Uncovering the Truth Behind Lua and Redis Data Consistency
Our team at Grab uses Redis as one of our message queues. The Redis server is deployed in a master/replica setup. Quite recently, we have been noticing a spike in the CPU usage of the Redis replicas every time we deploy our service, even when the replicas are not in use and when there’s no read traffic to it. However, the issue is resolved once we reboot the replica.
Because a reboot of the replica fixes the issue every time, we thought that it might be due to some Elasticache replication issues and didn’t pursue further. However, a recent Redis failover brought this to our attention again. After the failover, the problematic replica becomes the new master and its CPU immediately goes to 100% with the read traffic, which essentially means the cluster is not functional after the failover. And this time we investigated the issue with new vigour. What we found in our investigation led us to deep dive into the details of Redis replication and its implementation of Hash.
Did you know that Redis master/replica can become inconsistent in certain scenarios?
Did you know the encoding of Hash objects on the master and the replica are different even if the writing operations are exactly the same and in the same order? Read on to find out why.
The Problem
The following graph shows the CPU utilisation of the master vs. the replica immediately after our service is deployed.
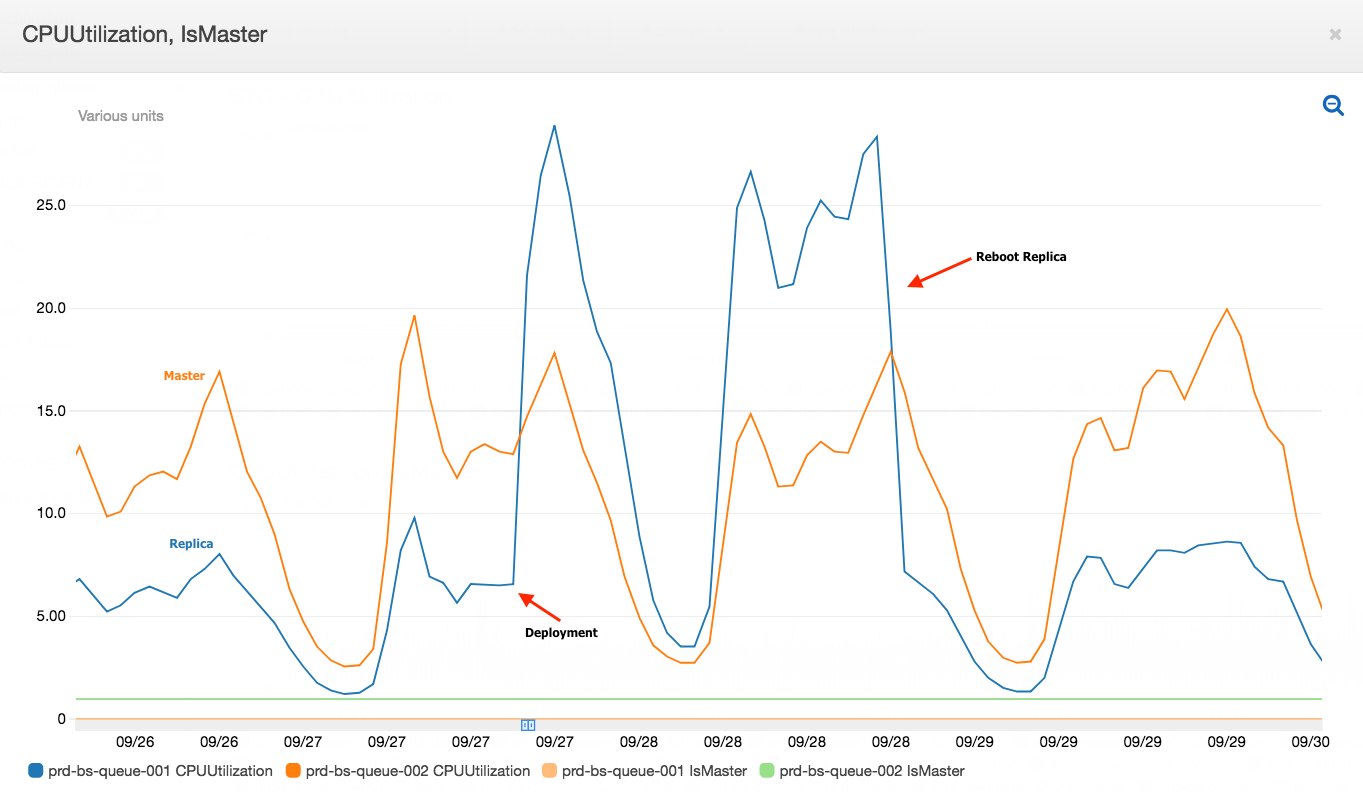
From the graph, you can see the following CPU usage trends. Replica’s CPU usage:
- Increases immediately after our service is deployed.
- Spikes higher than the master after a certain time.
- Get’s back to normal after a reboot.
Cursory Investigation
Because the spike occurs only when we deploy our service, we scrutinised all the scripts that were triggered immediately after the deployment. Lua monitor script was identified as a possible suspect. The script redistributes inactive service instances’ messages in the queue to active service instances so that messages can be processed by other healthy instances.
We ran a few experiments related to the Lua monitor script using the Redis monitor command to compare the script’s behaviour on master and the replica. A side note, because this command causes performance degradation, use it with discretion. Coming back to the script, we were surprised to note that the monitor script behaves differently between the master and the replica:
- Redis executes the script separately on the master and the replica. We expected the script to execute only on master and the resulting changes to be replicated to the secondary.
