
Zero traffic cost for Kafka consumers
Introduction
Coban, Grab’s real-time data streaming platform team, has been building an ecosystem around Kafka, serving all Grab verticals. Along with stability and performance, one of our priorities is also cost efficiency.
In this article, we explain how the Coban team has substantially reduced Grab’s annual cost for data streaming by enabling Kafka consumers to fetch from the closest replica.
Problem statement
The Grab platform is primarily hosted on AWS cloud, located in one region, spanning over three Availability Zones (AZs). When it comes to data streaming, both the Kafka brokers and Kafka clients run across these three AZs.
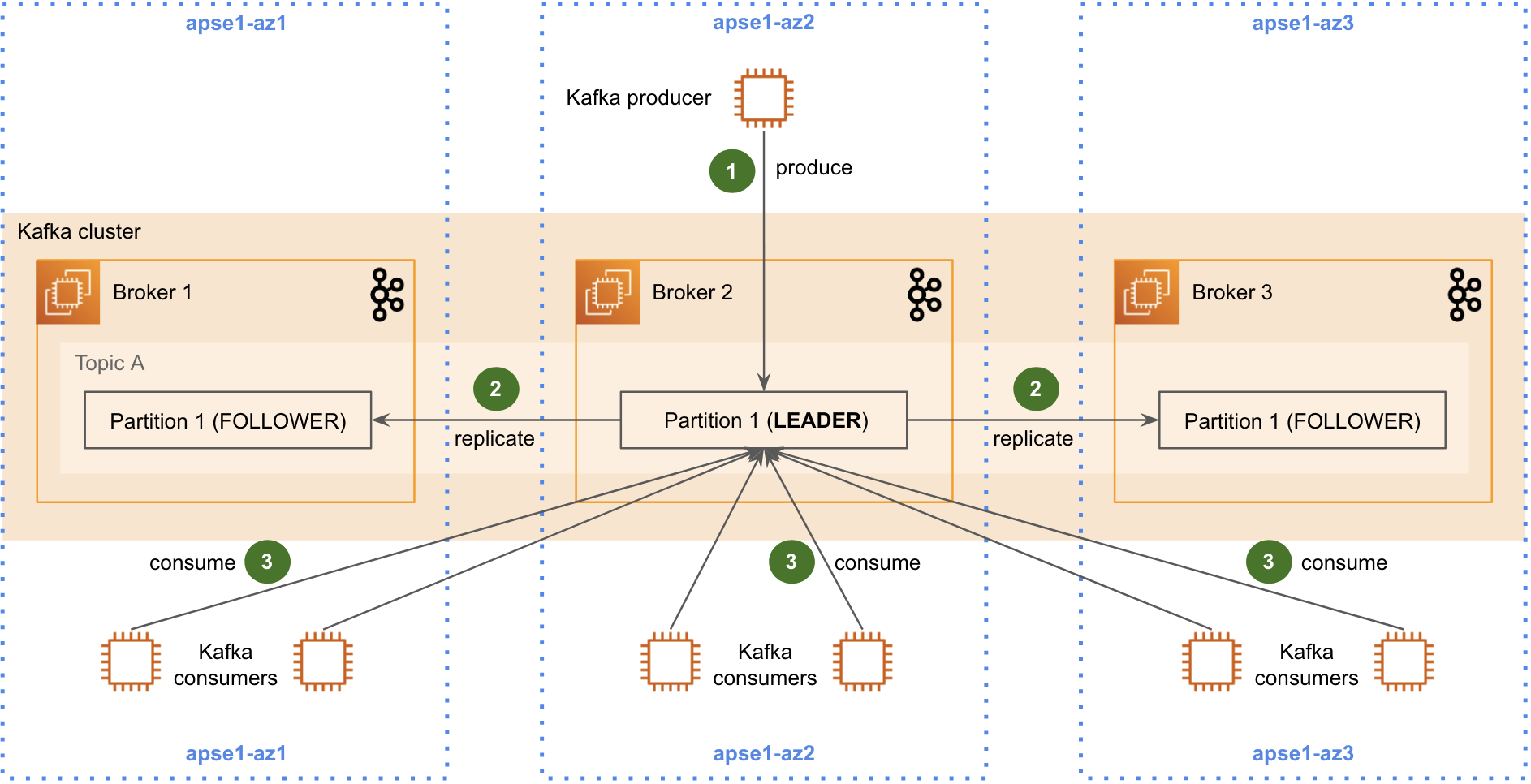
Figure 1 shows the initial design of our data streaming platform. To ensure high availability and resilience, we configured each Kafka partition to have three replicas. We have also set up our Kafka clusters to be rack-aware (i.e. 1 “rack” = 1 AZ) so that all three replicas reside in three different AZs.
