
Supporting large campaigns at scale
Introduction
At Grab, we run large marketing campaigns every day. A typical campaign may require executing multiple actions for millions of users all at once. The actions may include sending rewards, awarding points, and sending messages. Here is what a campaign may look like: On 1st Jan 2022, send two ride rewards to all the users in the “heavy users” segment. Then, send them a congratulatory message informing them about the reward.
Years ago, Grab’s marketing team used to stay awake at midnight to manually trigger such campaigns. They would upload a file at 12 am and then wait for a long time for the campaign execution to complete. To solve this pain point and support more capabilities down this line, we developed a “batch job” service, which is part of our in-house real-time automation engine, Trident.
The following are some services we use to support Grab’s marketing teams:
- Rewards: responsible for managing rewards.
- Messaging: responsible for sending messages to users. For example, push notifications.
- Segmentation: responsible for storing and retrieving segments of users based on certain criteria.
For simplicity, only the services above will be referenced for this article. The “batch job” service we built uses rewards and messaging services for executing actions, and uses the segmentation service for fetching users in a segment.
System requirements
Functional requirements
- Apply a sequence of actions targeting a large segment of users at a scheduled time, display progress to the campaign manager and provide a final report.
- For each user, the actions must be executed in sequence; the latter action can only be executed if the preceding action is successful.
Non-functional requirements
- Quick execution and high turnover rate.
- Definition of turnover rate: the number of scheduled jobs completed per unit time.
- Maximise resource utilisation and balance server load.
For the sake of brevity, we will not cover the scheduling logic, nor the generation of the report. We will focus specifically on executing actions.
Naive approach
Let’s start thinking from the most naive solution, and improve from there to reach an optimised solution.
Here is the pseudocode of a naive action executor.
def executeActionOnSegment(segment, actions):
for user in fetchUsersInSegment(segment):
for action in actions:
success := doAction(user, action)
if not success:
break
recordActionResult(user, action)
def doAction(user, action):
if action.type == "awardReward":
rewardService.awardReward(user, action.meta)
elif action.type == "sendMessage":
messagingService.sendMessage(user, action.meta)
else:
# other action types ...
One may be able to quickly tell that the naive solution does not satisfy our non-functional requirements for the following reasons:
- Execution is slow:
- The programme is single-threaded.
- Actions are executed for users one by one in sequence.
- Each call to the rewards and messaging services will incur network trip time, which impacts time cost.
- Resource utilisation is low: The actions will only be executed on one server. When we have a cluster of servers, the other servers will sit idle.
Here are our alternatives for fixing the above issues:
- Actions for different users should be executed in parallel.
- API calls to other services should be minimised.
- Distribute the work of executing actions evenly among different servers.
Note: Actions for the same user have to be executed in sequence. For example, if a sequence of required actions are (1) award a reward, (2) send a message informing the user to use the reward, then we can only execute action (2) after action (1) is successfully done for logical reasons and to avoid user confusion.
Our approach
A message queue is a well-suited solution to distribute work among multiple servers. We selected Kafka, among numerous message services, due to its following characteristics:
- High throughput: Kafka can accept reads and writes at a very high speed.
- Robustness: Events in Kafka are distributedly stored with redundancy, without a need to worry about data loss.
- Pull-based consumption: Consumers can consume events at their own speed. This helps to avoid overloading our servers.
When a scheduled campaign is triggered, we retrieve the users from the segment in batches; each batch comprises around 100 users. We write the batches into a Kafka stream, and all our servers consume from the stream to execute the actions for the batches. The following diagram illustrates the overall flow.
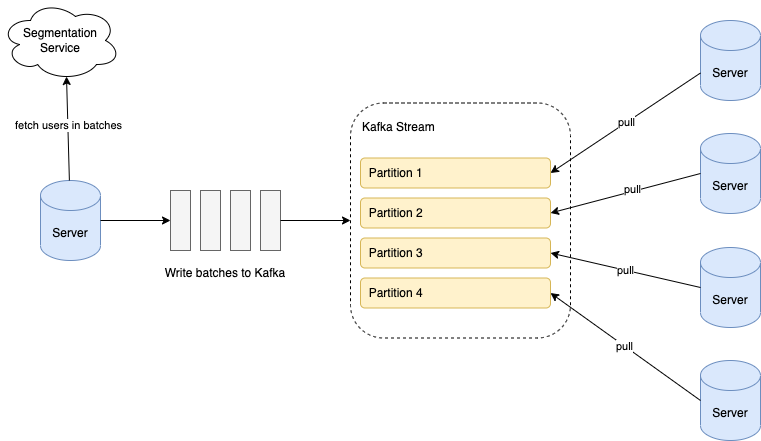
Data in Kafka is stored in partitions. The partition configuration is important to ensure that the batches are evenly distributed among servers:
- Number of partitions: Ensure that the number of stream partitions is greater than or equal to the max number of servers we will have in our cluster. This is because one Kafka partition can only be consumed by one consumer. If we have more consumers than partitions, some consumers will not receive any data.
