
Evolution of Catwalk: Model serving platform at Grab
Introduction
As Southeast Asia’s leading super app, Grab serves millions of users across multiple countries every day. Our services range from ride-hailing and food delivery to digital payments and much more. The backbone of our operations? Machine Learning (ML) models. They power our real-time decision-making capabilities, enabling us to provide a seamless and personalised experience to our users. Whether it’s determining the most efficient route for a ride, suggesting a food outlet based on a user’s preference, or detecting fraudulent transactions, ML models are at the forefront.
However, serving these ML models at Grab’s scale is no small feat. It requires a robust, efficient, and scalable model serving platform, which is where our ML model serving platform, Catwalk, comes in.
Catwalk has evolved over time, adapting to the growing needs of our business and the ever-changing tech landscape. It has been a journey of continuous learning and improvement, with each step bringing new challenges and opportunities.
Evolution of the platform
Phase 0: The need for a model serving platform
Before Catwalk’s debut as our dedicated model serving platform, data scientists across the company employed various ad-hoc approaches to serve ML models. These included:
- Shipping models online using custom solutions.
- Relying on backend engineering teams to deploy and manage trained ML models.
- Embedding ML logic within Go backend services.
These methods, however, led to several challenges, undercovering the need for a unified, company-wide platform for serving machine learning models:
- Operational overhead: Data scientists often lacked the necessary expertise to handle the operational aspects of their models, leading to service outages.
- Resource wastage: There was frequently low resource utilisation (e.g., 1%) for data science services, leading to inefficient use of resources.
- Friction with engineering teams: Differences in release cycles and unclear ownership when code was embedded into backend systems resulted in tension between data scientists and engineers.
- Reinventing the wheel: Multiple teams independently attempted to solve model serving problems, leading to a duplication of effort.
These challenges highlighted the need for a company-wide, centralised platform for serving machine learning models.
Phase 1: No-code, managed platform for TensorFlow Serving models
Our initial foray into model serving was centred around creating a managed platform for deploying TensorFlow Serving models. The process involved data scientists submitting their models to the platform’s engineering admin, who could then deploy the model with an endpoint. Infrastructure and networking were managed using Amazon Elastic Kubernetes Service (EKS) and Helm Charts as illustrated below.
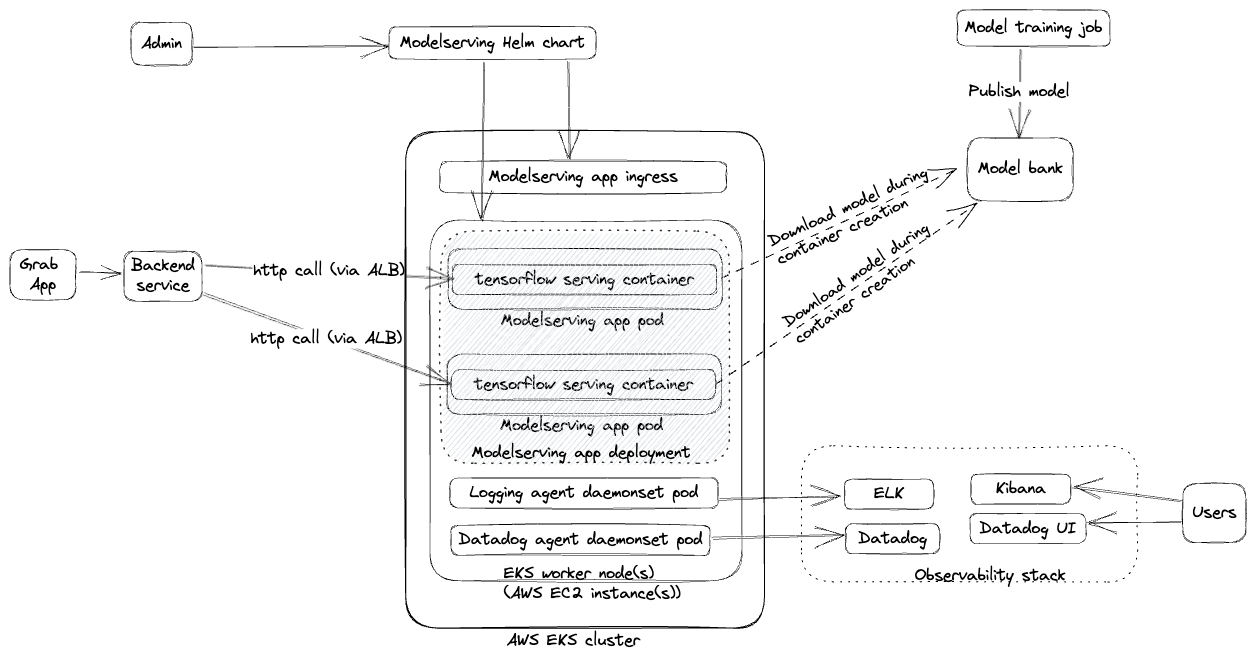
This phase of our platform, which we also detailed in our previous article, was beneficial for some users. However, we quickly encountered scalability challenges:
- Codebase maintenance: Applying changes to every TensorFlow Serving (TFS) version was cumbersome and difficult to maintain.