The problem with this design is that it generates staggering cross-AZ network traffic. This is because, by default, Kafka clients communicate only with the partition leader, which has a 67% probability of residing in a different AZ.
This is a concern as we are charged for cross-AZ traffic as per AWS’s network traffic pricing model. With this design, our cross-AZ traffic amounted to half of the total cost of our Kafka platform.
The Kafka cross-AZ traffic for this design can be broken down into three components as shown in Figure 1:
- Producing (step 1): Typically, a single service produces data to a given Kafka topic. Cross-AZ traffic occurs when the producer does not reside in the same AZ as the partition leader it is producing data to. This cross-AZ traffic cost is minimal, because the data is transferred to a different AZ at most once (excluding retries).
- Replicating (step 2): The ingested data is replicated from the partition leader to the two partition followers, which reside in two other AZs. The cost of this is also relatively small, because the data is only transferred to a different AZ twice.
- Consuming (step 3): Most of the cross-AZ traffic occurs here because there are many consumers for a single Kafka topic. Similar to the producers, the consumers incur cross-AZ traffic when they do not reside in the same AZ as the partition leader. However, on the consuming side, cross-AZ traffic can occur as many times as there are consumers (on average, two-thirds of the number of consumers). The solution described in this article addresses this particular component of the cross-AZ traffic in the initial design.
Solution
Kafka 2.3 introduced the ability for consumers to fetch from partition replicas. This opens the door to a more cost-efficient design.
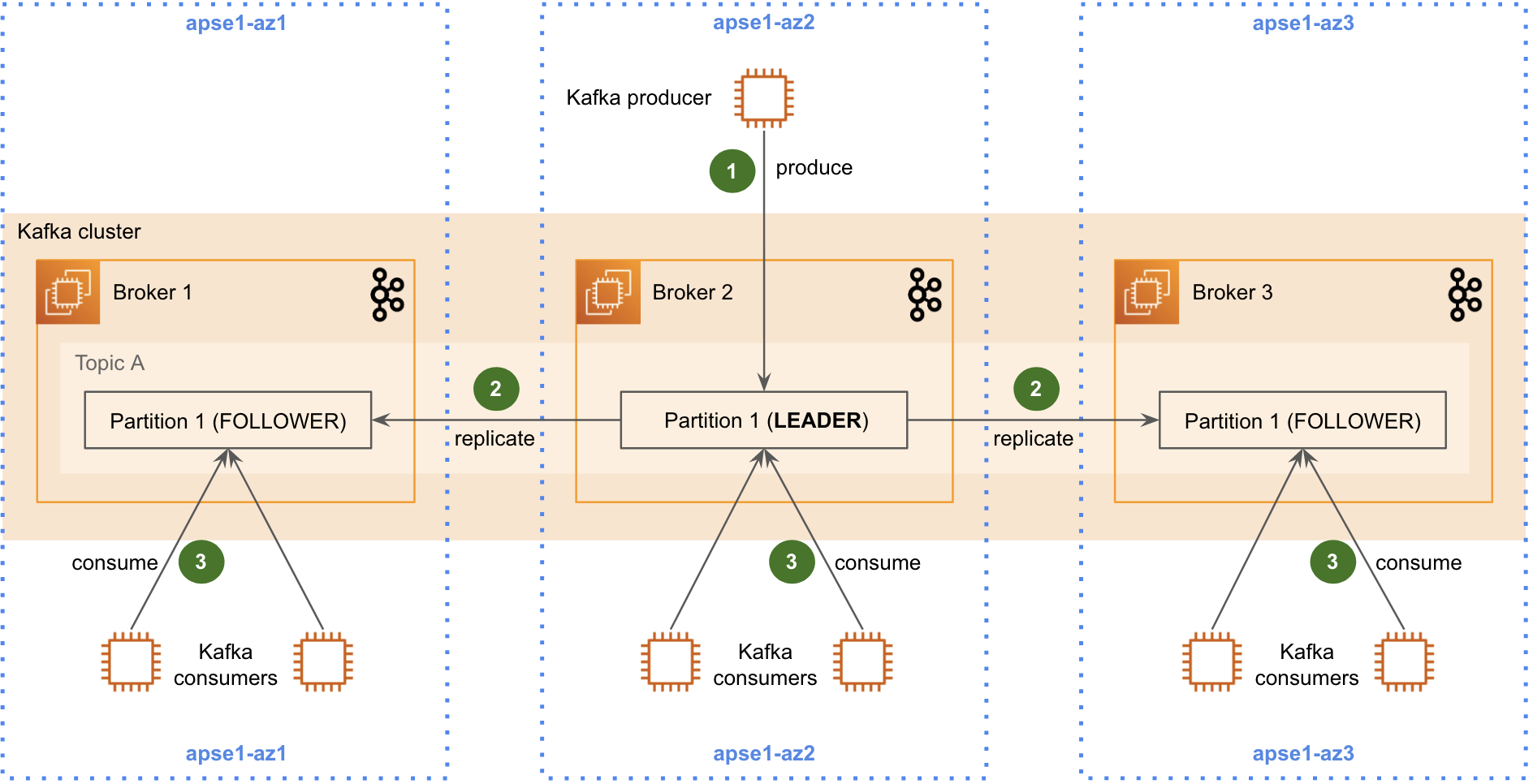
Step 3 of Figure 2 shows how consumers can now consume data from the replica that resides in their own AZ. Implementing this feature requires rack-awareness and extra configurations for both the Kafka brokers and consumers. We will describe this in the following sections.
The Coban journey
Kafka upgrade
Our journey started with the upgrade of our legacy Kafka clusters. We decided to upgrade them directly to version 3.1, in favour of capturing bug fixes and optimisations over version 2.3. This was a safe move as version 3.1 was deemed stable for almost a year and we projected no additional operational cost for this upgrade.
To perform an online upgrade with no disruptions for our users, we broke down the process into three stages.
