
Graph service platform
Introduction
In earlier articles of this series, we covered the importance of graph networks, graph concepts, how graph visualisation makes fraud investigations easier and more effective, and how graphs for fraud detection work. In this article, we elaborate on the need for a graph service platform and how it works.
In the present age, data linkages can generate significant business value. Whether we want to learn about the relationships between users in online social networks, between users and products in e-commerce, or understand credit relationships in financial networks, the capability to understand and analyse large amounts of highly interrelated data is becoming more important to businesses.
As the amount of consumer data grows, the GrabDefence team must continuously enhance fraud detection on mobile devices to proactively identify the presence of fraudulent or malicious users. Even simple financial transactions between users must be monitored for transaction loops and money laundering. To preemptively detect such scenarios, we need a graph service platform to help discover data linkages.
Background
As mentioned in an earlier article, a graph is a model representation of the association of entities and holds knowledge in a structured way by marginalising entities and relationships. In other words, graphs hold a natural interpretability of linked data and graph technology plays an important role. Since the early days, large tech companies started to create their own graph technology infrastructure, which is used for things like social relationship mining, web search, and sorting and recommendation systems with great commercial success.
As graph technology was developed, the amount of data gathered from graphs started to grow as well, leading to a need for graph databases. Graph databases1 are used to store, manipulate, and access graph data on the basis of graph models. It is similar to the relational database with the feature of Online Transactional Processing (OLTP), which supports transactions, persistence, and other features.
A key concept of graphs is the edge or relationship between entities. The graph relates the data items in the store to a collection of nodes and edges, the edges representing the relationships between the nodes. These relationships allow data in the store to be linked directly and retrieved with one operation.
With graph databases, relationships between data can be queried fast as they are perpetually stored in the database. Additionally, relationships can be intuitively visualised using graph databases, making them useful for heavily interconnected data. To have real-time graph search capabilities, we must leverage the graph service platform and graph databases.
Architecture details
Graph services with graph databases are Platforms as a Service (PaaS) that encapsulate the underlying implementation of graph technology and support easier discovery of data association relationships with graph technologies.
They also provide universal graph operation APIs and service management for users. This means that users do not need to build graph runtime environments independently and can explore the value of data with graph service directly.
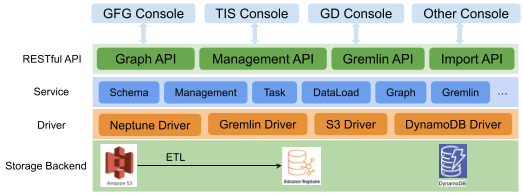
As shown in Fig. 1, the system can be divided into four layers:
- Storage backend - Different forms of data (for example, CSV files) are stored in Amazon S3, graph data stores in Neptune and meta configuration stores in DynamoDB.
- Driver - Contains drivers such as Gremlin, Neptune, S3, and DynamoDB.
- Service - Manages clusters, instances, databases etc, provides management API, includes schema and data load management, graph operation logic, and other graph algorithms.
- RESTful APIs - Currently supports the standard and uniform formats provided by the system, the Management API, Search API for OLTP, and Analysis API for online analytical processing (OLAP).
How it works
Graph flow
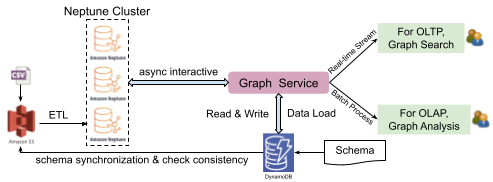
CSV files stored in Amazon S3 are processed by extract, transform, and load (ETL) tools to generate graph data. This data is then managed by an Amazon Neptune DB cluster, which can only be accessed by users through graph service. Graph service converts user requests into asynchronous interactions with Neptune Cluster, which returns the results to users.
When users launch data load tasks, graph service synchronises the entity and attribute information with the CSV file in S3, and the schema stored in DynamoDB. The data is only imported into Neptune if there are no inconsistencies.
The most important component in the system is the graph service, which provides RESTful APIs for two scenarios: graph search for real-time streams and graph analysis for batch processing. At the same time, the graph service manages clusters, databases, instances, users, tasks, and meta configurations stored in DynamoDB, which implements features of service monitor and data loading offline or stream ingress online.
