Troubleshooting Unusual AWS ELB 5XX Error
This article is part one of a two-part series (part two). In this article, we explain the ELB 5XX errors which we experience without an apparent reason. We walk you through our investigative process and show you our immediate solution to this production issue. In the second article, we will explain why the non-intuitive immediate solution works and how we eventually found a more permanent solution.
Triggered: [Gothena] Astrolabe failed (Warning), an alert from Datadog that we have been seeing very often in our #tech-operations slack channel. This alert basically tells us that Gothena 1 is receiving ELB 2 HTTP 5xx 3 errors when calling Astrolabe 4. Because of how frequently we update our driver location data, losing one or two updates of a single driver has never really been an issue for us at Grab. It was only when this started creating a lot of noise for our on call engineers, we decided that it was time to dig into it and fix it once and for all.
Here is a high level walkthrough of the systems involved. The driver app would connect to the Gothena Service ELB. Requests are routed to Gothena service. Gothena sends location update related requests to Astrolabe.

Hopefully the above gives you a better understanding of the background before we dive into the problem.
Clues from AWS
If you have ever taken a look at the AWS ELB dashboards, you will know that it shows a number of interesting metrics such as SurgeQueue 5, SpillOver 6, RequestCount, HealthyInstances, UnhealthyInstances and a bunch of other backend metrics. As you see below, every time we receive one of the Astrolabe failed alerts, the AWS monitors would show that the SurgeQueue is filling up, SpillOver