- Stage 1: Upgrading Zookeeper. All versions of Kafka are tested by the community with a specific version of Zookeeper. To ensure stability, we followed this same process. The upgraded Zookeeper would be backward compatible with the pre-upgrade version of Kafka which was still in use at this early stage of the operation.
- Stage 2: Rolling out the upgrade of Kafka to version 3.1 with an explicit backward-compatible inter-broker protocol version (
inter.broker.protocol.version). During this progressive rollout, the Kafka cluster is temporarily composed of brokers with heterogeneous Kafka versions, but they can communicate with one another because they are explicitly set up to use the same inter-broker protocol version. At this stage, we also upgraded Cruise Control to a compatible version, and we configured Kafka to import the updatedcruise-control-metrics-reporterJAR file on startup. - Stage 3: Upgrading the inter-broker protocol version. This last stage makes all brokers use the most recent version of the inter-broker protocol. During the progressive rollout of this change, brokers with the new protocol version can still communicate with brokers on the old protocol version.
Configuration
Enabling Kafka consumers to fetch from the closest replica requires a configuration change on both Kafka brokers and Kafka consumers. They also need to be aware of their AZ, which is done by leveraging Kafka rack-awareness (1 “rack” = 1 AZ).
Brokers
In our Kafka brokers’ configuration, we already had broker.rack set up to distribute the replicas across different AZs for resiliency. Our Ansible role for Kafka automatically sets it with the AZ ID that is dynamically retrieved from the EC2 instance’s metadata at deployment time.
- name: Get availability zone ID
uri:
url: http://169.254.169.254/latest/meta-data/placement/availability-zone-id
method: GET
return_content: yes
register: ec2_instance_az_id
Note that we use AWS AZ IDs (suffixed az1, az2, az3) instead of the typical AWS AZ names (suffixed 1a, 1b, 1c) because the latter’s mapping is not consistent across AWS accounts.
Also, we added the new replica.selector.class parameter, set with value org.apache.kafka.common.replica.RackAwareReplicaSelector, to enable the new feature on the server side.
Consumers
On the Kafka consumer side, we mostly rely on Coban’s internal Kafka SDK in Golang, which streamlines how service teams across all Grab verticals utilise Coban Kafka clusters. We have updated the SDK to support fetching from the closest replica.