- Partition key: For each batch, assign a hash value as the partition key to randomly allocate batches into different partitions.
Now that work is distributed among servers in batches, we can consider how to process each batch faster. If we follow the naive logic, for each user in the batch, we need to call the rewards or messaging service to execute the actions. This will create very high QPS (queries per second) to those services, and incur significant network round trip time.
To solve this issue, we decided to build batch endpoints in rewards and messaging services. Each batch endpoint takes in a list of user IDs and action metadata as input parameters, and returns the action result for each user, regardless of success or failure. With that, our batch processing logic looks like the following:
def processBatch(userBatch, actions):
users = userBatch
for action in actions:
successUsers, failedUsers = doAction(users, action)
recordFailures(failedUsers, action)
users = successUsers
def doAction(users, action):
resp = {}
if action.type == "awardReward":
resp = rewardService.batchAwardReward(users, action.meta)
elif action.type == "sendMessage":
resp = messagingService.batchSendMessage(users, action.meta)
else:
# other action types ...
return getSuccessUsers(resp), getFailedUsers(resp)
In the implementation of batch endpoints, we also made optimisations to reduce latency. For example, when awarding rewards, we need to write the records of a reward being given to a user in multiple database tables. If we make separate DB queries for each user in the batch, it will cause high QPS to DB and incur high network time cost. Therefore, we grouped all the users in the batch into one DB query for each table update instead.
Benchmark tests show that using the batch DB query reduced API latency by up to 85%.
Further optimisations
As more campaigns started running in the system, we came across various bottlenecks. Here are the optimisations we implemented for some major examples.
Shard stream by action type
Two widely used actions are awarding rewards and sending messages to users. We came across situations where the sending of messages was blocked because a different campaign of awarding rewards had already started. If millions of users were targeted for rewards, this could result in significant waiting time before messages are sent, ultimately leading them to become irrelevant.
We found out the API latency of awarding rewards is significantly higher than sending messages. Hence, to make sure messages are not blocked by long-running awarding jobs, we created a dedicated Kafka topic for messages. By having different Kafka topics based on the action type, we were able to run different types of campaigns in parallel.
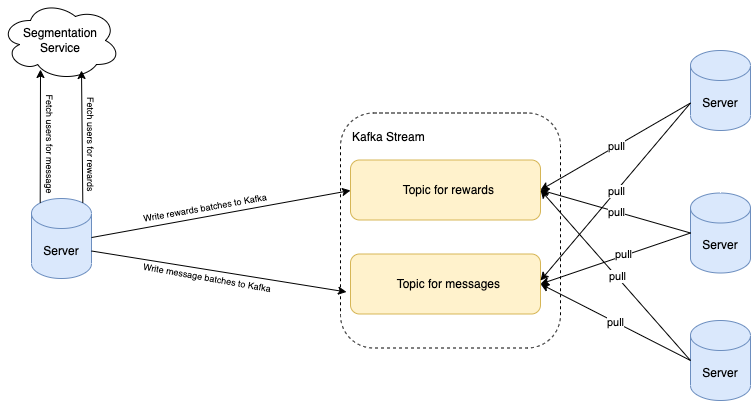
Shard stream by country
Grab operates in multiple countries. We came across situations where a campaign of awarding rewards to a small segment of users in one country was delayed by another campaign that targeted a huge segment of users in another country. The campaigns targeting a small set of users are usually more time-sensitive.
Similar to the above solution, we added different Kafka topics for each country to enable the processing of campaigns in different countries in parallel.
Remove unnecessary waiting
We observed that in the case of chained actions, messaging actions are generally the last action in the action list. For example, after awarding a reward, a congratulatory message would be sent to the user.
We realised that it was not necessary to wait for a sending message action to complete before processing the next batch of users. Moreover, the latency of the sending messages API is lower than awarding rewards. Hence, we adjusted the sending messages API to be asynchronous, so that the task of awarding rewards to the next batch of users can start while messages are being sent to the previous batch.
Conclusion
We have architected our batch jobs system in such a way so that it can be enhanced and optimised without redoing its work. For example, although we currently obtain the list of targeted users from a segmentation service, in the future, we may obtain this list from a different source, for example, all Grab Platinum tier members.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries. Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!