
Using Grab’s Trust Counter Service to Detect Fraud Successfully
Background
Fraud is not a new phenomenon, but with the rise of the digital economy it has taken different and aggressive forms. Over the last decade, novel ways to exploit technology have appeared, and as a result, millions of people have been impacted and millions of dollars in revenue have been lost. According to ACFE survey, companies lost USD6.3 billion due to fraud. Organisations lose 5% of its revenue annually due to fraud.
In this blog, we take a closer look at how we developed an anti-fraud solution using the Counter service, which can be an indispensable tool in the highly complex world of fraud detection.
Anti-fraud Solution Using Counters
At Grab, we detect fraud by deploying data science, analytics, and engineering tools to search for anomalous and suspicious transactions, or to identify high-risk individuals who are likely to commit fraud. Grab’s Trust Platform team provides a common anti-fraud solution across a variety of business verticals, such as transportation, payment, food, and safety. The team builds tools for managing data feeds, creates SDK for engineering integration, and builds rules engines and consoles for fraud detection.
One example of fraudulent behaviour could be that of an individual who masquerades as both driver and passenger, and makes cashless payments to get promotions, for example, earn a one dollar rebate in the next transaction.In our system, we analyse real time booking and payment signals, compare it with the historical data of the driver and passenger pair, and create rules using the rule engine. We count the number of driver and passenger pairs at a given time frame. This counter is provided as an input to the rule.If the counter value exceeds a predefined threshold value, the rule evaluates it as a fraud transaction. We send this verdict back to the booking service.
The Conventional Method
Fraud detection is a job that requires cross-functional teams like data scientists, data analysts, data engineers, and backend engineers to work together. Usually data scientists or data analysts come up with an offline idea and apply it to real-time traffic. For example, a rule gets invented after brainstorming sessions by data scientists and data analysts. In the conventional method, the rule needs to be communicated to engineers.
Automated Solution Using the Counter Service
To overcome the challenges in the conventional method, the Trust platform team decided to come out with the Counter service, a self-service platform, which provides management tools for users, and a computing engine for integrating with the backend services. This service provides an interface, such as a UI based rule editor and data feed, so that analysts can experiment and create rules without interacting with engineers. The platform team also decided to provide different data contracts, APIs, and SDKs to engineers so that the business verticals can use it quickly and easily.
The Major Engineering Challenges Faced in Designing the Counter Service
There are millions of transactions happening at Grab every day, which implies we needed to perform billions of fraud and safety detections. As seen from the example shared earlier, most predictions require a group of counters. In the above use case, we need to know how many counts of the cashless payment happened for a driver and passenger pair. Due to the scale of Grab’s business, the potential combinations of drivers and passengers could be exponential. However, this is only one use case. So imagine that there could be hundreds of counters for different use cases. Hence, it’s important that we provide a platform for stakeholders to manage counters.
Read on to learn about some of the common challenges we faced.
Scalability
As mentioned above, we could potentially have an exponential number of passengers and drivers in a single counter. So it’s a great challenge to store the counters in the database, read, and query them in real-time. When there are billions of counter keys across a long period of time, the Trust team had to find a scalable way to write and fetch keys effectively and meet the client’s SLA.
Self-serving
A counter is usually invented by data scientists or analysts and used by engineers. For example, every time a new type of counter is needed from data scientists, developers need to manually make code changes, such as adding a new stream, capturing related data sets for the counter, and storing it on the fraud service, then doing a deployment to make the counters ready. It usually takes two or more weeks for the whole iteration, and if there are any changes from the data analysts’ side, which happens often, the situation loops again. The team had to come up with a solution to prevent the long loop of manual tasks by coming out with a self-serving interface.
Manageable and Extendable
Due to a lack of connection between real-time and offline data, data analysts and data scientists did not have a clear picture of what is written in the counters. That’s because the conventional counter data were stored in Redis database to satisfy the query SLA. They could not track the correctness of counter value, or its history. With the new solution, the stakeholders can get a real-time picture of what is stored in the counters using the data engineering tools.
The Machine Learning Challenges Solved by the Counter Service
The Counter service plays an important role in our Machine Learning (ML) workflow.