- Limited scalability: The fully managed nature of the platform made it difficult to scale.
- Admin bottleneck: The engineering admin’s limited bandwidth became a bottleneck for onboarding new models.
- Limited serving types: The platform only supported TensorFlow, limiting its usefulness for data scientists using other frameworks like LightGBM, XGBoost, or PyTorch.
After a year of operation, only eight models were onboarded to the platform, highlighting the need for a more scalable and flexible solution.
Phase 2: From models to model serving applications
To address the limitations of Phase 1, we transitioned from deploying individual models to self-contained model serving applications. This “low-code, self-serving” strategy introduced several new components and changes as illustrated in the points and diagram below:
- Support for multiple serving types: Users gained the ability to deploy models trained with a variety of frameworks like Open Neural Network Exchange (ONNX), PyTorch, and TensorFlow.
- Self-served platform through CI/CD pipelines: Data scientists could self-serve and independently manage their model serving applications through CI/CD pipelines.
- New components: We introduced these new components to support the self-serving approach:
- Catwalk proxy, a managed reverse proxy to various serving types.
- Catwalk transformer, a low-code component to transform input and output data.
- Amphawa, a feature fetching component to augment model inputs.
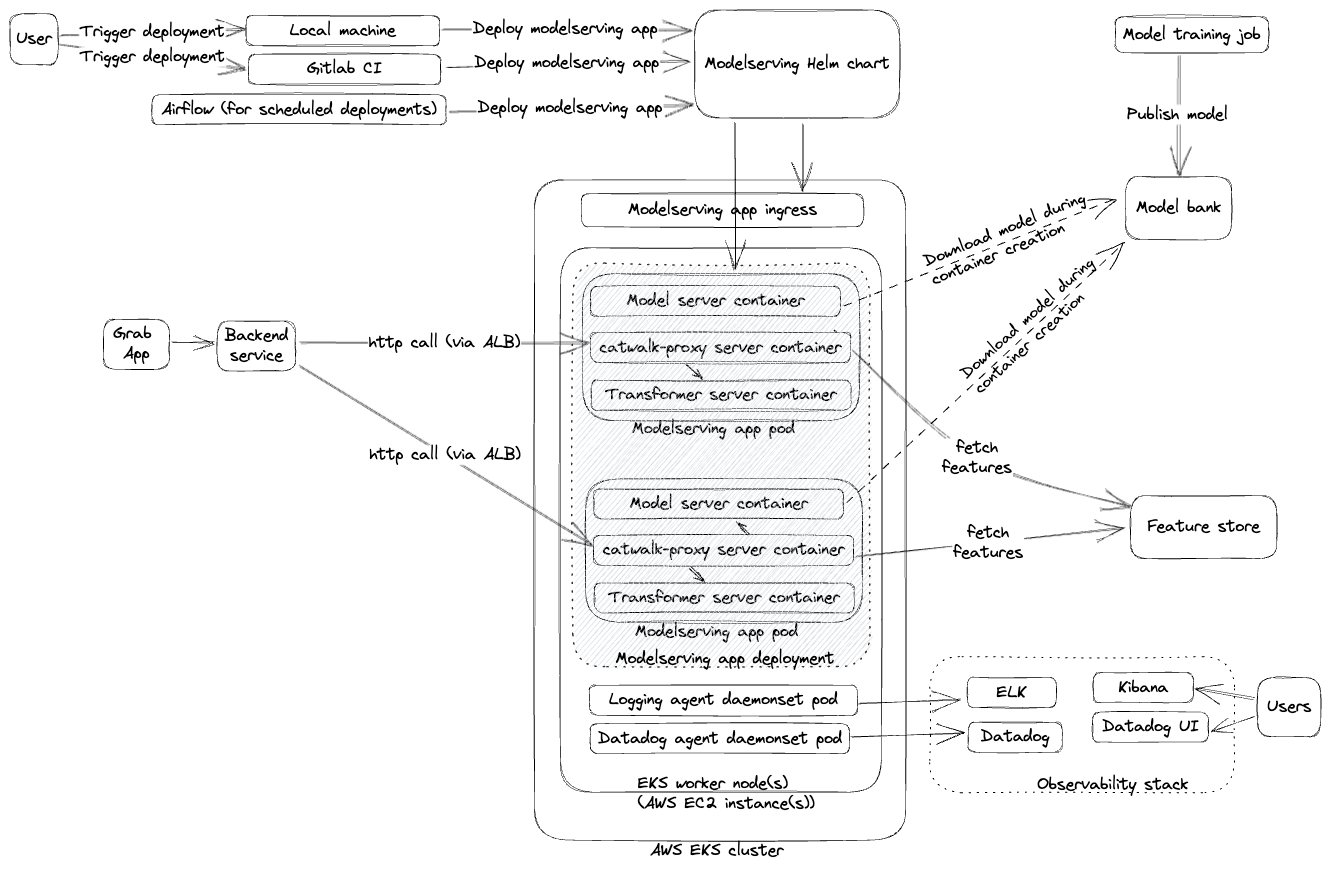
API request flow
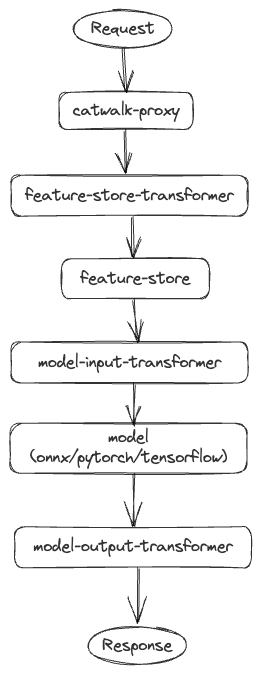
The Catwalk proxy acts as the orchestration layer. Clients send requests to Catwalk proxy then it orchestrates calls to different components like transformers, feature-store, and so on. A typical end to end request flow is illustrated below.
Within a year of implementing these changes, the number of models on the platform increased from 8 to 300, demonstrating the success of this approach. However, new challenges emerged:
- Complexity of maintaining Helm chart: As the platform continued to grow with new components and functionalities, maintaining the Helm chart became increasingly complex. The readability and flow control became more challenging, making the helm chart updating process prone to errors.
- Process-level mistakes: The self-serving approach led to errors such as pushing empty or incompatible models to production, setting too few replicas, or allocating insufficient resources, which resulted in service crashes.
We knew that our work was nowhere near done. We had to keep iterating and explore ways to address the new challenges.