of requests is happening and that the average latency 7 of the requests increase. Interestingly, this situation would only persist for 1-2 minutes during our peak hours and only in one of the two AWS Availability Zones (AZ) that our ELBs are located in.
Cloudwatch Metrics
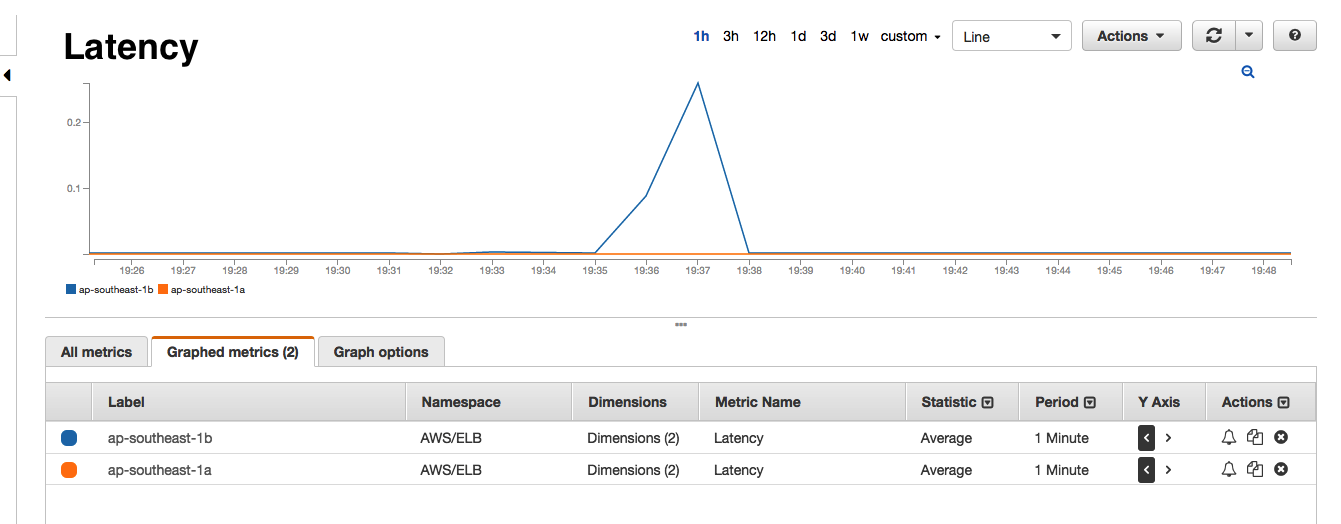
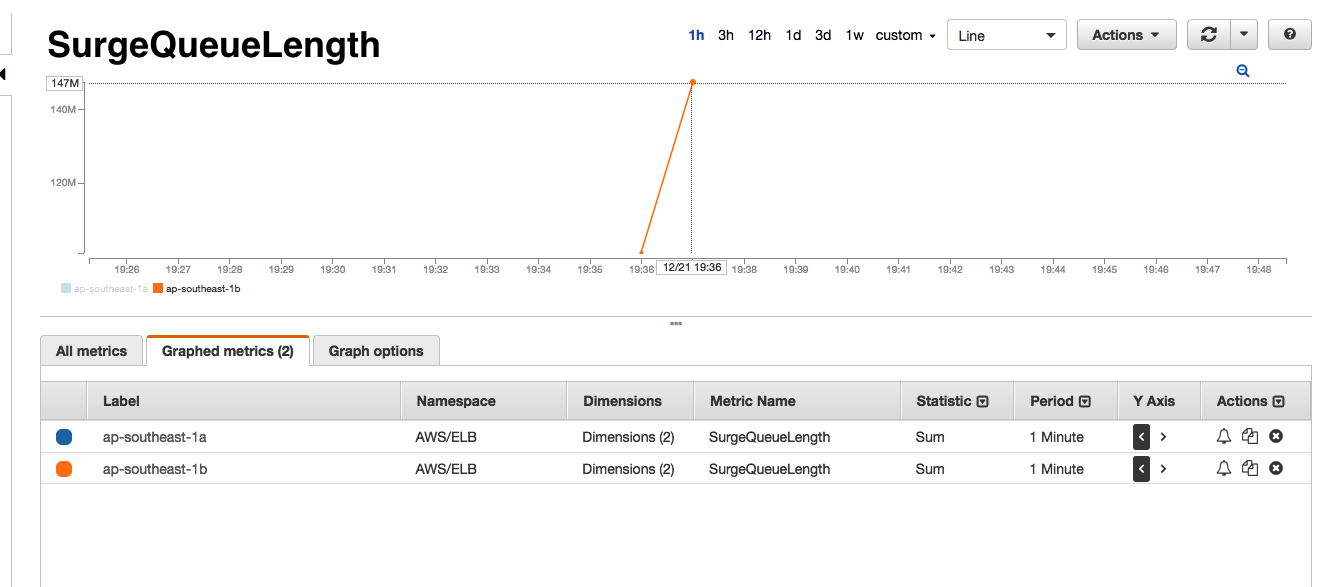
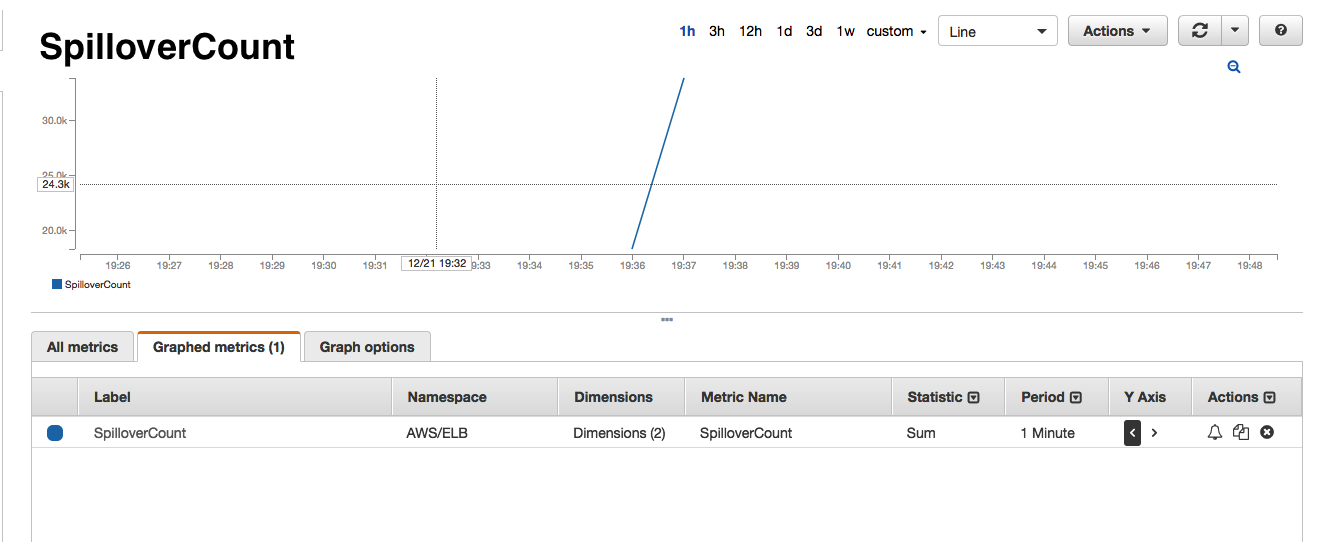
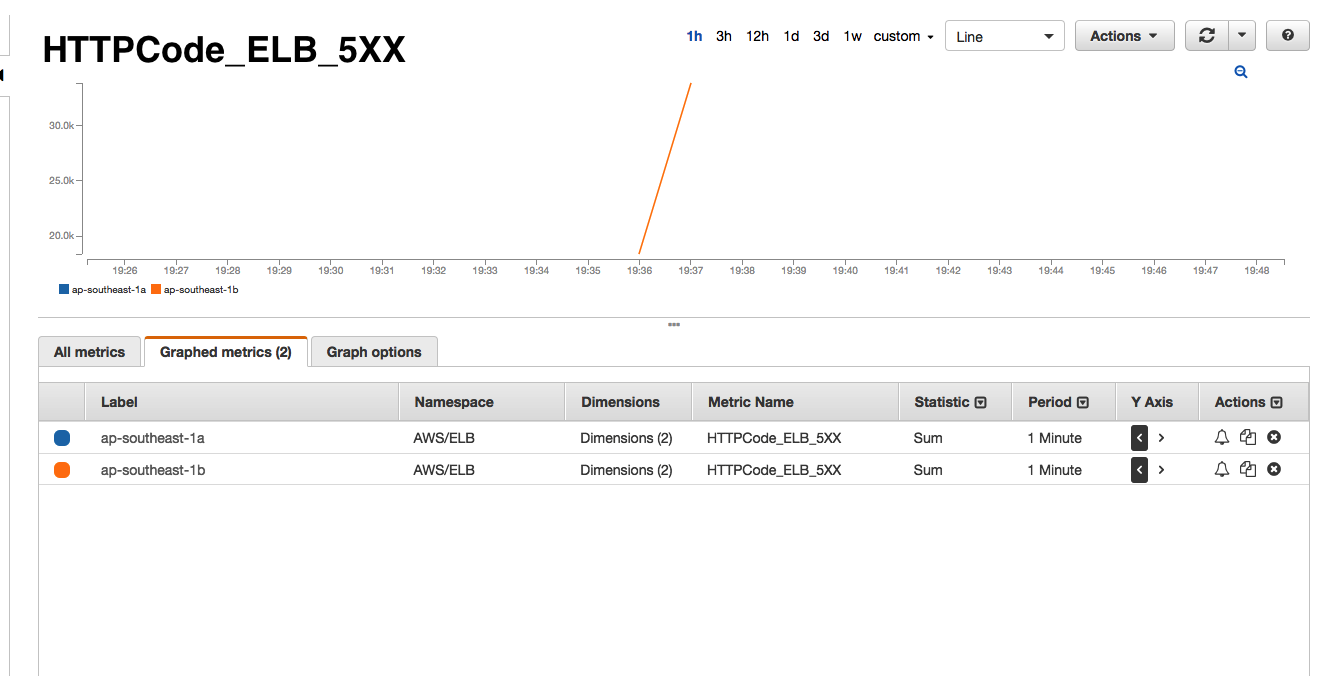
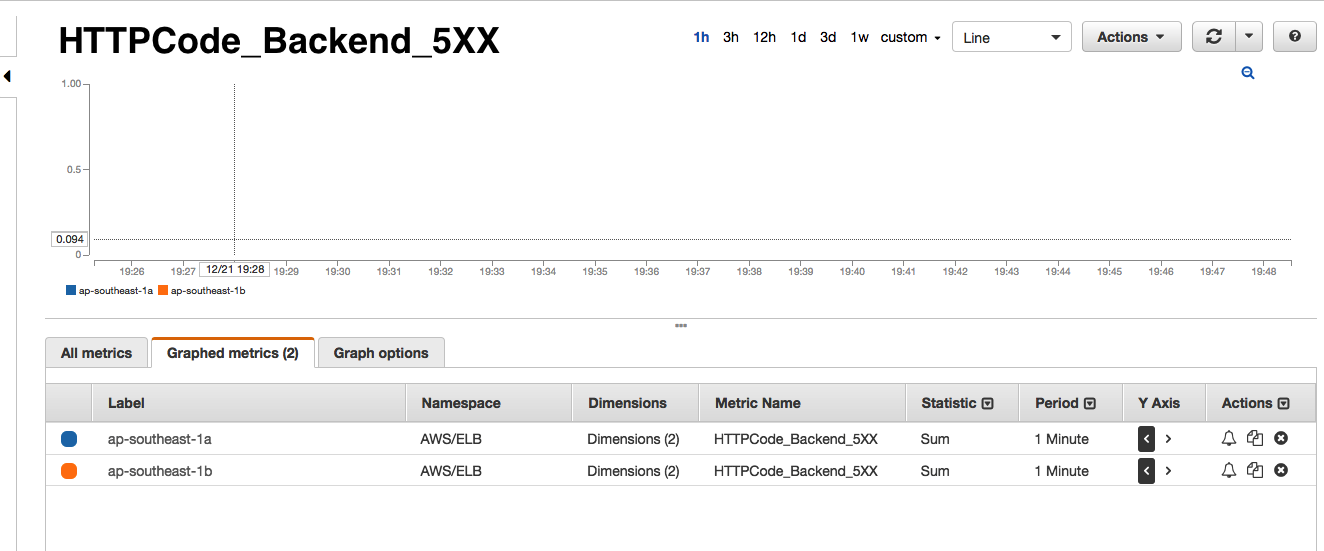
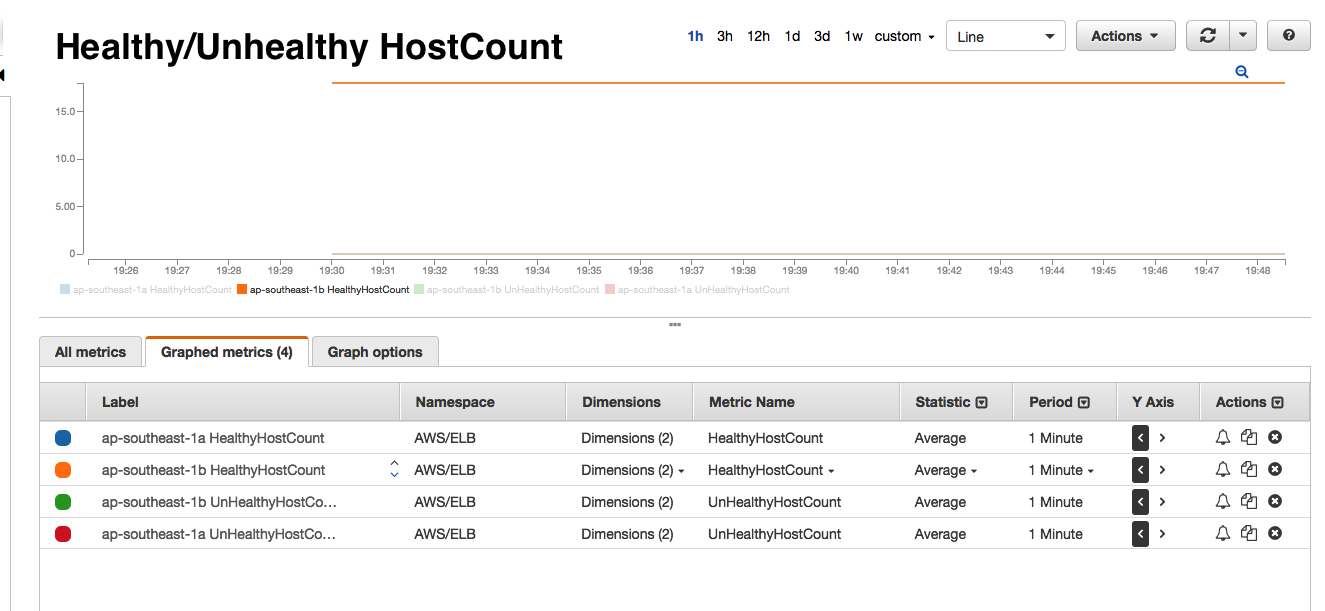
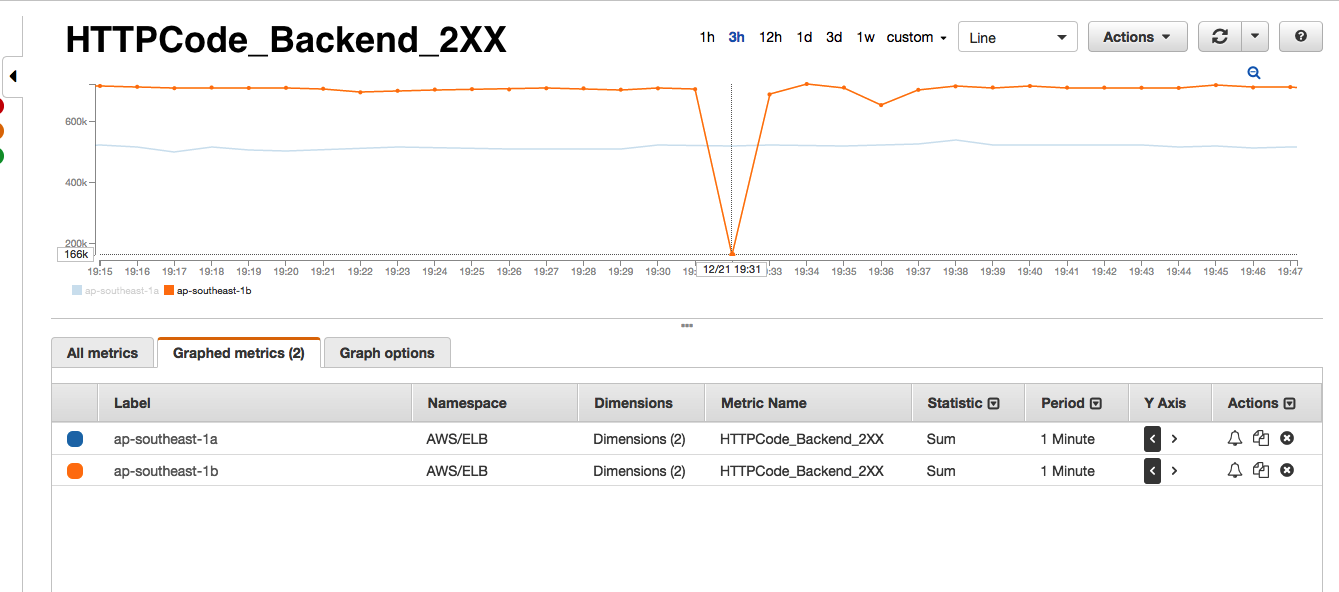
