-
 Engineering · Data
Engineering · DataThe Hugo evolution: Engineering Grab's unified, one-click data ingestion platform with Apache Flink
At Grab, we're transforming data ingestion and processing with Hugo, our self-service data platform. Now integrated with Apache Flink, Hugo empowers teams to build real-time data pipelines effortlessly. Discover how we've streamlined complex processes into a single, one-click experience that boosts productivity and enables rapid insights. Dive into our blog to explore this game-changing evolution! -
 Engineering · Data
Engineering · DataEnhancing Flink deployment with shadow testing
Discover how Grab's data streaming team has revolutionized Apache Flink deployments with Shadow Testing, ensuring seamless reliability for real-time applications. By deploying new versions alongside existing ones without disruption, we eliminate downtime and enhance application availability. Dive into our article to explore this innovative approach and how it boosts deployment confidence and efficiency. -
 Engineering · Data
Engineering · DataA Decade of Defense: Celebrating Grab's 10th Year Bug Bounty Program
Discover how Grab has championed cybersecurity for a decade with its Bug Bounty Program. This article delves into the milestones, insights, and the collaborative efforts that have fortified Grab's defenses, ensuring a secure and reliable platform for millions. -
 Engineering · Data
Engineering · DataReal-time data quality monitoring: Kafka stream contracts with syntactic and semantic test
Discover how Grab's Coban Platform revolutionizes real-time data quality monitoring for Kafka streams. Learn how syntactic and semantic tests empower stream users to ensure reliable data, prevent cascading errors, and accelerate AI-driven innovation. -
 Engineering · Data
Engineering · DataSpellVault’s evolution: Beyond LLM apps, towards the agentic future
Discover SpellVault’s evolution from its early RAG-based foundations and plugin ecosystem to its transformation into a tool-driven, agentic framework that empowers users to build AI agents that are powerful, flexible, and future-ready. -
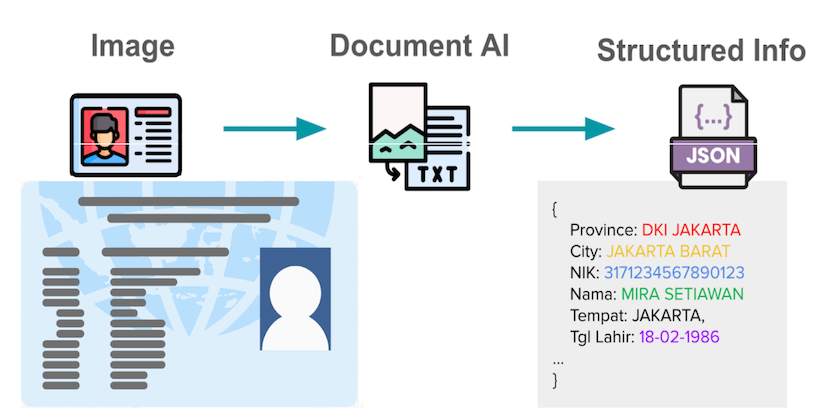 Engineering · Data
Engineering · DataHow we built a custom vision LLM to improve document processing at Grab
e-KYC faces challenges with unstandardized document formats and local SEA languages. Existing LLMs lack sufficient SEA language support. We trained a Vision LLM from scratch, modifying open-source models to be 50% faster while maintaining accuracy. These models now serve live production traffic across Grab's ecosystem for merchant, driver, and user onboarding. -
 Engineering · Data
Engineering · DataMachine-learning predictive autoscaling for Flink
Explore how Grab uses machine learning to perform predictive scaling on our data processing workloads. -
 Engineering · Data
Engineering · DataModernising Grab’s model serving platform with NVIDIA Triton Inference Server
Dive into Grab’s engineering journey to optimise a core ML model. Learn how we built the Triton Server Manager and used Triton Inference Server (TIS) to achieve a 50% reduction in tail latency and seamlessly migrate over 50% of online deployments.