Data Consistency Challenge/Issue
Most of the machine learning workflows need dedicated input data. However, when there is an anti-fraud model that is trained using offline data from the data lake, it is difficult to use the same model in real-time. This is because the model lacks the data contract and the consistency with the data source. In this case, the Counter service becomes a type of data source by providing the value of counters to file system.
ML Featuring
Counters are important features for the ML models. Imagine there is a new invention of counters, which data scientists need to evaluate. We need to provide a historical data set for counters to work. The Counter service provides a counter replay feature, which allows data scientists to simulate the counters via historical payload.
In general, the Counter service is a bridge between online and offline datasets, data scientists, and engineers. There was technical debt with regards to data consistency and automation on the ML pipeline, and the Counter service closed this loop.
How We Designed the Counter Service
We followed the principle of asynchronised data ingestion, and synchronised transaction for designing the Counter service.
The diagram shows how the counters are generated and saved to database.
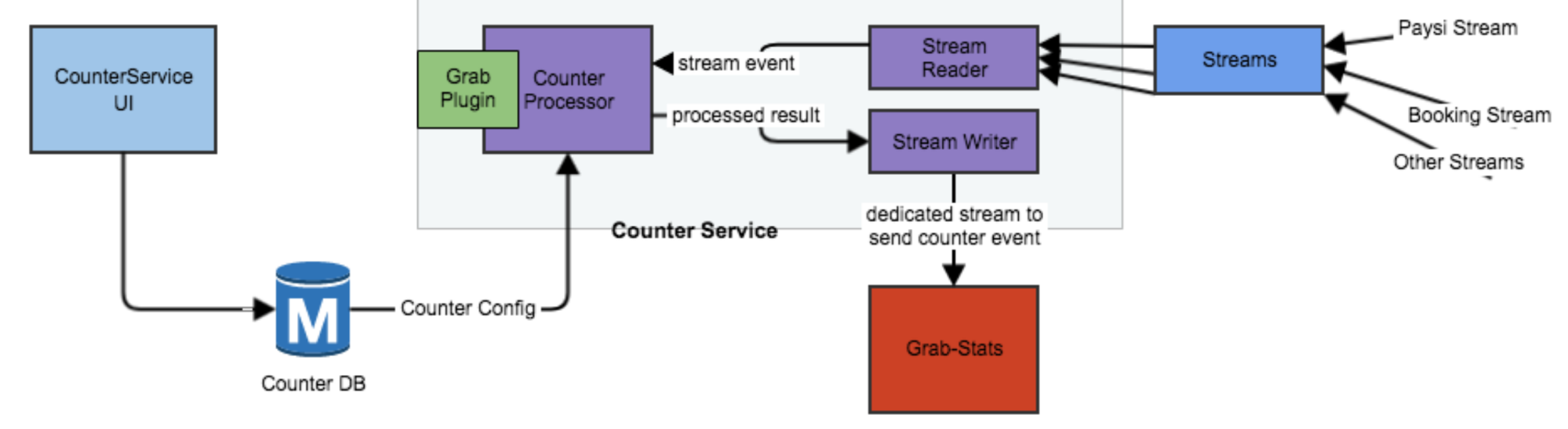
Counter creation workflow
- User opens the Counter Creation UI and creates a new key “fraud:counter:counter_name”.
- Configures required fields.
- The Counter service monitors the new counter-creation, puts a new counter into load script storage, and starts processing new counter events (see Counter Write below).
Counter write workflow
- The Counter service monitors multiple streams, assembles extra data from online data services (i.e. Common Data Service (CDS), passenger service, hydra service, etc), so that rich dataset would also be available for editors on each stream resource.
- The Counter Processor evaluates the user-configured expression and writes the evaluated values to the dedicated Grab-Stats stream using the GrabPlugin tool.