Phase 3: Replacing Helm charts with Kubernetes CRDs
To tackle the deployment challenges and gain more control, we made the significant decision to replace Helm charts with Kubernetes Custom Resource Definitions (CRDs). This required substantial engineering effort, but the outcomes have been rewarding. This transition gave us improved control over deployment pipelines, enabling customisations such as:
- Smart defaults for AutoML
- Blue-green deployments
- Capacity management
- Advanced scaling
- Application set groupings
Below is an example of a simple model serving CRD manifest:
apiVersion: ml.catwalk.kubebuilder.io/v1
kind: ModelServing
spec:
hpa:
desired: 1
max: 1
min: 1
modelMeta:
modelName: "my-model"
modelOwner: john.doe
proxyLayer:
enableLogging: true
logHTTPBody: true
servingLayer:
servingType: "tensorflow-serving"
version: "20"
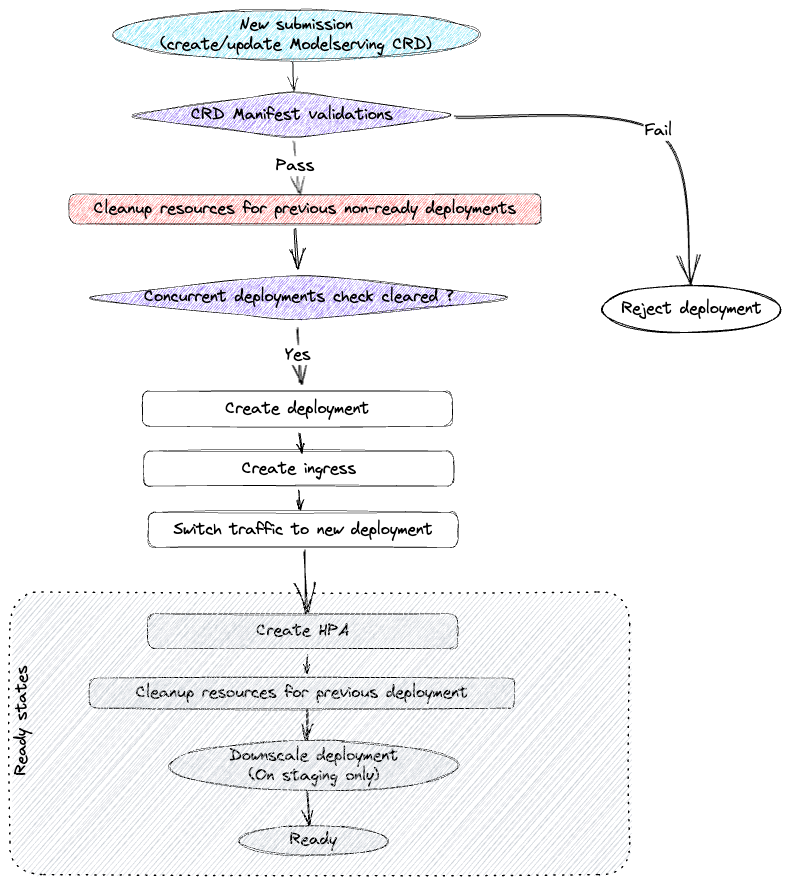
Model serving CRD deployment state machine
Every model serving CRD submission follows a sequence of steps. If there are failures at any step, the controller keeps retrying after small intervals. The major steps on the deployment cycle are described below:
- Validate whether the new CRD specs are acceptable. Along with sanity checks, we also enforce a lot of platform constraints through this step.
- Clean up previous non-ready deployment resources. Sometimes a deployment submission might keep crashing and hence it doesn’t proceed to a ready state. On every submission, it’s important to check and clean up such previous deployments.
- Create resources for the new deployment and ensure that the new deployment is ready.
- Switch traffic from old deployment to the new deployment.
- Clean up resources for old deployment. At this point, traffic is already being served by the new deployment resources. So, we can clean up the old deployment.
Phase 4: Transition to a high-code, self-served, process-managed platform
As the number of model serving applications and use cases multiplied, clients sought greater control over orchestrations between different models, experiment executions, traffic shadowing, and responses archiving. To cater to these needs, we introduced several changes and components with the Catwalk Orchestrator, a high code orchestration solution, leading the pack.
Catwalk orchestrator
The Catwalk Orchestrator is a highly abstracted framework for building ML applications that replaced the catwalk-proxy from previous phases. The key difference is that users can now write their own business/orchestration logic. The orchestrator offers a range of utilities, reducing the need for users to write extensive boilerplate code. Key components of the Catwalk Orchestrator include HTTP server, gRPC server, clients for different model serving flavours (TensorFlow, ONNX, PyTorch, etc), client for fetching features from the feature bank, and utilities for logging, metrics, and data lake ingestion.
