
Enhancing Flink deployment with shadow testing
Introduction
Ensuring the reliability of Apache Flink deployments in Grab is crucial for the availability of our business-critical, real-time applications. While all applications are tested in a staging environment before getting promoted to the production environment, there is still a class of issues that can only surface when deploying in the production environment, e.g.:
- The new version of the application is unable to cope with the volume or the nature of production traffic.
- The new version of the application is unable to resume from a production checkpoint or savepoint taken by the previous version of the application.
- Certain environment-specific dependencies or configurations are malfunctioning or misconfigured.
When an application faces such issues upon deployment in production, our in-house deployment system automatically rolls it back after 10 minutes of observation, leading to a downtime of the application for about the same duration.
In this article, we will describe how Grab’s data streaming team (Coban) has enriched the traditional deployment pipeline for Flink applications with a Shadow Testing stage that eliminates this downtime during deployment failures, enhancing the availability of our Flink applications during this critical moment of their lifecycle.
Shadow Testing is a testing technique whereby a new version of an application (Shadow) is deployed in parallel with the current version of the application (Main), but without impacting it. It involves replicating production data to the new version of the application and comparing its behavior with the current version of the application to identify potential issues and regressions.
Architecture overview
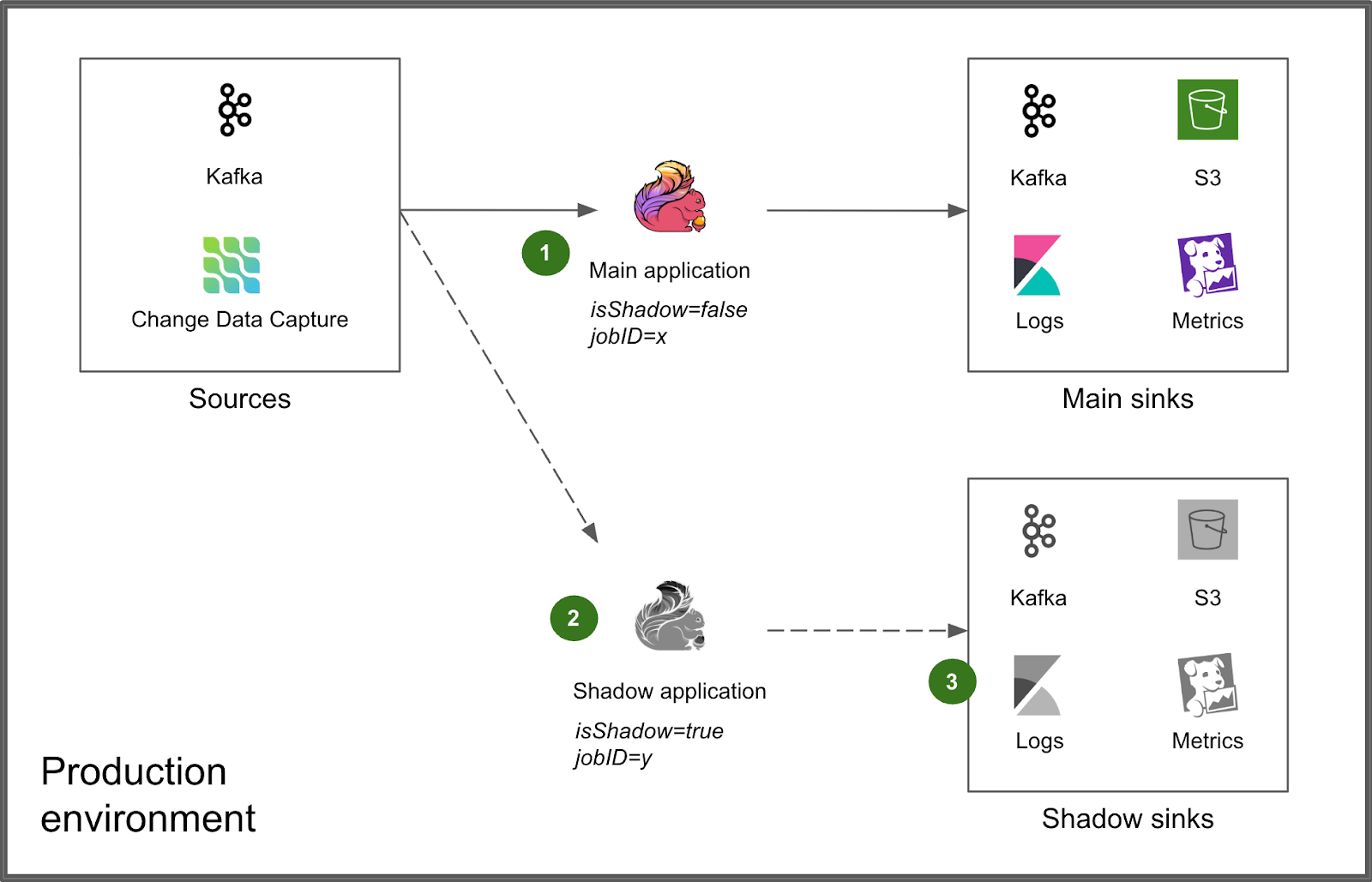
We integrated Shadow Testing directly into the production environment, alongside the Main application (1). The Shadow application is deployed next to it via the same deployment process (2). An environment variable isShadow=true as well as a distinct jobID are injected for runtime differentiation, enabling the Shadow application to produce its results to distinct, isolated sinks that do not interfere with those of the Main application (3).