Counter read workflow
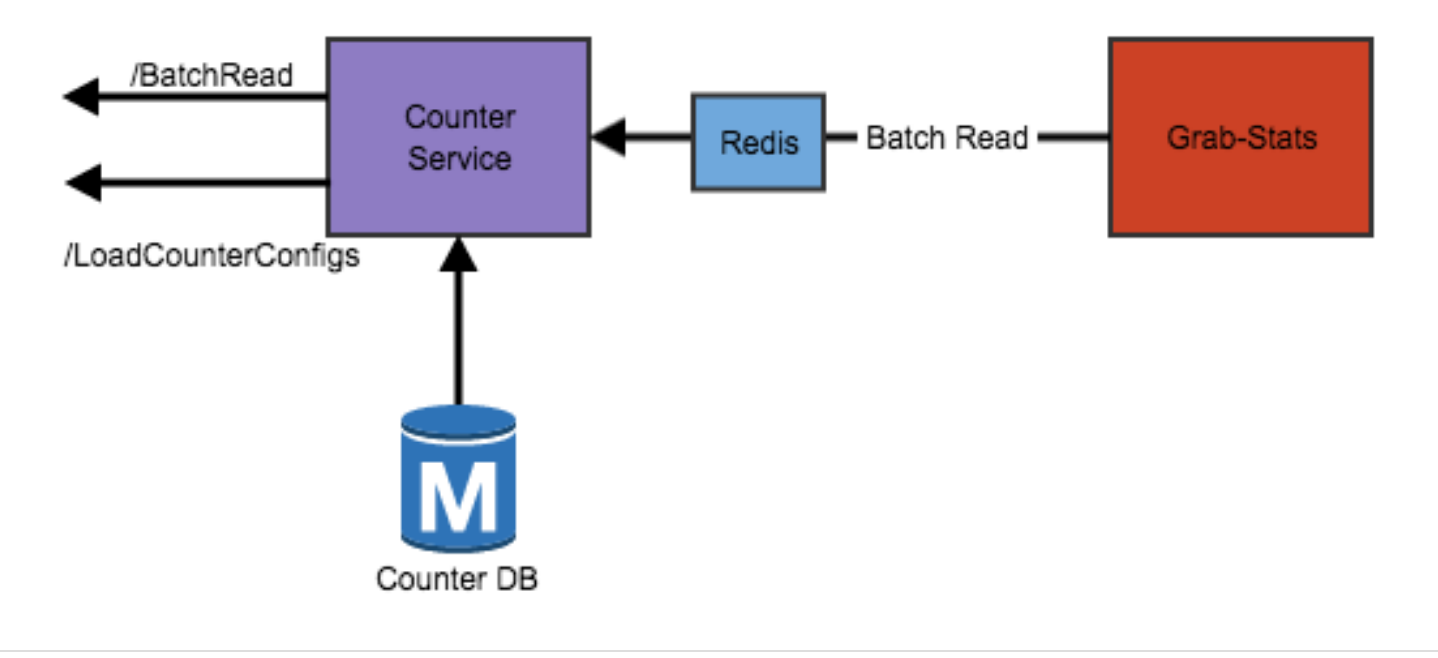
We use Grab-Stats as our storage service. Basically Grab-Stats runs above ScyllaDB, which is a distributed NoSQL data store. We use ScyllaDB because of its good performance on aggregation in memory to deal with the time series dataset. In comparison with in-memory storage like AWS elasticCache, it is 10 times cheaper and as reliable as AWS in terms of stability. The p99 of reading from ScyllaDB is less than 150ms which satisfies our SLA.
How We Improved the Counter Service Performance
We used the multi-buckets strategy to improve the Counter service performance.
Background
There are different time windows when you perform a query. Some counters are time sensitive so that it needs to know what happened in the last 30 or 60 minutes. Some other counters focus on the long term and need to know the events in the last 30 or 90 days.
From a transactional database perspective, it’s not possible to serve small range as well as long term events at the same time. This is because the more the need for the accuracy of the data and the longer the time range, the more aggregations need to happen on database. Which means we would not be able to satisfy the SLA. Otherwise we will need to block other process which leads to the service downgrade.
Solution for Improving the Query
We resolved this problem by using different granularities of the tables. We pre-aggregated the signals into different time buckets, such as 15min, 1 hour, and 1 day.
When a request comes in, the time-range of the request will be divided by the buckets, and the results are conquered. For example, if there is a request for 9/10 23:15:20 to 9/12 17:20:18, the handler will query 15min buckets within the hour. It will query for hourly buckets for the same day. And it will query the daily buckets for the rest of 2 days. This way, we avoid doing heavy aggregations, but still keep the accuracy in 15 minutes level in a scalable response time.