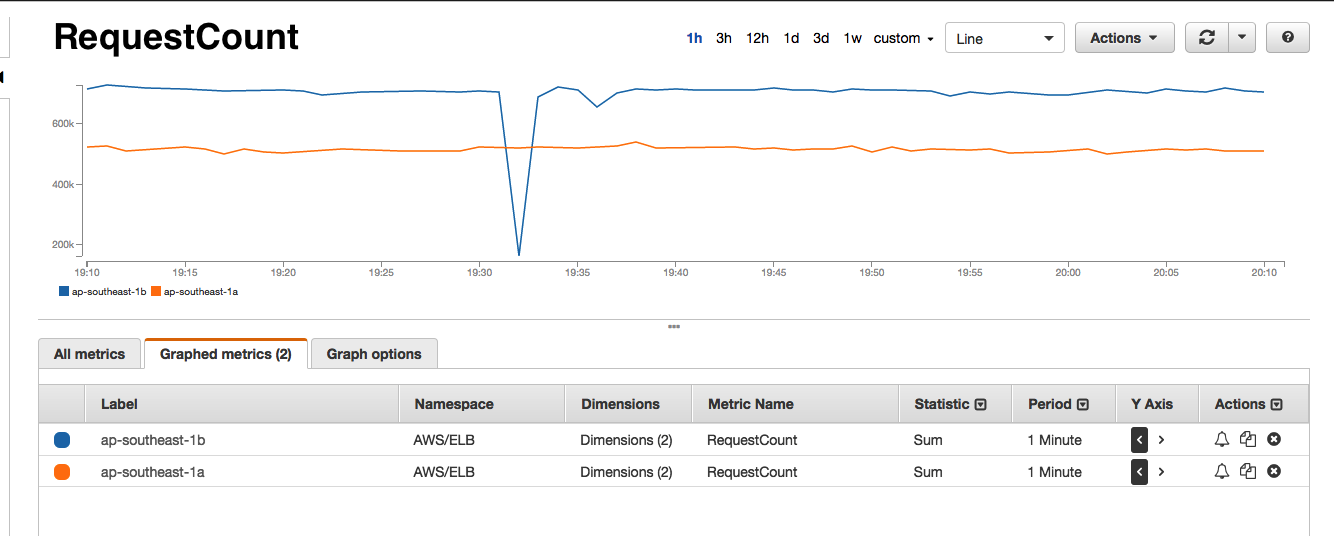
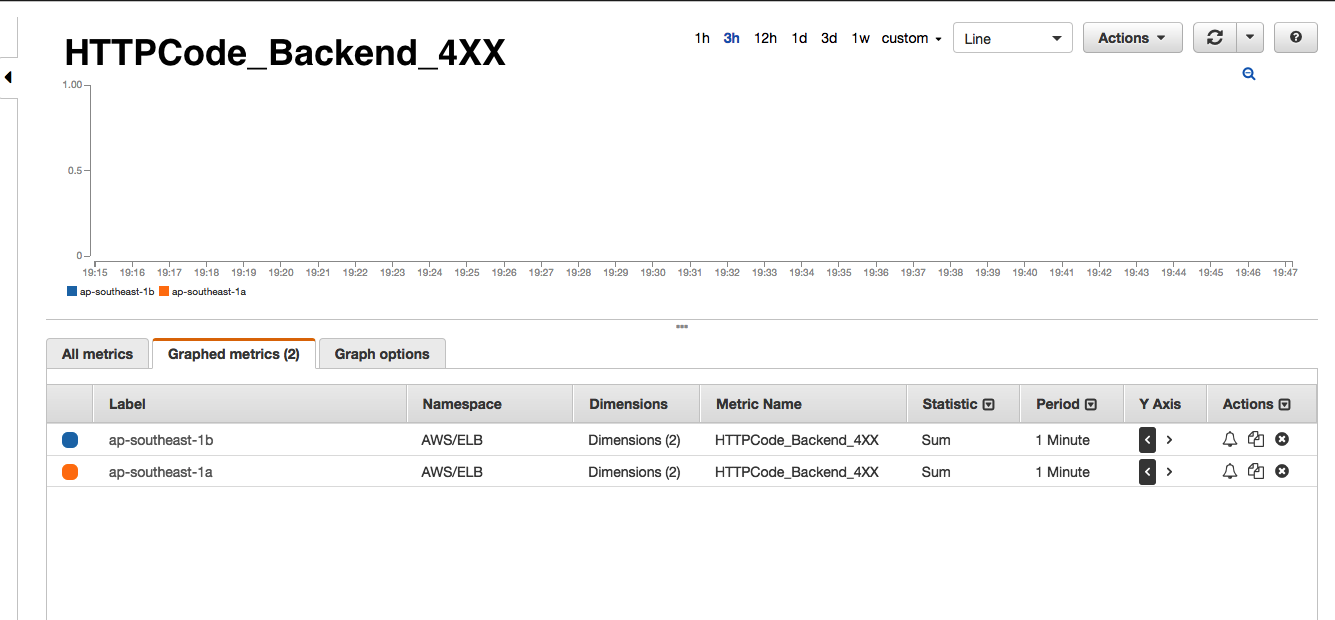
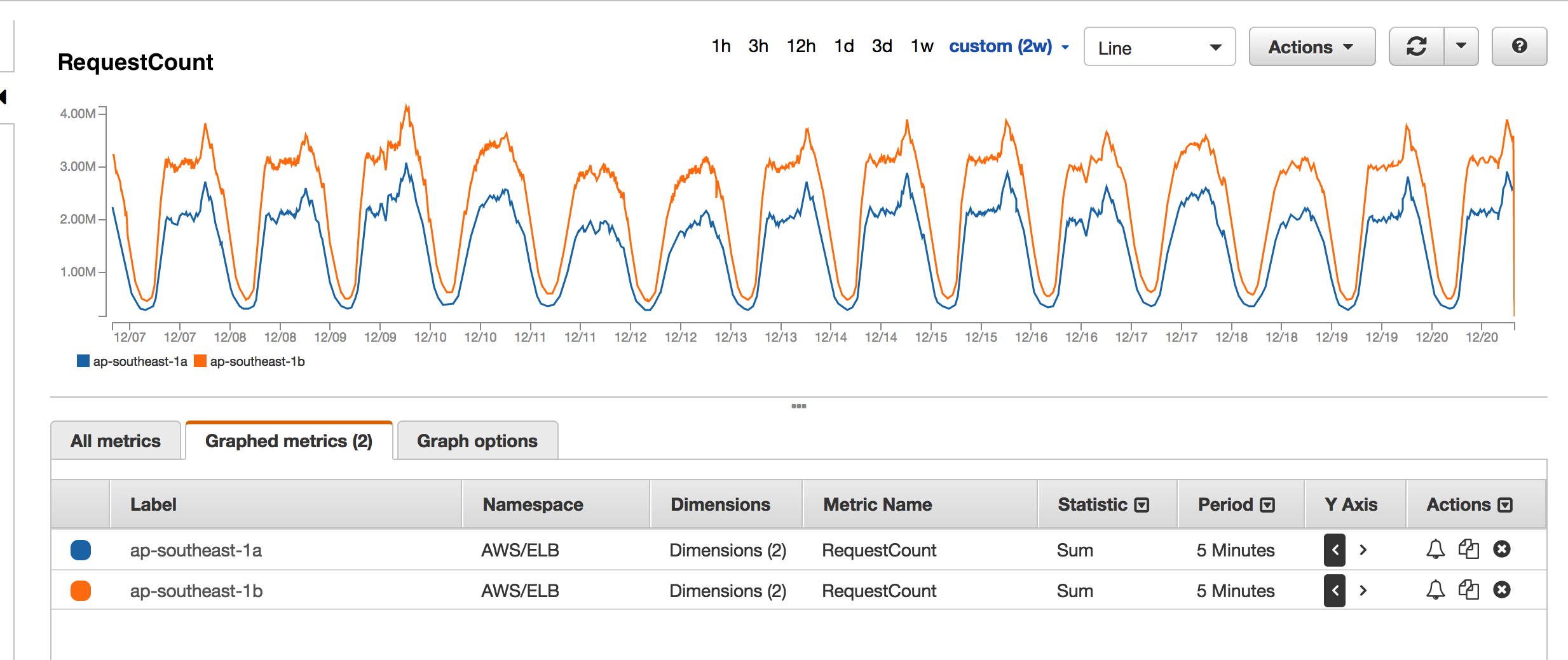
There are a few interesting points worth noting in above metrics:
- There are no errors from backend i.e. no 5XX or 4XX errors.
- Healthy and unhealthy instance count do not change i.e. all backend instances are healthy and serving the ELB.
- Backend 2XX count drops significantly i.e requests are not reaching backend instances.
- RequestCount drops significantly. It adds further proof of the above point that requests are not reaching the backend instances.