Our users only have to export an environment variable to enable this new feature. The SDK then dynamically retrieves the underlying host’s AZ ID from the host’s metadata on startup, and sets a new client.rack parameter with that information. This is similar to what the Kafka brokers do at deployment time.
We have also implemented the same logic for our non-SDK consumers, namely Flink pipelines and Kafka Connect connectors.
Impact
We rolled out fetching from the closest replica at the turn of the year and the feature has been progressively rolled out on more and more Kafka consumers since then.
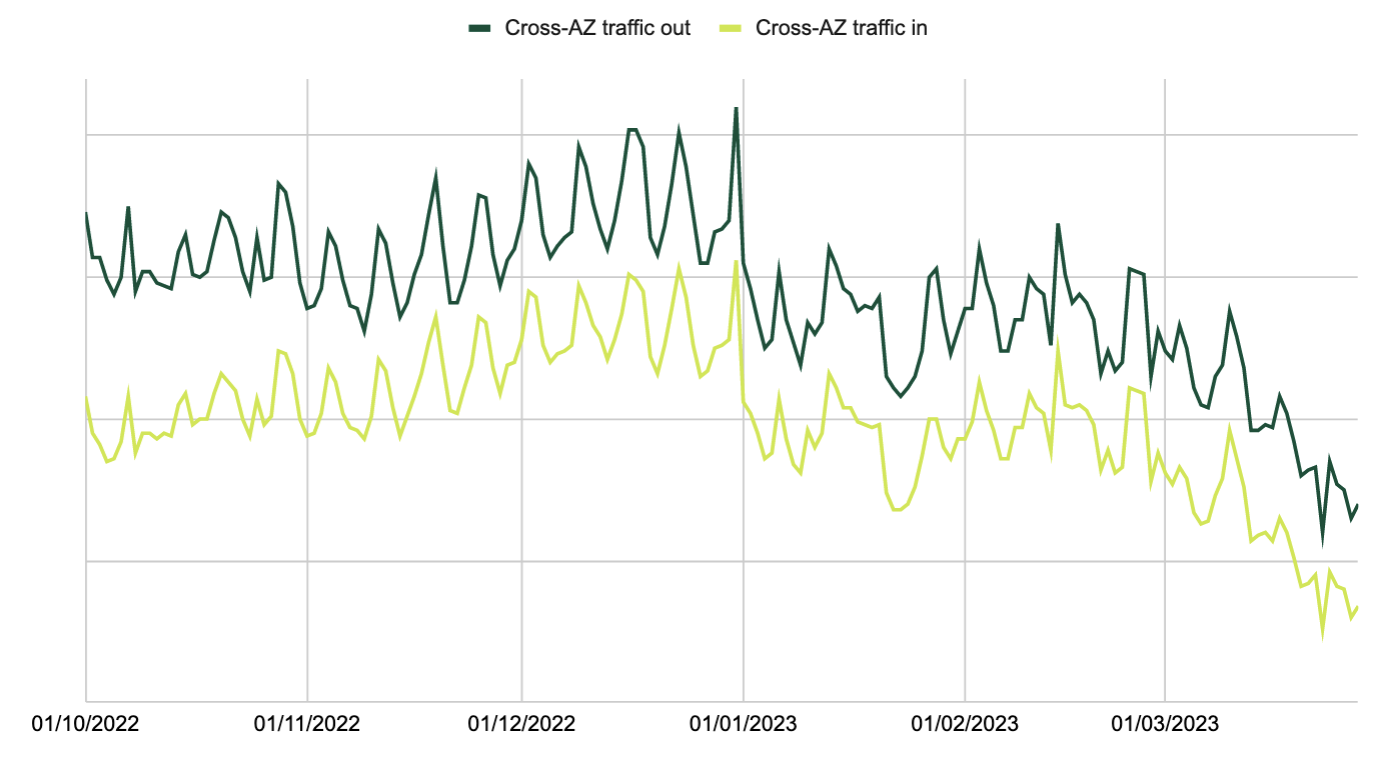
Figure 3 shows the relative impact of this change on our cross-AZ traffic, as reported by AWS Cost Explorer. AWS charges cross-AZ traffic on both ends of the data transfer, thus the two data series. On the Kafka brokers’ side, less cross-AZ traffic is sent out, thereby causing the steep drop in the dark green line. On the Kafka consumers’ side, less cross-AZ traffic is received, causing the steep drop in the light green line. Hence, both ends benefit by fetching from the closest replica.