- The Redis command
HGETALLused in the script returns the hash keys in a different order on master compared to the replica.
Due to the above reasons, the script causes data inconsistencies between the master and its replica. From that point on, the data between the master and the replica keeps diverging till they become completely distinct. Due to the inconsistency, the data on the secondary does not get deleted correctly thereby growing into an extremely large dataset. Any further operations on the large dataset requires a higher CPU usage, which explains why the replica’s CPU usage is higher than the master.
During replica reboots, the data gets synced and consistent again, which is why the CPU usage gets to normal values after rebooting.
Diving Deeper on HGETALL
We knew that the keys of a hash are not ordered and we should not rely on the order. But it still puzzled us that the order is different even when the writing sequence is the same between the master and the replica. Plus the fact that the orders are always the same in our local environment with a similar setup made us even more curious.
So to better understand the underlying magic of Redis and to avoid similar bugs in the future, we decided to hammer on and read the Redis source code to get more details.
HGETALL Command Handling Code
The HGETALL command is handled by the function genericHgetallCommand and it further calls hashTypeNext to iterate through the Hash object. A snippet of the code is shown as follows:
/* Move to the next entry in the hash. Return C_OK when the next entry
* could be found and C_ERR when the iterator reaches the end. */
int hashTypeNext(hashTypeIterator *hi) {
if (hi->encoding == OBJ_ENCODING_ZIPLIST) {
// call zipListNext
} else if (hi->encoding == OBJ_ENCODING_HT) {
// call dictNext
} else {
serverPanic("Unknown hash encoding");
}
return C_OK;
}
From the code snippet, you can see that the Redis Hash object actually has two underlying representations:
- ZIPLIST
- HASHTABLE (dict)
A bit of research online helped us understand that, to save memory, Redis chooses between the two hash representations based on the following limits:
- By default, Redis stores the Hash object as a zipped list when the hash has less than 512 entries and when each element’s size is smaller than 64 bytes.
- If either limit is exceeded, Redis converts the list to a hashtable, and this is irreversible. That is, Redis won’t convert the hashtable back to a list again, even if the entries/size falls below the limit.
Eureka Moment
Based on this understanding, we checked the encoding of the problematic hash in staging.
stg-bookings-qu-002.pcxebj.0001.apse1.cache.amazonaws.com:6379> object encoding queue_stats
"hashtable"
stg-bookings-qu-001.pcxebj.0001.apse1.cache.amazonaws.com:6379> object encoding queue_stats
"ziplist"
To our surprise, the encodings of the Hash object on the master and its replica were different. Which means if we add or delete elements in the hash, the sequence of the keys won’t be the same due to hashtable operation vs. list operation!
Now that we have identified the root cause, we were still curious about the difference in encoding between the master and the replica.
How Could the Underlying Representations be Different?
We reasoned, “If the master and its replica’s writing operations are exactly the same and in the same order, why are the underlying representations still different?”
To answer this, we further looked through the Redis source to find all the possible places that a Hash object’s representation could be changed and soon found the following code snippet:
/* Load a Redis object of the specified type from the specified file.
* On success a newly allocated object is returned, otherwise NULL. */
robj *rdbLoadObject(int rdbtype, rio *rdb) {
//...
if (rdbtype == RDB_TYPE_HASH) {
//...
o = createHashObject(); // ziplist
/* Too many entries? Use a hash table. */
if (len > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
//...
}
}
Reading through the code we understand the following behaviour:
- When restoring from an RDB file, Redis creates a ziplist first for Hash objects.
- Only when the size of the Hash object is greater than the
hash_max_ziplist_entries, the ziplist is converted to a hashtable.
So, if you have a Redis Hash object encoded as a hashtable with its length less than hash_max_ziplist_entries (512) in the master, when you set up a replica, it is encoded as a ziplist.
We were able to verify this behaviour in our local setup as well.
How did We Fix it?
We could use the following two approaches to address this issue:
- Enable script effect replication mode. This tells Redis to replicate the commands generated by the script instead of running the whole script on the replica. One disadvantage to using this approach is that it adds network traffic between the master and the replica.
- Ensure the behaviour of the Lua monitor script is deterministic. In our case, we can do this by sorting the outputs of HKEYS/HGETALL.
We chose the latter approach because:
- The Hash object is pretty small ( < 30 elements) so the sorting overhead is low, less than 1ms for 100 elements based on our tests.
- Replicating our script effect would end up replicating thousands of Redis writing commands on the secondary causing a much higher overhead compared to replicating just the script.
After the fix, the CPU usage of the replica remained in range after each deployment. This also prevented the Redis cluster from being destroyed in the event of a master failover.
Key Takeaways
In addition to writing clear and maintainable code, it’s equally important to understand the underlying storage layer that you are dealing with to produce efficient and bug-free code.
The following are some of the key learnings on Redis:
- Redis does not guarantee the consistency between master and its replica nodes when Lua scripts are used. You have to ensure that the behaviour of the scripts are deterministic to avoid data inconsistency.
- Redis replicates the whole Lua script instead of the resulting commands to the replica. However, this is the default behaviour and you can disable it.
- To save memory, Redis uses different representations for Hash. Your Hash object could be stored as a list in memory or a hashtable. This is not guaranteed to be the same across the master and its replicas.
Join us
Grab is a leading superapp in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across over 400 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!