By jumping into the more detailed CloudWatch metrics, we are able to further confirm from our side that there is an uneven distribution of requests across the two different AZs. When we reach out to AWS’ tech support, they confirm that one of the many ELB nodes is somehow preferred and is causing a load imbalance across ELB nodes that in turn causes a single ELB node to occasionally fail and results in the ELB 5xx errors that we are seeing.
What is Happening?
Having confirmation of the issue from AWS is a start. Now we can confidently say that our monitoring systems are working correctly – something that is always good to know. After some internal discussions, we then came up with some probable causes:
- ELB is not load balancing correctly (Astrolabe ELB)
- ELB is misconfigured (Astrolabe ELB)
- DNS/IP caching is happening on the client side (Gothena)
- DNS is misconfigured and is not returning IP(s) in a round-robin manner (AWS DNS Server)
We once again reach out to AWS tech support to see if there are any underlying issues with ELB when running at high loads (we are serving upwards for 20k request per second on Astrolabe). In case you’re wondering, AWS ELB is just like any other web service, it can occasionally not work as expected . However, in this instance, they confirm that there are no such issues at this point.
Moving on to the second item on the list – ELB configurations. When configuring ELBs, there are a couple of things that you would want to look out for: make sure that you are connecting to the right backend ports, your Route 53 8 configuration for the ELB is correct and the same goes for the timeout settings. At one point, we suspected that our Route 53 configuration was not using CNAME records when pointing to the ELB but it turns out that for the case of ELBs, AWS actually provides an Alias Record Set that is essentially the same as a CNAME but with the added advantages of being able to reflect IP changes on the DNS server more quickly and not incurring additional ingress/egress charges for resolving Alias Record Set. Please refer to this to learn more about CNAME vs Alias record set.
Having eliminated the possibility of a misconfiguration on the ELB, we move on to see if Gothena itself is doing some sort of IP caching or if there is some sort DNS resolution misconfiguration that is happening on the service itself. While doing this investigation, we notice the same pattern in all other services that are calling Astrolabe (we record all outgoing connections from our services on Datadog). It just so happens that because Gothena is responsible for the bulk of the requests to Astrolabe that the problem is more prominent here than on other services. Knowing this, allows us to narrow the scope down to either a library that is used by all these services or some sort of server configuration that we were applying across the board. This is where things start to get a lot more interesting.
A Misconfigured Server? Is it Ubuntu? Is it Go?
Here at Grab, all of our servers are running on AWS with Ubuntu installed on them and almost all our services are written in Go, which means that we have a lot of common setup and code between services.
The first thing that we check is the number of connections created from one single Gothena instance to each individual ELB node. To do this, we first use the dig command to get the list of IP addresses to look for:
$ dig +short astrolabe.grab.com
172.18.2.38
172.18.2.209
172.18.1.10
172.18.1.37
Then, we proceed with running the netstat command to get connection counts from the Gothena instance to each of the ELB IPs retrieved above.
netstat | grep 172.18.2.38 | wc -l; netstat | grep 172.18.2.209 | wc -l; netstat | grep 172.18.1.10 | wc -l; netstat | grep 172.18.1.37 | wc -l;
And of course, the output of the command above shows that 1 of the 4 ELB nodes is preferred and the numbers are heavily skewed towards that one single node.
[0;32m172.18.1.9 | SUCCESS | rc=0 >>
0
0
58
0
[0m
[0;32m172.18.1.34 | SUCCESS | rc=0 >>
0
0
9
25
[0m
[0;32m172.18.2.137 | SUCCESS | rc=0 >>
0
100
0
0
[0m
[0;32m172.18.1.18 | SUCCESS | rc=0 >>
0
0
59
0
[0m
[0;32m172.18.1.96 | SUCCESS | rc=0 >>
0
0
49
5
[0m
[0;32m172.18.2.22 | SUCCESS | rc=0 >>
100
0
0
0
[0m
[0;32m172.18.2.66 | SUCCESS | rc=0 >>
100
0
0
0
[0m
[0;32m172.18.2.50 | SUCCESS | rc=0 >>
100
0
0
0
[0m
Here is the sum of total connections to each ELB node from all Gothena instances. This also explains an uneven distribution of requests across the two different AZs with 1b serving more requests than 1a.
172.18.2.38 -> 84
172.18.2.209 -> 66
172.18.1.10 -> 138
172.18.1.37 -> 87
And just to make sure that we did not just end up with a random outcome, we ran the same netstat command across a number of different services that are running on different servers and codebases. Surely enough, the same thing is observed on all of them. This narrows down the potential problem to either something in the Go code, in Ubuntu or in the configurations. With this newfound knowledge, the first thing that we look into is whether Ubuntu is somehow caching the DNS results. This quickly turned into a dead end as DNS results are never cached on Linux by default, it would only be cached if we are running a local DNS server like dnsmasq.d or have a modified host file which we do not have.
The next thing to do now is to dive into the code itself. And to do that, we spin up a new EC2 instance in a different subnet (this is important later on) but with the same configuration as the other servers to run some tests.
To help narrow down the problem points, we do some tests using cURL and a programme in Go, Python and Ruby to try out the different scenarios and check consistency. While running the programs, we also capture the DNS TCP packets (by using the tcpdump command below) to understand how many DNS queries are being made by each of the program. This helps us to understand if any DNS caching is happening.
$ tcpdump -l -n port 53
Curiously, when running the 5 requests to a health check URL from Go, Ruby, and Python, we see that cURL, Ruby and Python make 5 different DNS queries while Go only makes 1 DNS query. It turned out that cURL, Ruby and Python create new connections for each request by default while Go uses the same connection for multiple requests by default. The tests show that the DNS is correctly returning the IP addresses list in a round robin manner as cURL, Ruby, Python and Go programs were all making connections to both the IPs in an even manner. Note: Because we are running the tests on a different isolated environment, there are only 2 Astrolabe ELB nodes instead of the earlier 4.