The Catwalk Orchestrator is designed to streamline the deployment of machine learning models. Here’s a typical user journey:
- Scaffold a model serving application: Users begin by scaffolding a model serving application using a command-line tool.
- Write business logic: Users then write the business logic for the application.
- Deploy to staging: The application is then deployed to a staging environment for testing.
- Complete load testing: Users test the application in the staging environment and complete load testing to ensure it can handle the expected traffic.
- Deploy to production: Once testing is completed, the application is deployed to the production environment.
Bundled deployments
To support multiple ML models as part of a single model serving application, we introduced the concept of bundled deployments. Multiple Kubernetes deployments are bundled together as a single model serving application deployment, allowing each component (e.g., models, catwalk-orchestrator, etc) to have its own Kubernetes deployment and to scale independently.
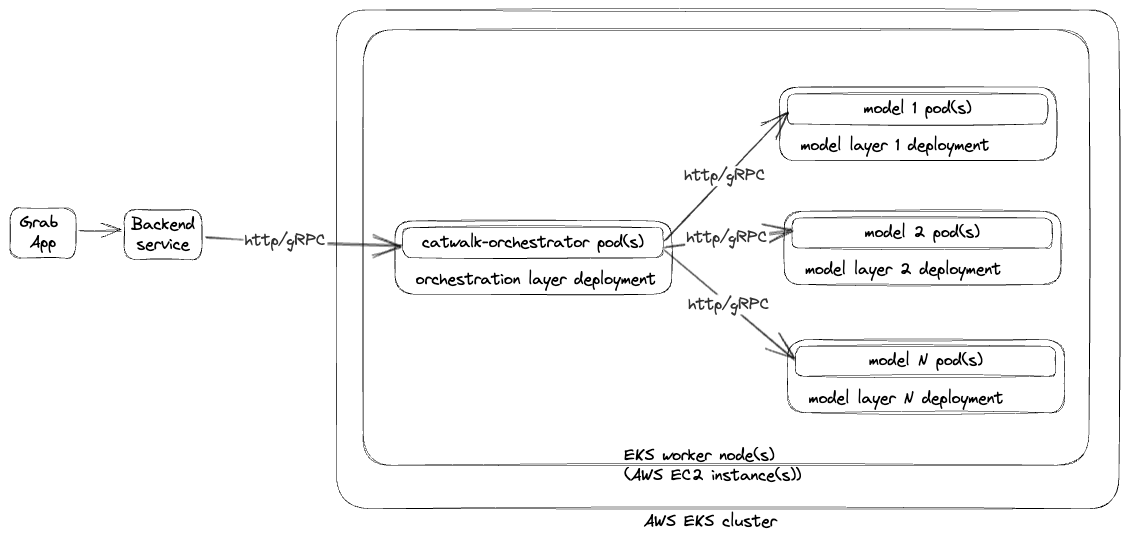
In addition to the major developments, we implemented other changes to enhance our platform’s efficiency. We made load testing mandatory for all ML application updates to ensure robust performance. This testing process was streamlined with a single command that runs the load test in the staging environment, with the results directly shared with the user.
Furthermore, we boosted deployment transparency by sharing deployment details through Slack and Datadog. This empowered users to diagnose issues independently, reducing the dependency on on-call support. This transparency not only improved our issue resolution times but also enhanced user confidence in our platform.
The results of these changes speak for themselves. The Catwalk Orchestrator has evolved into our flagship product. In just two years, we have deployed 200 Catwalk Orchestrators serving approximately 1,400 ML models.
What’s next?
As we continue to innovate and enhance our model serving platform, we are venturing into new territories:
- Catwalk serverless: We aim to further abstract the model serving experience, making it even more user-friendly and efficient.
- Catwalk data serving: We are looking to extend Catwalk’s capabilities to serve data online, providing a more comprehensive service.
- LLM serving: In line with the trend towards generative AI and large language models (LLMs), we’re pivoting Catwalk to support these developments, ensuring we stay at the forefront of the AI and machine learning field.
Stay tuned as we continue to advance our technology and bring these exciting developments to life.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!