Deployment flow
Shadow Testing is embedded within our normal Flink deployment pipeline to make it a seamless experience for the users of our platform.
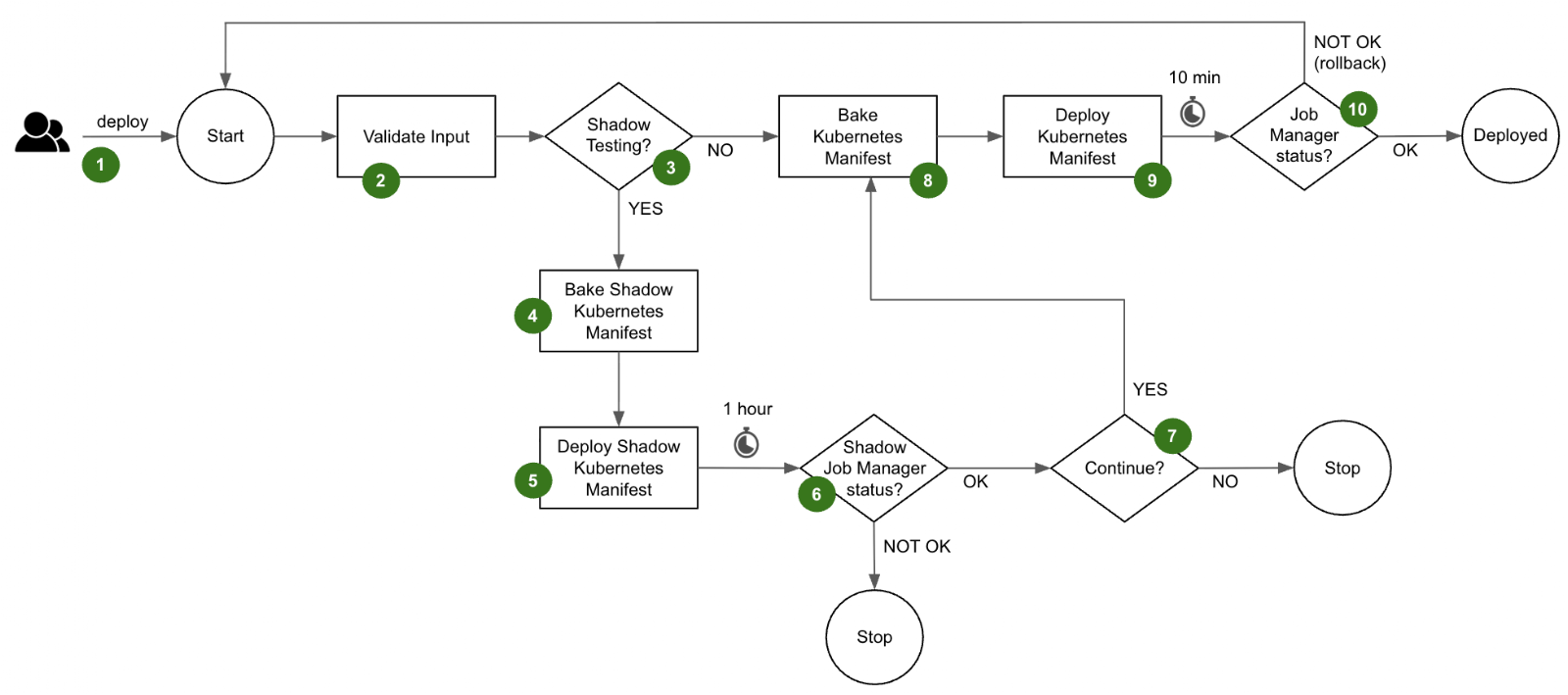
The deployment flow is as follows.
