
The Journey of Deploying Apache Airflow at Grab
At Grab, we use Apache Airflow to schedule and orchestrate the ingestion and transformation of data, train machine learning models, and the copy data between clouds. There are many engineering teams at Grab that use Airflow, each of which originally had their own Airflow instance.
The proliferation of independently managed Airflow instances resulted in inefficient use of resources, where each team ended up solving the same problems of logging, scaling, monitoring, and more. From this morass came the idea of having a single dedicated team to manage all the Airflow instances for anyone in Grab that wants to use Airflow as a scheduling tool.
We designed and implemented an Apache Airflow-based scheduling and orchestration platform that currently runs close to 20 Airflow instances for different teams at Grab. Sounds interesting? What follows is a brief history.
Early Days
Circa 2018, we were running a few hundred Directed Acyclic Graphs (DAGs) on one Airflow instance in the Data Engineering team. There was no dedicated team to maintain it, and no Airflow expert in our team. We were struggling to maintain our Airflow instance, which was causing many jobs to fail every day. We were facing issues with library management, scaling, managing and syncing artefacts across all Airflow components, upgrading Airflow versions, deployment, rollbacks, etc.
After a few postmortem reports, we realised that we needed a dedicated team to maintain our Airflow. This was how our Airflow team was born.
In the initial months, we dedicated ourselves to stabilising our Airflow environment. During this process, we realised that Airflow has a steep learning curve and requires time and effort to understand and maintain properly. Also, we found that tweaking of Airflow configurations required a thorough understanding of Airflow internals.
We felt that for the benefit of everyone at Grab, we should leverage what we learned about Airflow to help other teams at Grab; there was no need for anyone else to go through the same struggles we did. That’s when we started thinking about managing Airflow for other teams.
We talked to the Data Science and Engineering teams who were also running Airflow to schedule their jobs. Almost all the teams were struggling to maintain their Airflow instance. A few teams didn’t have enough technical expertise to maintain their instance. The Data Scientists and Analysts that we spoke to were more than happy to outsource the overhead of Airflow maintenance and wanted to focus more on their Data Science use cases instead.
We started working with one of the Data Science teams and initiated the discussion to create a dockerised Airflow instance and run it on our Kubernetes cluster.
We created the Airflow instance and maintained it for them. Later, we were approached by two more teams to help with their Airflow instances. This was the trigger for us to design and create a platform on which we can efficiently manage Airflow instances for different teams.
Current State
As mentioned, we are currently serving close to 20 Airflow instances for various teams on this platform and leverage Apache Airflow to schedule thousands of daily jobs. Each Airflow instance is currently scheduling 1k to 60k daily jobs. Also, new teams can quickly try out Airflow without worrying about infrastructure and maintenance overhead. Let’s go through the important aspects of this platform such as design considerations, architecture, deployment, scalability, dependency management, monitoring and alerting, and more.
Design Considerations
The initial step we took towards building our scheduling platform was to define a set of expectations and guidelines around ownership, infrastructure, authentication, common artifacts and CI/CD, to name a few.
These were the considerations we had in mind:
- Deploy containerised Airflow instances on Kubernetes cluster to isolate Airflow instances at the team level. It should scale up and scale out according to usage.
- Each team can have different sets of jobs that require specific dependencies on the Airflow server.
- Provide common CI/CD templates to build, test, and deploy Airflow instances. These CI/CD templates should be flexible enough to be extended by users and modified according to their use case.
- Common plugins, operators, hooks, sensors will be shipped to all Airflow instances. Moreover, each team can have its own plugins, operators, hooks, and sensors.
- Support LDAP based authentication as it is natively supported by Apache Airflow. Each team can authenticate Airflow UI by their LDAP credentials.
- Use the Hashicorp Vault to store Airflow specific secrets. Inject these secrets via sidecar in Airflow servers.
- Use ELK stack to access all application logs and infrastructure logs.
- Datadog and PagerDuty will be used for monitoring and alerting.
- Ingest job statistics such as total number of jobs scheduled, no of failed jobs, no of successful jobs, active DAGs, etc. into the data lake and will be accessible via Presto.