Counter Service UI
We allowed data analysts and data scientists to onboard counters by themselves, from a dedicated web portal. After the counter is submitted, the Counter service takes care of the integration and parsing the logic at runtime.
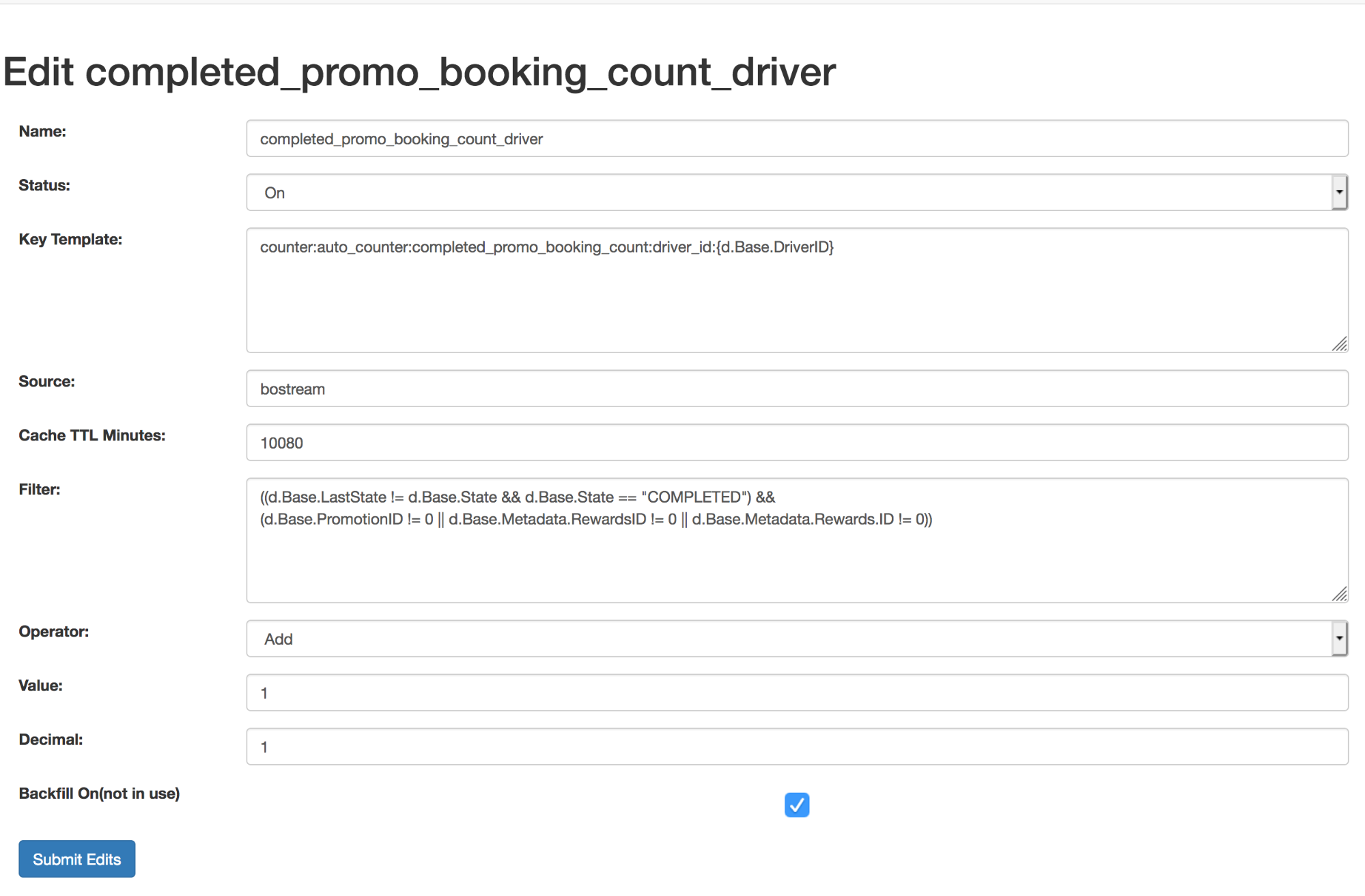
Backend Integration
We provide SDK for quicker and better integration. The engineers only need to provide the counter identifier ID (which is shown in the UI) and the time duration in the query. Under the hood we provide a GRPC protocol to communicate across services. We divide the query time window to smaller granularities, fetching from different time series tables and then conquering the result. We are also providing a short TTL cache layer to take the uncommon traffic from client such as network retry or traffic throttle. Our QPS are designed to target 100K.