- A user triggers a deployment of their Flink application in Grab’s in-house deployment tool. At this step, they decide whether they want to enable Shadow Testing for this particular deployment.
- The deployment pipeline validates the input parameters provided by the user.
- If the user has not opted for Shadow Testing, the deployment flow directly jumps to step 8 and deploys the latest version to the Main application. However, if the user has enabled Shadow Testing, the deployment flow first goes through the Shadow Testing stages described in steps 4 to 7.
- The Shadow Kubernetes manifest is baked with its set of distinctive parameters:
- The application name is prefixed with shadow- which propagates to all the Kubernetes objects that are part of the Shadow application
- An environment variable
isShadowis injected and set to true. It instructs the Shadow application to produce its results to the shadow sinks. - A distinct Job ID is attributed
- The target Kubernetes namespace is overridden with a shadow namespace
- The Shadow application is deployed into the shadow Kubernetes namespace.
- The Shadow application runs for a configured period of 1 hour by default to reach a steady state. The status of the job manager is monitored to determine the success of the Shadow Testing. If the Shadow application is stable, the Shadow Testing is considered successful.
- The user is prompted to continue with the deployment of the Main application.
- The Kubernetes manifest of the Main application is baked with its standard parameters and the environment variable
isShadowis set to false. - The Main application is deployed in its standard Kubernetes namespace.
- After 10 minutes of observation, the deployment pipeline determines if the Main application is healthy by querying the status of its job manager. If it is healthy, the Main application is considered successfully deployed. Otherwise, the deployment pipeline automatically triggers a rollback to the previous version.
During the deployment, the user can leverage our standard observability stack to monitor the behavior of the Shadow application. For example, in the case of an Apache Kafka sink, they can compare the number of messages produced by the Main and Shadow applications.
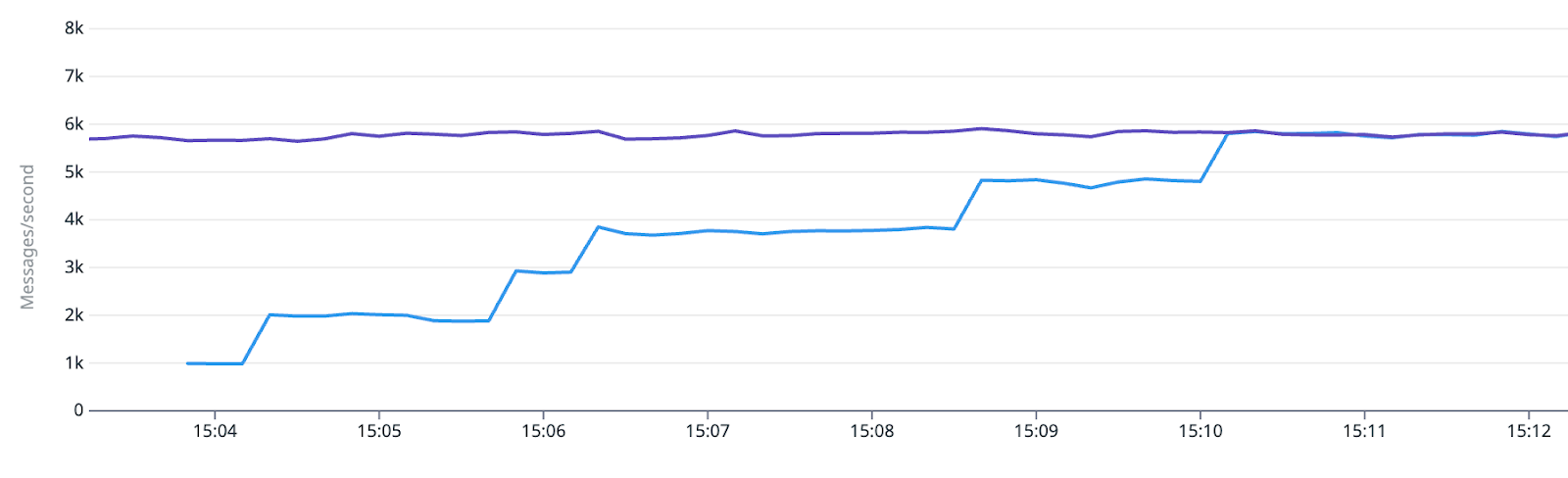
Besides, our standard Datadog dashboard that comes with each application can conveniently be toggled to view the metrics of the respective Shadow application.