Throughout the observeration period, we maintained a relatively stable volume of data consumption. However, after three months, we observed a substantial 25% drop in our cross-AZ traffic compared to December’s average. This reduction had a direct impact on our cross-AZ costs as it directly correlates with the cross-AZ traffic volume in a linear manner.
Caveats
Increased end-to-end latency
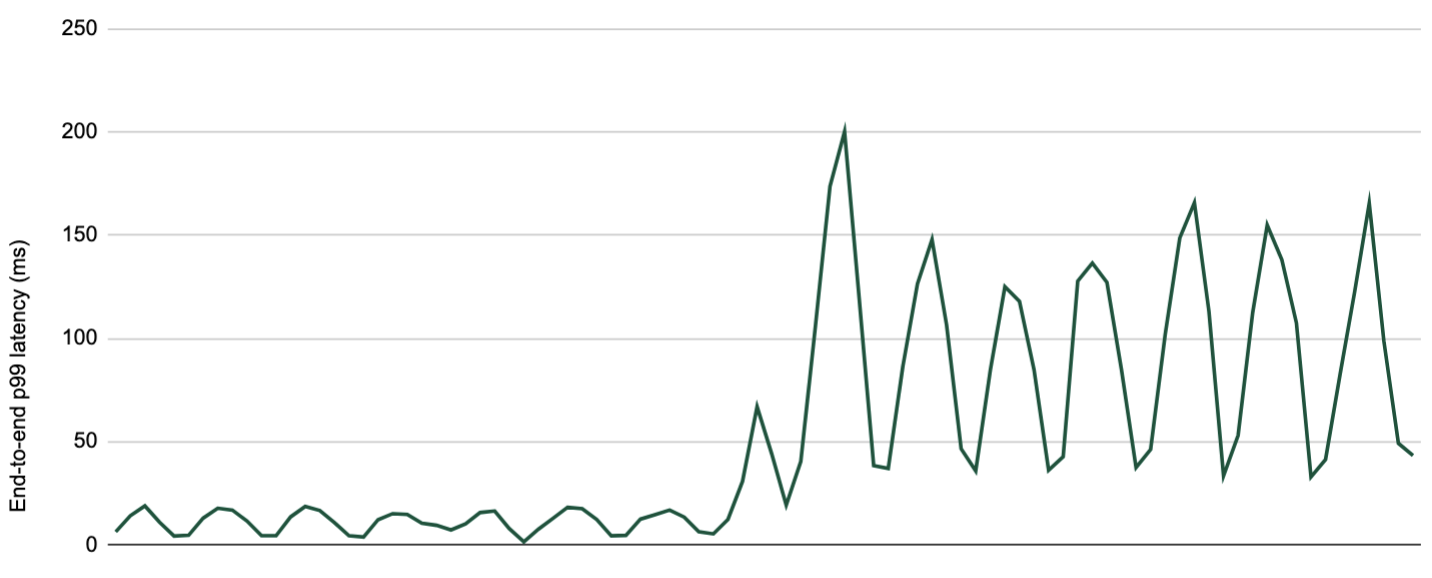
After enabling fetching from the closest replica, we have observed an increase of up to 500ms in end-to-end latency, that comes from the producer to the consumers. Though this is expected by design, it makes this new feature unsuitable for Grab’s most latency-sensitive use cases. For these use cases, we retained the traditional design whereby consumers fetch directly from the partition leaders, even when they reside in different AZs.
Inability to gracefully isolate a broker
We have also verified the behaviour of Kafka clients during a broker rotation; a common maintenance operation for Kafka. One of the early steps of our corresponding runbook is to demote the broker that is to be rotated, so that all of its partition leaders are drained and moved to other brokers.
In the traditional architecture design, Kafka clients only communicate with the partition leaders, so demoting a broker gracefully isolates it from all of the Kafka clients. This ensures that the maintenance is seamless for them. However, by fetching from the closest replica, Kafka consumers still consume from the demoted broker, as it keeps serving partition followers. When the broker effectively goes down for maintenance, those consumers are suddenly disconnected. To work around this, they must handle connection errors properly and implement a retry mechanism.