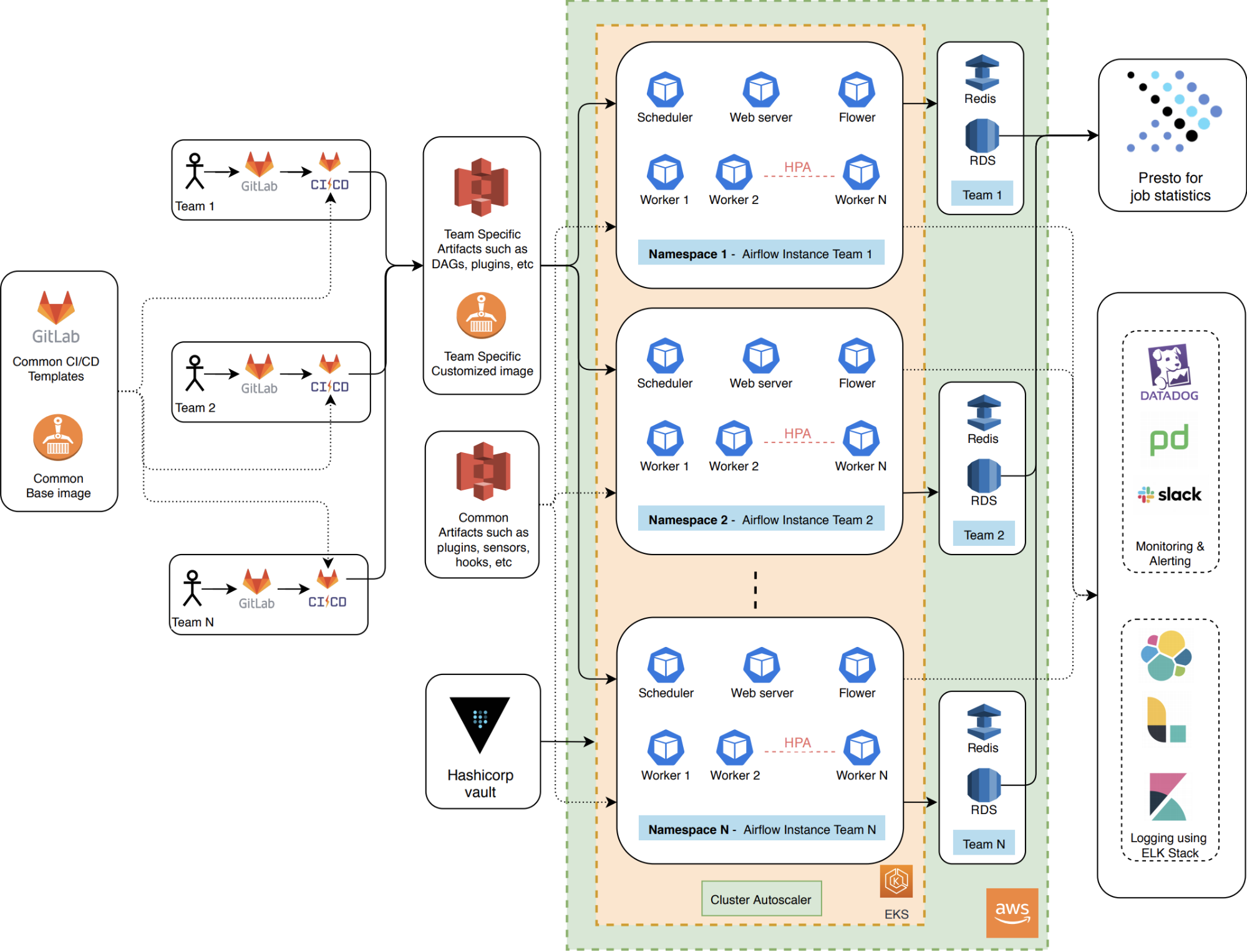
Infrastructure Management
Initially, we started deploying Airflow instances on Kubernetes clusters managed via Kubernetes Operations (KOPS). Later, we migrated to Amazon EKS to reduce the overhead of managing the Kubernetes control plane. Each Kubernetes namespace deploys one Airflow instance.
We chose Terraform to manage infrastructure as code. We deployed each Airflow instance using Terraform modules, which include a helm_release Terraform resource on top of our customised Airflow Helm Chart.
Each Airflow instance connects to its own Redis and RDS. RDS is responsible for storing Airflow metadata and Redis is acting as a celery broker between Airflow scheduler and Airflow workers.
The Hashicorp Vault is used to store secrets required by Airflow instances and injected via sidecar by each Airflow component. The ELK stack stores all logs related to Airflow instances and is used for troubleshooting any instance. Datadog, Slack, and PagerDuty are used to send alerts.
Presto is used to access job statistics, such as numbers on scheduled jobs, failed jobs, successful jobs, and active DAGs, to help each team to analyse their usage and stability of their jobs.
Doing Things at Scale
There are two kinds of scaling we need to talk about:
- Scaling of Airflow instances on a resource level handling different loads
- Scaling in terms of teams served on the platform
To scale Airflow instances, we set the request and the limit of each Airflow component allowing any of the components to scale up easily. To scale out Airflow workers, we decided to enable the horizontal pod autoscaler (HPA) using Memory and CPU parameters. The cluster autoscaler on EKS helps in scaling the platform to accommodate more teams.
