the platforms we build for data management and observability. In our next article, we will be delving into the enhancements for crucial tooling and platforms like Genchi (in-house data quality observational tool) and Hubble (metadata management platform, built on DataHub and Grab proprietary technology), which underpin our data mesh vision and enable greater data reliability and reusability.
Massive credits to Grab’s leadership, Mohan Krishnan and Nikhil Dwarakanath, as well as Data owners on driving this Grab-wide effort to build strong data foundations in Grab. Grab’s data mesh would not have been possible without the commitment of all data owners to certify and curate their data products.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!