Potentially skewed load
Another caveat we have observed is that the load on the brokers is directly determined by the location of the consumers. If they are not well balanced across all of the three AZs, then the load on the brokers is similarly skewed. At times, new brokers can be added to support an increasing load on an AZ. However, it is undesirable to remove any brokers from the less loaded AZs as more consumers can suddenly relocate there at any time. Having these additional brokers and underutilisation of existing brokers on other AZs can also impact cost efficiency.
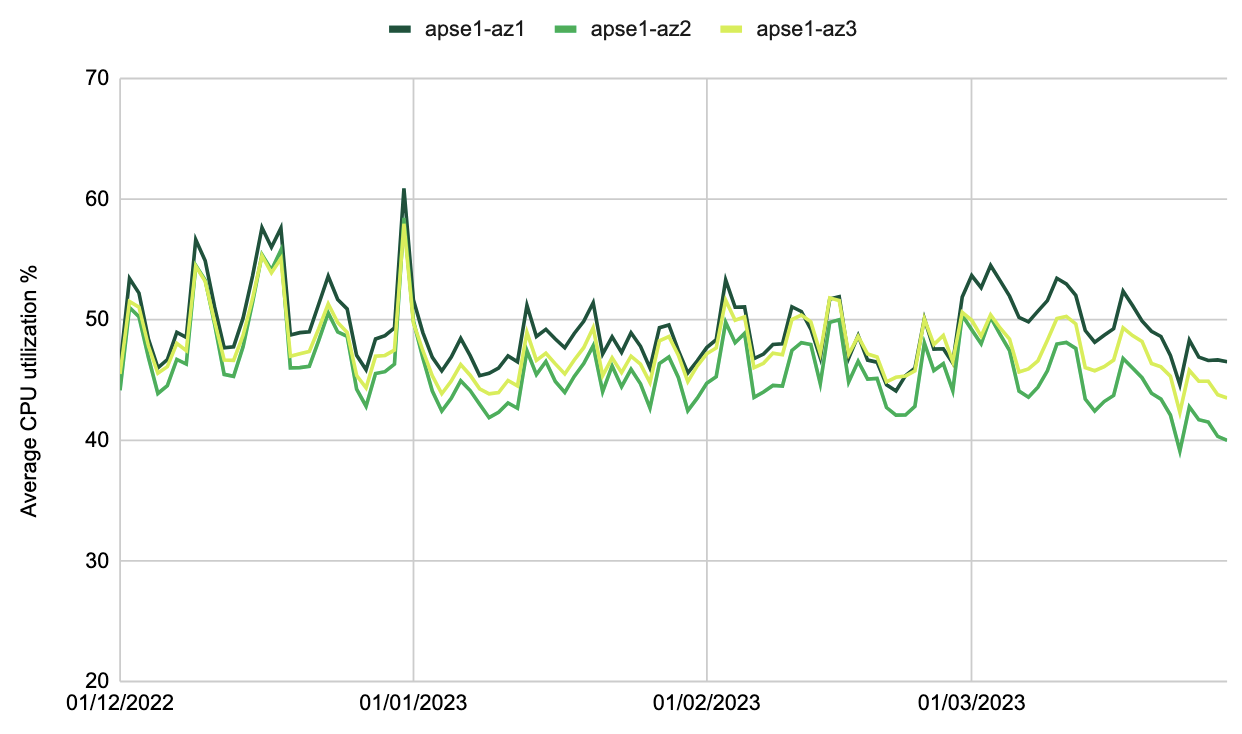
Figure 5 shows the CPU utilisation by AZ for one of our critical Kafka clusters. The skewage is visible after 01/03/2023. To better manage this skewage in load across AZs, we have updated our SDK to expose the AZ as a new metric. This allows us to monitor the skewness of the consumers and take measures proactively, for example, moving some of them to different AZs.
What’s next?
We have implemented the feature to fetch from the closest replica on all our Kafka clusters and all Kafka consumers that we control. This includes internal Coban pipelines as well as the managed pipelines that our users can self-serve as part of our data streaming offering.
We are now evangelising and advocating for more of our users to adopt this feature.
Beyond Coban, other teams at Grab are also working to reduce their cross-AZ traffic, notably, Sentry, the team that is in charge of Grab’s service mesh.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!