For simplicity the curl and tcpdump output is shown here:
dharmarth@ip-172-21-12-187:~$ dig +short astrolabe.grab.com
172.21.2.115
172.21.1.107
dharmarth@ip-172-21-12-187:~$ curl -v http://astrolabe.grab.com/health_check
* Hostname was NOT found in DNS cache
* Trying 172.21.1.107...
* Connected to astrolabe.grab.com (172.21.1.107) port 80 (#0)
> GET /health_check HTTP/1.1
> User-Agent: curl/7.35.0
> Host: astrolabe.grab.com
> Accept: */*
>
< HTTP/1.1 200 OK
< Access-Control-Allow-Headers: Authorization
< Access-Control-Allow-Methods: GET,POST,OPTIONS
< Access-Control-Allow-Origin: *
< Content-Type: application/json; charset=utf-8
< Date: Mon, 09 Jan 2017 11:19:00 GMT
< Content-Length: 0
< Connection: keep-alive
<
* Connection #0 to host astrolabe.grab.com left intact
dharmarth@ip-172-21-12-187:~$ curl -v http://astrolabe.grab.com/health_check
* Hostname was NOT found in DNS cache
* Trying 172.21.2.115...
* Connected to astrolabe.grab.com (172.21.2.115) port 80 (#0)
> GET /health_check HTTP/1.1
> User-Agent: curl/7.35.0
> Host: astrolabe.grab.com
> Accept: */*
>
< HTTP/1.1 200 OK
< Access-Control-Allow-Headers: Authorization
< Access-Control-Allow-Methods: GET,POST,OPTIONS
< Access-Control-Allow-Origin: *
< Content-Type: application/json; charset=utf-8
< Date: Mon, 09 Jan 2017 11:19:01 GMT
< Content-Length: 0
< Connection: keep-alive
<
* Connection #0 to host astrolabe.grab.com left intact
dharmarth@ip-172-21-12-187:~$ sudo tcpdump -l -n port 53
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
09:29:37.906017 IP 172.21.12.187.37107 > 172.21.0.2.53: 19598+ A? astrolabe.grab.com. (43)
09:29:37.906030 IP 172.21.12.187.37107 > 172.21.0.2.53: 41742+ AAAA? astrolabe.grab.com. (43)
09:29:37.907518 IP 172.21.0.2.53 > 172.21.12.187.37107: 41742 0/1/0 (121)
09:29:37.909391 IP 172.21.0.2.53 > 172.21.12.187.37107: 19598 2/0/0 A 172.21.1.107, A 172.21.2.115 (75)
09:29:43.109745 IP 172.21.12.187.59043 > 172.21.0.2.53: 13434+ A? astrolabe.grab.com. (43)
09:29:43.109761 IP 172.21.12.187.59043 > 172.21.0.2.53: 63973+ AAAA? astrolabe.grab.com. (43)
09:29:43.110508 IP 172.21.0.2.53 > 172.21.12.187.59043: 13434 2/0/0 A 172.21.2.115, A 172.21.1.107 (75)
09:29:43.110575 IP 172.21.0.2.53 > 172.21.12.187.59043: 63973 0/1/0 (121)
The above tests make things even more interesting. We carefully kept the testing environment close to production in hopes of reproducing the issue yet everything seems to be working correctly. We run tests from the same OS image, same version of Golang, with the same HTTP client code and the same server configuration, but the issue of preferring a particular IP never happens.
How about running the tests on one of the staging Gothena instance? For simplicity, we’ll show curl and tcpdump output which is indicative of the issue faced by our Go service.
dharmarth@ip-172-21-2-17:~$ dig +short astrolabe.grab.com
172.21.2.115
172.21.1.107
dharmarth@ip-172-21-2-17:~$ curl -v http://astrolabe.grab.com/health_check
* Hostname was NOT found in DNS cache
* Trying 172.21.2.115...
* Connected to astrolabe.grab.com (172.21.2.115) port 80 (#0)
> GET /health_check HTTP/1.1
> User-Agent: curl/7.35.0
> Host: astrolabe.grab.com
> Accept: */*
>
< HTTP/1.1 200 OK
< Access-Control-Allow-Headers: Authorization
< Access-Control-Allow-Methods: GET,POST,OPTIONS
< Access-Control-Allow-Origin: *
< Content-Type: application/json; charset=utf-8
< Date: Fri, 06 Jan 2017 11:07:16 GMT
< Content-Length: 0
< Connection: keep-alive
<
* Connection #0 to host astrolabe.grab.com left intact
dharmarth@ip-172-21-2-17:~$ curl -v http://astrolabe.grab.com/health_check
* Hostname was NOT found in DNS cache
* Trying 172.21.2.115...