Monitoring the Counter Service
The Counter service dashboard helps to track the human errors while editing the counters in real-time. The Counter service sends alerts to slack channel to notify users if there is any error.
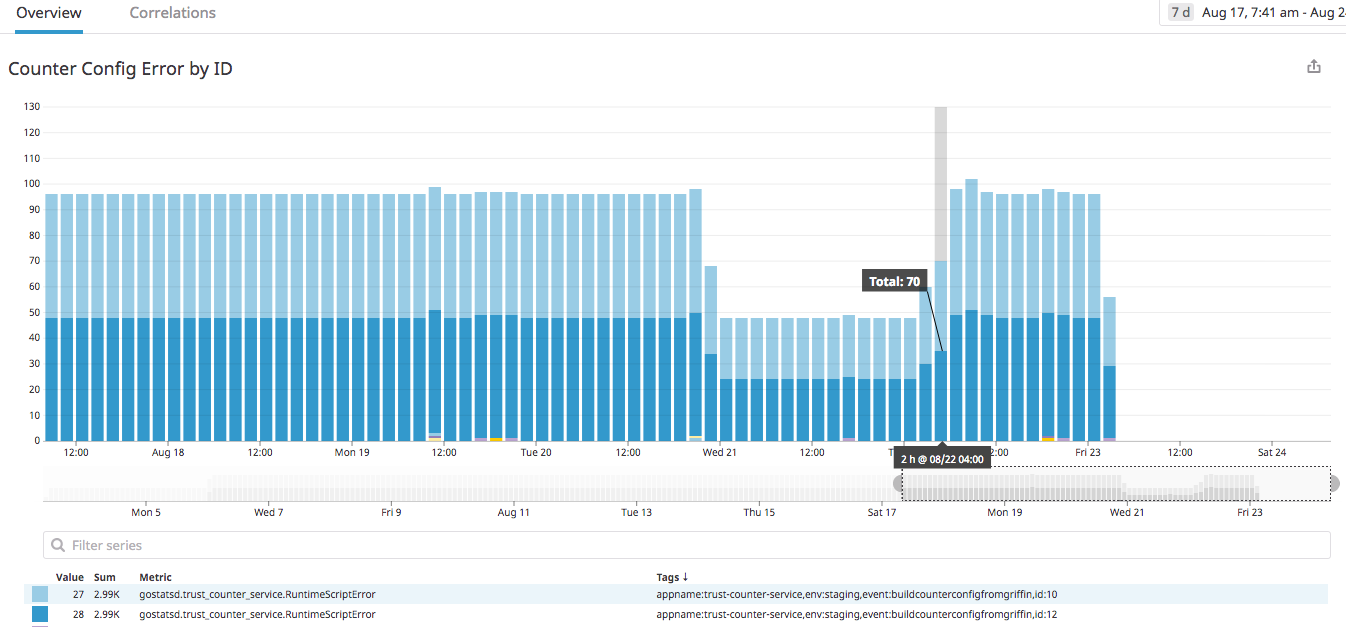
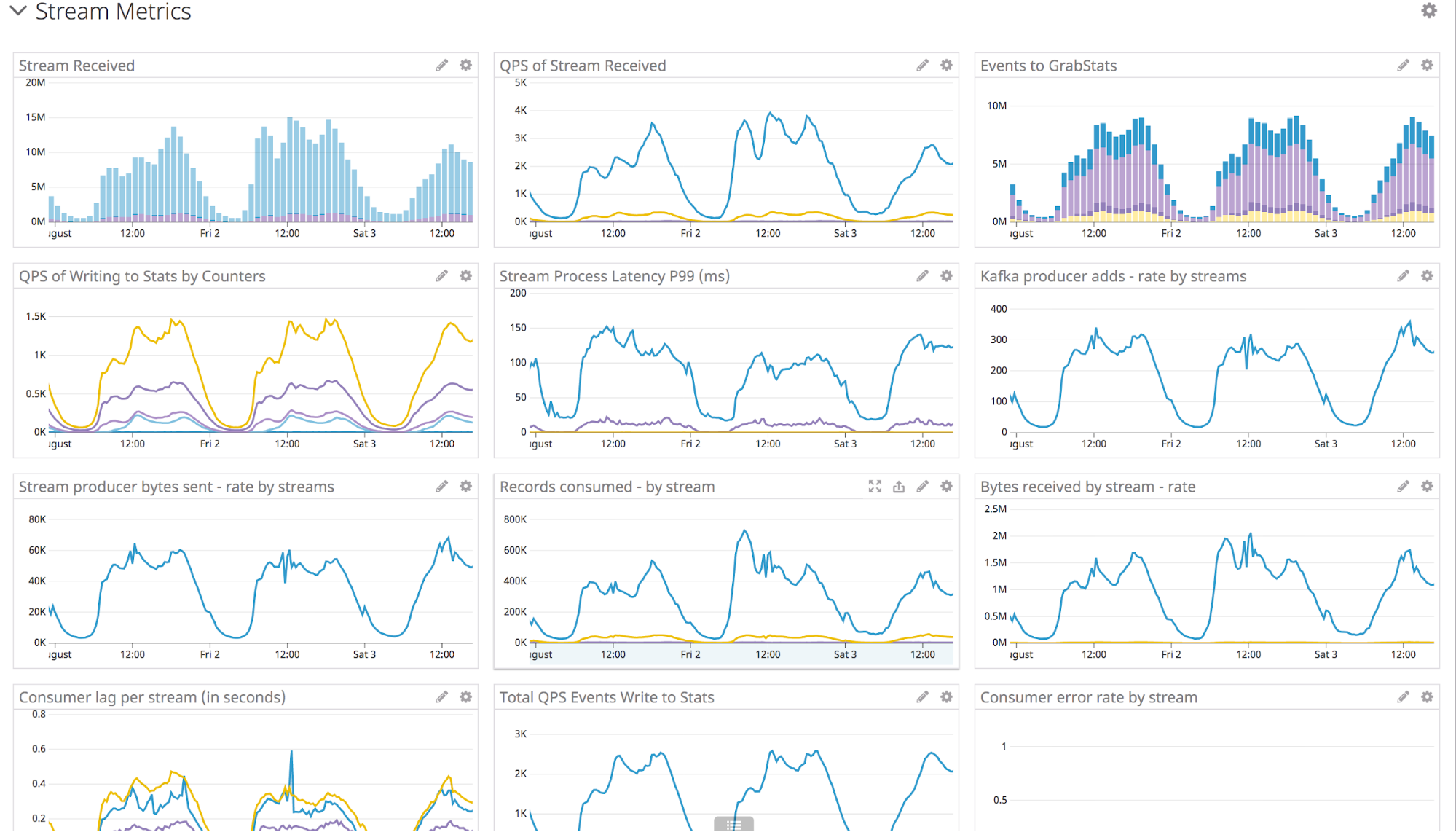
We setup Datadog for monitoring multiple system metrics. The figure below shows a portion of stream processing and counter writing. In the example below, the total stream QPS would reach 5k at peak hour, and the total counter saved to storage tier is about 4k. It will keep climbing without an upper limit, when more counters are onboarded.