Moreover, we categorised all our Airflow instances in three sizes (small, medium, and large) to efficiently use the resources. This was based on how many hourly/daily jobs it scheduled. Each Airflow instance type has a specific RDS instance type and storage, Redis instance type and CPU and memory, request/limit for scheduler, worker, web server, and flower. There are different Airflow configurations for each instance type to optimise the given resources to the Airflow instance.
Airflow Image and Version Management
The Airflow team builds and releases one common base Docker image for each Airflow version. The base image has Airflow installed with specific versions, as well as common Python packages, plugins, helpers, tests, patches, and so on.
Each team has their customised Docker image on top of the base image. In their customised Docker image, they can update the Python packages and can download other artifacts that they require. Each Airflow instance will be deployed using the team’s customised image.
There are common CI/CD templates provided by the Airflow team to build the customised image, run unit tests, and deploy Airflow instances from their GitLab pipeline.
To upgrade the Airflow version, the Airflow team reviews and studies the changelog of the released Airflow version, note down the important features and its impacts, open issues, bugs, and workable solutions. Later, we build and release the base Docker image using the new Airflow version.
We support only one Airflow version for all Airflow instances to have less maintenance overhead. In the case of minor or major versions, we support one old and new versions until the retirement period.
How We Deploy
There is a deployment ownership guideline that explains the schedule of deployments and the corresponding PICs. All teams have agreed on this guideline and share the responsibility with the Airflow Team.
There are two kinds of deployment:
- DAG deployment: This is part of the common GitLab CI/CD template. The Airflow team doesn’t trigger the DAG deployment, it’s fully owned by the teams.
- Airflow instance deployment: The Airflow instance deployment is required in these scenarios:
- Update in base Docker image
- Add/update in Python packages by any team
- Customisation in the base image by any team
- Change in Airflow configurations
- Change in the resource of scheduler, worker, web server or flower
Base Docker Image Update
The Airflow team maintains the base Docker image on the AWS Elastic Container Registry. The GitLab CI/CD builds the updated base image whenever the Airflow team changes the base image. The base image is validated by automated deployment on the test environment and automated smoke test. The Airflow instance owner of each team needs to trigger their build and deployment pipeline to apply the base image changes on their Airflow instance.
Python Package Additions or Updates
Each team can add or update their Python dependencies. The GitLab CI/CD pipeline builds a new image with updated changes. The Airflow instance owner manually triggers the deployment from their CI/CD pipeline. There is a flag to make it automated deployment as well.
Based Image Customisation
Each team can add any customisations on the base image. Similar to the above scenario, the GitLab CI/CD pipeline builds a new image with updated changes. The Airflow instance owner manually triggers the deployment from their CI/CD pipeline. To automate the deployment, a flag is made available.
Configuration Airflow and Airflow Component Resource Shanges
To optimise the Airflow instances, the Airflow Team makes changes to the Airflow configurations and resources of any of the Airflow components. The Airflow configurations and resources are also part of the Terraform code. Atlantis (https://www.runatlantis.io/) deploys the Airflow instances with Terraform changes.
There is no downtime in any form of deployment and doesn’t impact the running tasks and the Airflow UI.
Testing
During the process of making our first Airflow stable, we started exploring testing in Airflow. We wanted to validate the correctness of DAGs, duplicate DAG IDs, checking typos and cyclicity in DAGs, etc. We then later wrote the tests by ourselves and published a detailed blog in several channels: usejournal (part1) and medium (part2).
These tests are available in the base image and run in the GitLab pipeline from the user’s repository to validate their DAGs. The unit tests run using the common GitLab CI/CD template provided by the Airflow team.
Monitoring & Alerting
Our scheduling platform runs the Airflow instance for many critical jobs scheduled by each team. It’s important for us to monitor all Airflow instances and alert respective stakeholders in case of any failure.
We use Datadog for monitoring and alerting. To create a common Datadog dashboard, it is required to pass tags with metrics from Airflow and till Airflow 1.10.x, it doesn’t support tagging to Datadog metrics.
We have contributed to the community to enable Datadog support and it will be released in Airflow 2.0.0 (https://github.com/apache/Airflow/pull/7376). We internally patched this pull request and created the common Datadog dashboard.
There are three categories of metrics that we are interested in:
- EKS cluster metrics: It includes total In-Service Nodes, allocated CPU cores, allocated Memory, Node status, CPU/Memory request vs limit, Node disk and Memory pressure, Rx-Tx packets dropped/errors, etc.
- Host Metrics: These metrics are for each host participating in the EKS cluster. It includes Host CPU/Memory utilisation, Host free memory, System disk, and EBS IOPS, etc.
- Airflow instance metrics: These metrics are for each Airflow instance. It includes scheduler heartbeats, DagBag size, DAG processing import errors, DAG processing time, open/used slots in a pool, each pod’s Memory/CPU usage, CPU and Memory utilisation of metadata DB, database connections as well as the number of workers, active/paused DAGs, successful/failed/queued/running tasks, etc.