Connector implementation
Our standard sink and source connectors, provided by our platform, ensure the absence of interference with the Main application during Shadow Testing. For example, Kafka source connectors use distinct consumer group IDs, while the various sink connectors direct the data to dedicated shadow sinks.
The Flink application evaluates the isShadow environment variable to set up the connectors at runtime.
if (isShadow){
// Shadow Testing operation
}
else {
// Normal operation
}
The following table shows how some typical connectors are dynamically configured if isShadow=true:
| Type | Connector | Dynamic configuration |
|---|---|---|
| Source | Kafka | The consumer group ID for the Shadow application is suffixed with -shadow. This is crucial so as to consume a full copy of the data stream without interfering with the Main application. Main application: consumerGroup = <application_name> Shadow application: consumerGroup = <application_name>-shadow |
| Source | Change Data Capture | The Server ID range of Debezium is shifted to the next non-overlapping range of the same size. This enables the Shadow application to get a full copy of the database binlog stream without interfering with the Main application. Note that the misleading Server ID naming is because Debezium acts as a pseudo-replica of the database server. Main application: serverId = 1001-2000 Shadow application: serverId = 2001 - 3000 |
| Sink | Kafka | The cluster endpoint is replaced with that of a Kafka cluster dedicated to Shadow Testing, set up with auto.create.topics.enable=true and 8h retention. Main application: brokers = <flink-kafka>:9092 Shadow application: brokers = <flink-kafka-shadow>:9092 |
| Sink | S3 | The S3 bucket name is replaced with that of a bucket dedicated to Shadow Testing, set up with a 7-day retention lifecycle policy. Main application: s3://<flink-s3>/<application_name> Shadow application: s3://<flink-s3-shadow>/<application_name> |
| Sink | Metrics | The StatsD prefix configuration is overridden. A shadow. prefix is added. Main application: flink.<application_name>.<metric_name>Shadow application: shadow.flink.<application_name>.<metric_name> |
| Sink | Logs | The Shadow Kubernetes manifest prefixes the Shadow application name with shadow-. The resulting name becomes available as a field in Kibana, enabling discriminated filtering. This tweak is done at the Kubernetes manifest level, not at the Flink application level. Main application: app_name = <application_name> Shadow application: app_name = shadow-<application_name> |
Conclusion
Our Shadow Testing framework represents a meaningful step forward in enhancing the reliability of our Flink applications during deployment. By leveraging and enriching the existing components of our platform, we have created a robust system that enables our users to confidently increase their Deployment Frequency and reduce their Change Failure Rate.
What’s next
To drive wider adoption, we intend to support more source and sink connectors. By expanding the range of supported connectors, we could empower teams to leverage Shadow Testing across a broader spectrum of applications.
For connectors that are less frequently used, we consider implementing a no-op approach combined with metrics collection to expose a minimal set of actionable data points.
We will remain focused on making Shadow Testing accessible, scalable, and adaptable to various applications. Stay tuned as we continue to push the boundaries of innovation and deliver solutions that enhance reliability and efficiency across our systems.
Join us
Grab is Southeast Asia’s leading superapp, serving over 900 cities across eight countries (Cambodia, Indonesia, Malaysia, Myanmar, the Philippines, Singapore, Thailand, and Vietnam). Through a single platform, millions of users access mobility, delivery, and digital financial services, including ride-hailing, food delivery, payments, lending, and digital banking via GXS Bank and GXBank. Founded in 2012, Grab’s mission is to drive Southeast Asia forward by creating economic empowerment for everyone while delivering sustainable financial performance and positive social impact.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!