* Connected to astrolabe.grab.com (172.21.2.115) port 80 (#0)
> GET /health_check HTTP/1.1
> User-Agent: curl/7.35.0
> Host: astrolabe.stg-myteksi.com
> Accept: */*
>
< HTTP/1.1 200 OK
< Access-Control-Allow-Headers: Authorization
< Access-Control-Allow-Methods: GET,POST,OPTIONS
< Access-Control-Allow-Origin: *
< Content-Type: application/json; charset=utf-8
< Date: Fri, 06 Jan 2017 11:07:19 GMT
< Content-Length: 0
< Connection: keep-alive
<
* Connection #0 to host astrolabe.grab.com left intact
dharmarth@ip-172-21-2-17:~# tcpdump -l -n port 53 | grep -A4 -B1 astrolabe
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
11:10:00.072042 IP 172.21.0.2.53 > 172.21.2.17.51937: 25522 2/0/0 A 172.21.3.78, A 172.21.0.172 (75)
11:10:01.893912 IP 172.21.2.17.28047 > 172.21.0.2.53: 11695+ A? astrolabe.grab.com. (43)
11:10:01.893922 IP 172.21.2.17.28047 > 172.21.0.2.53: 13413+ AAAA? astrolabe.grab.com. (43)
11:10:01.895053 IP 172.21.0.2.53 > 172.21.2.17.28047: 13413 0/1/0 (121)
11:10:02.012936 IP 172.21.0.2.53 > 172.21.2.17.28047: 11695 2/0/0 A 172.21.1.107, A 172.21.2.115 (75)
11:10:04.242975 IP 172.21.2.17.51776 > 172.21.0.2.53: 54031+ A? kinesis.ap-southeast-1.amazonaws.com. (54)
11:10:04.242984 IP 172.21.2.17.51776 > 172.21.0.2.53: 49840+ AAAA? kinesis.ap-southeast-1.amazonaws.com. (54)
--
11:10:07.397387 IP 172.21.0.2.53 > 172.21.2.17.18405: 1772 0/1/0 (119)
11:10:08.644113 IP 172.21.2.17.12129 > 172.21.0.2.53: 27050+ A? astrolabe.grab.com. (43)
11:10:08.644124 IP 172.21.2.17.12129 > 172.21.0.2.53: 3418+ AAAA? astrolabe.grab.com. (43)
11:10:08.644378 IP 172.21.0.2.53 > 172.21.2.17.12129: 3418 0/1/0 (121)
11:10:08.644378 IP 172.21.0.2.53 > 172.21.2.17.12129: 27050 2/0/0 A 172.21.2.115, A 172.21.1.107 (75)
11:10:08.999919 IP 172.21.2.17.12365 > 172.21.0.2.53: 55314+ A? kinesis.ap-southeast-1.amazonaws.com. (54)
11:10:08.999928 IP 172.21.2.17.12365 > 172.21.0.2.53: 14140+ AAAA? kinesis.ap-southeast-1.amazonaws.com. (54)
^C132 packets captured
136 packets received by filter
0 packets dropped by kernel
It didn’t work as expected in cURL. There is no IP caching, cURL is making DNS queries. We can see DNS is returning output correctly as per round robin. But somehow it’s still choosing the same one IP to connect to.
With all that, we have indirectly confirmed that the DNS round robin behaviour is working as expected and thus leaving us with nothing else left on the list. Everybody that participated in the discussion up to this point was equally dumbfounded.
After that long fruitless investigation, one question comes to mind. Which IP address will get the priority when the DNS results contain more than one IP address? A quick search on Google gives the following StackOverflow result with the following snippet:
A DNS server resolving a query, may prioritize the order in which it uses the listed servers based on historical response time data (RFC1035 section 7.2). It may also prioritize by closer sub-net (I have seen this in RFC but don’t recall which). If no history or sub-net priority is available, it may choose by random, or simply pick the first one. I have seen DNS server implementations doing various combinations of above.
Well, that is disappointing, no new insights to preen from that. Having spent the whole day looking at the same issue, we were ready to call it a night while having the gut feeling that something must be misconfigured on the servers.
If you are interested in finding the answers from the clues above, please hold off reading the next section and see if you can figure it out by yourself.
Breakthrough
Coming in fresh from having a good night’s sleep, the issue managed to get the attention of even more Grab engineers that happily jumped in to help investigate the issue together. Then the magical clue happened, someone with an eye for networking spotted that the requests were always going to the ELB node that has the same subnet as the client that was initiating the request. Another engineer then quickly found RFC 3484 that talked about sorting of source and destination IP addresses. That was it! The IP addresses were always being sorted and that resulted in one ELB node getting more traffic than the rest.
Then an article surfaced that suggests disabling IPv6 for C-based applications. We quickly try that with our Go programme which does not work. But when we then try running the same code with Cgo 9 enabled as the DNS resolver it leads to success! The request count to the different ELB nodes is now properly balanced. Hooray!
If you have been following this post, you would have figured that the issue is impacting all of our internal services. But as stated earlier, the load on the other ELBs is not high as Astrolabe. So we do not see any issues with the other services, The traffic to Astrolabe has been steadily increasing over the past few months, which might have hit some ELB limits and causing 5XX errors.
Alternatives Considered:
- Move Gothena instances into a different subnet
- Move all ELBs into a different subnet
- Use service discovery to connect internal services and bypass ELB
- Use weighted DNS + bunch of other config to balance the load
All the 4 solutions could solve our problem too but seeing how disabling IPv6 and using Cgo for DNS resolution required the least effort, we went with that.
Stay tuned for part 2 which will go into detail about the RFC, why disabling IPv6 and using Cgo works as well as what our plans are for the future.
Note: All the sensitive information in this article has been modified and does not reflect the true state of our systems.
Footnotes
-
Gothena – An internal service that is in-charge of all driver communications logic. ↩
-
AWS ELB – AWS Elastic Load Balancer, a load balancing service that is offered by AWS. There can be more than one instance representing an AWS ELB. DNS RoundRobin is used to distribute connections among AWS ELB instances. ↩
-
ELB HTTP 5xx errors – An HTTP 5xx error that is returned by the ELB instead of the backend service. ↩
-
Astrolabe – An internal service that is in charge of storing and processing all driver location data. ↩
-
ELB SurgeQueue - The number of requests that are pending routing. ↩
-
ELB SpillOver - The total number of requests that were rejected because the surge queue is full. ↩
-
ELB Latency - The time elapsed, in seconds, after the request leaves the load balancer until the headers of the response are received. ↩
-
AWS Route 53 - A managed cloud DNS solution provided by AWS. ↩
-
Cgo - Cgo enables the creation of Go packages that call C code. ↩