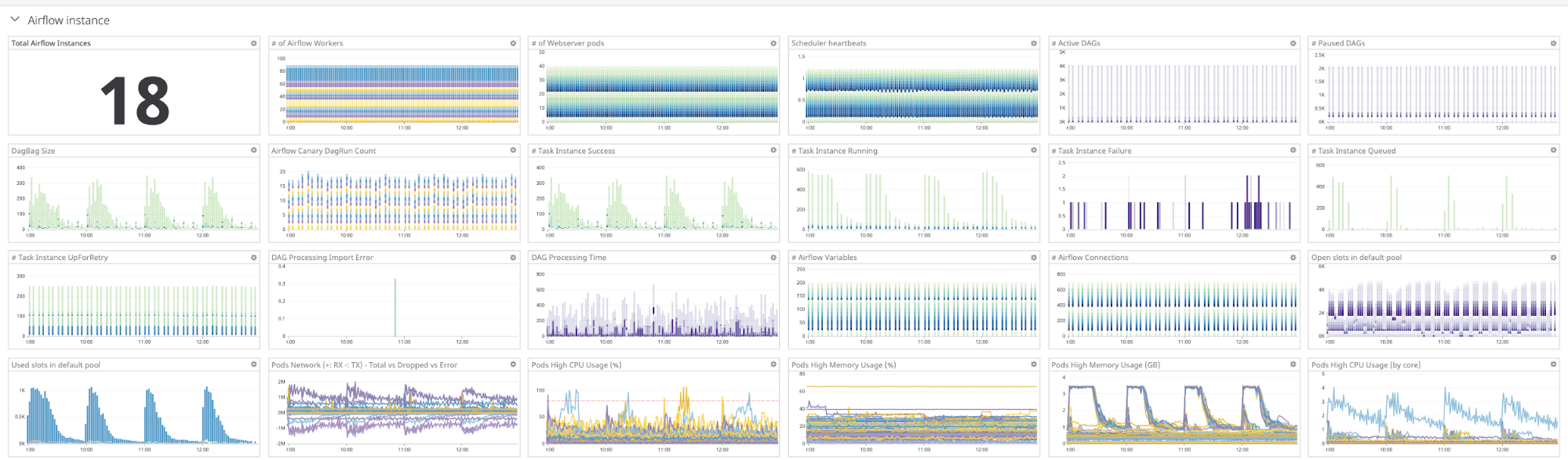
We alert respective stakeholders and oncalls using Slack and PagerDuty.
Benefits
These are the benefits of having our own Scheduling Platform:
- Scaling: HPA on Airflow workers running on EKS with autoscaler helps Airflow workers to scale automatically to theoretically infinite scale. This enables teams to run thousands of DAGs.
- Logging: Centralised logging using Kibana.
- Better Isolation: Separate Docker images for each team provide better isolation.
- Better Customisation: All teams are provided with a mechanism to customise their Airflow worker environment according to their requirements.
- Zero Downtime: Rolling upgrade and termination period on Airflow workers helps in zero downtime during the deployment.
- Efficient usage of infrastructure: Each team doesn’t need to allocate infrastructure for Airflow instances. All Airflow instances are deployed on one shared EKS cluster.
- Less maintenance overhead for users: Users can focus on their core work and don’t need to spend time maintaining Airflow instances and it’s resources.
- Common plugins and helpers: All common plugins and helpers available to use on Airflow instances. Each team doesn’t need to add.
Conclusion
Designing and implementing our own scheduling platform started with many challenges and unknowns. We were not sure about the scale we were aiming for, the heterogeneous workload from each team, or the level of triviality or complexity we were going to be faced. After two years, we have successfully built and productionised a scalable scheduling platform that helps teams at Grab to schedule their workload.
We have many failure stories, odd things we ran into, hacks and workarounds we patched. But, we went through it and provided a cost-effective and scalable scheduling platform with low maintenance overhead to all teams at Grab.
What’s Next
Moving ahead, we will be exploring to add the following capabilities:
- REST APIs to enable teams to access their Airflow instance programmatically and have better integration with other tools and frameworks.
- Support of dynamic DAGs at scale to help in decreasing the DAG maintenance overhead.
- Template-based engine to act as a middle layer between the scheduling platform and external systems. It will have a set of templates to generate DAGs which helps in better integration with the external system.
We suggest anyone who is running multiple Airflow instances within different teams to look at this approach and build the centralised scheduling platform. Before you begin, review the feasibility of building the centralised platform as it requires a vision, a lot of effort, and cross-communication with many teams.
Authored by Chandulal Kavar on behalf of the Airflow team at Grab - Charles Martinot, Vinnson Lee, Akash Sihag, Piyush Gupta, Pramiti Goel, Dewin Goh, QuiHieu Nguyen, James Anh-Tu Nguyen, and the Data Engineering Team.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!