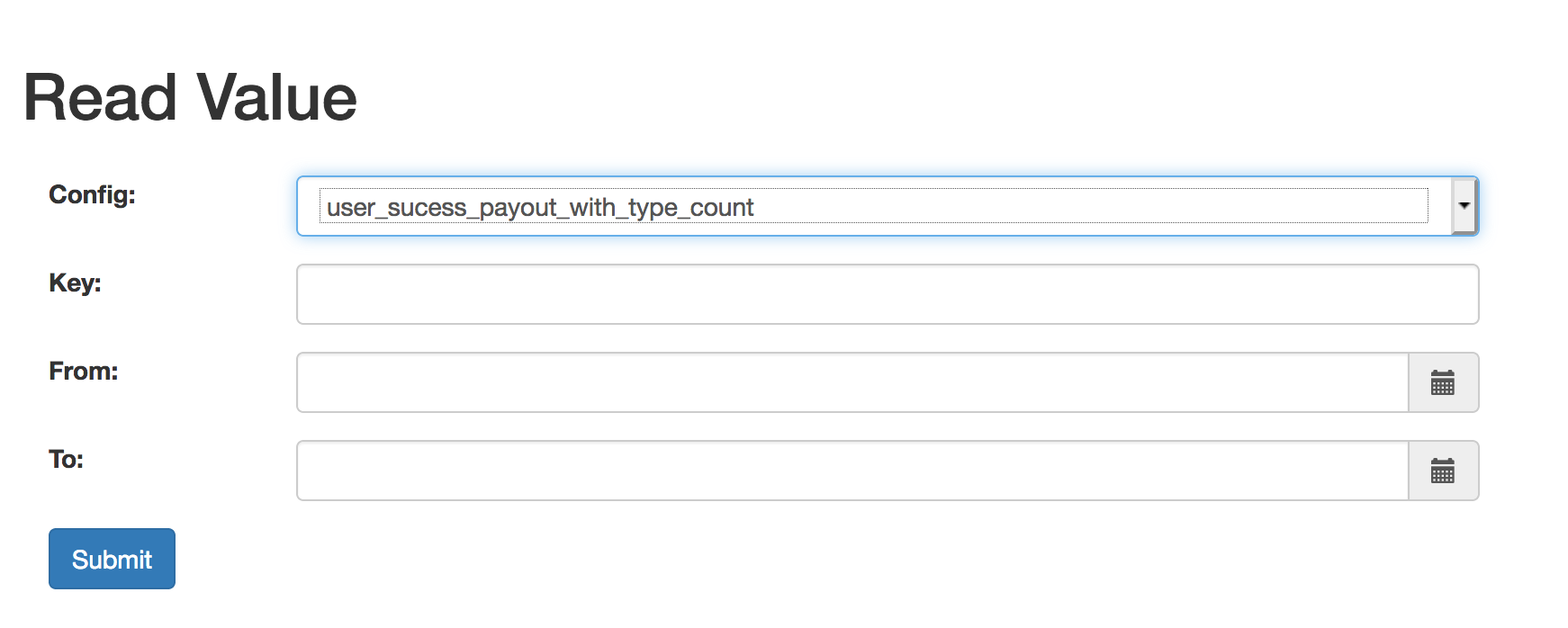
The Counter service UI portal also helps users to fetch real-time counter results for verification purposes.
Future Plans
Here’s what we plan to do in the near future to improve the Counter service.
Close the ML Workflow Loop
As mentioned above, we plan to send the resource payload of the Counter service to the offline data lake, in order to complete the counter replay function for data scientists. We are working on the project called “time traveler”. As the name indicates, it is used not only for serving the online transactional data, but also supports historical data analytics, and provides more flexibility on counter inventions and experiments.
There are more automation steps we plan to do, such as adding a replay button on the web portal, and hooking up with the offline big data engine to trigger the analytics jobs. The performance metrics will be collected and displayed on the web portal. A single platform would be able to manage both the online and offline data.
Integration with Griffin
Griffin is our rule engine. Counters are sometimes an input to a particular rule, and one rule usually needs many counters to work together. We need to provide a better integration with Griffin on backend. We plan to minimise the current engineering effort when using counters on Griffin. A counter then becomes an automated input variable on Griffin, which can be configured on the web portal by any users.
Speak to us
GrabDefence is a proprietary fraud prevention platform built by Grab, Southeast Asia’s leading superapp. Since 2019, the GrabDefence team has shared its fraud management capabilities and platform with enterprises and startups to leverage Grab’s advanced AI/ML models, hyper local insights and patented device intelligence technologies.
To learn more about GrabDefence or to speak to our fraud management experts, contact us at gd.contact@grabtaxi.com.