Use case in fraud detection
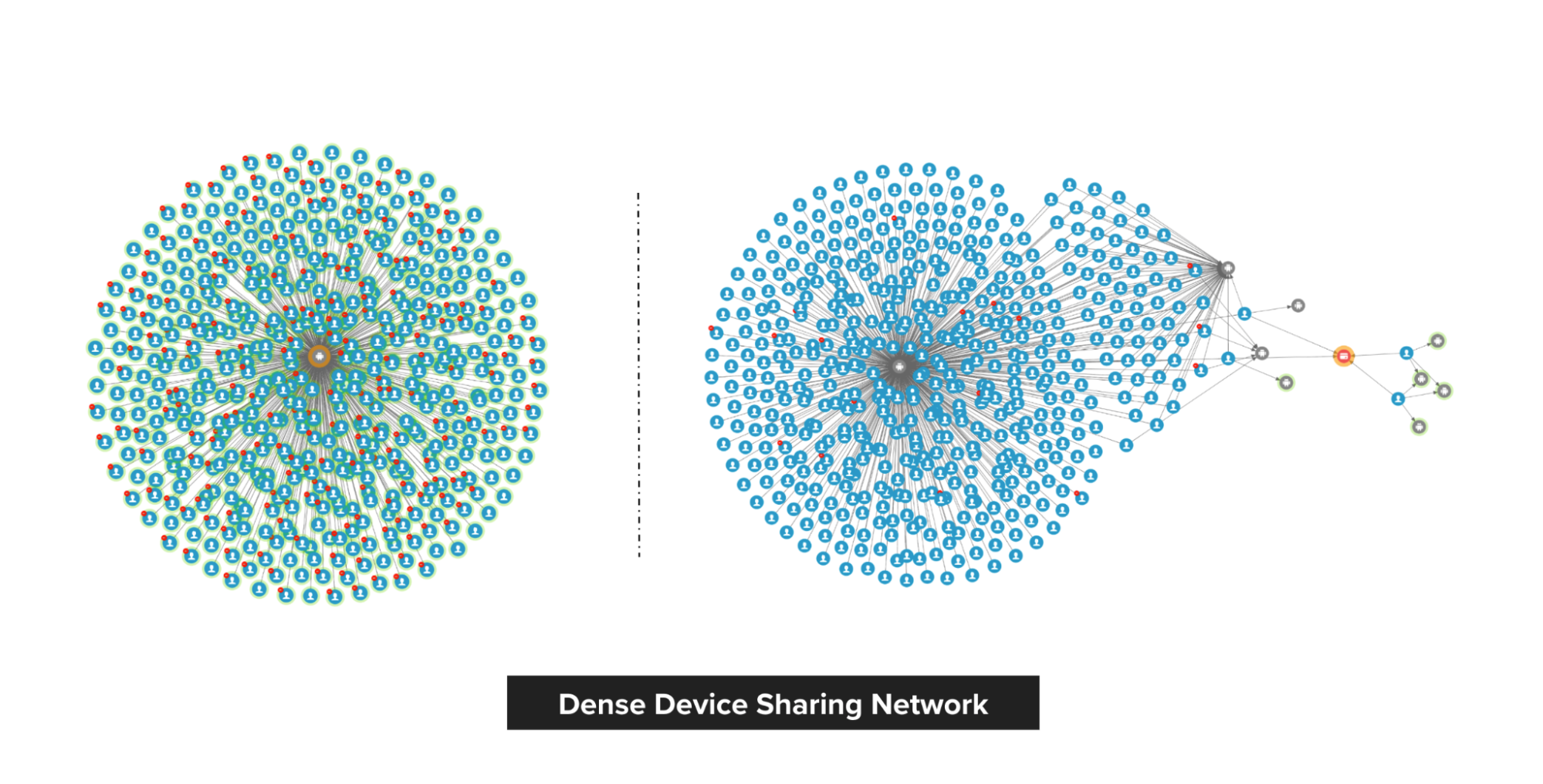
In Grab’s mobility business, we have come across situations where multiple accounts use shared physical devices to maximise their earning potential. With the graph capabilities provided by the graph service platform, we can clearly see the connections between multiple accounts and shared devices.
Historical device and account data are stored in the graph service platform via offline data loading or online stream injection. If the device and account data exists in the graph service platform, we can find the adjacent account IDs or the shared device IDs by using the device ID or account ID respectively specified in the user request.
In our experience, fraudsters tend to share physical resources to maximise their revenue. The following image shows a device that is shared by many users. With our Graph Visualisation platform based on graph service, you can see exactly what this pattern looks like.
Data injection
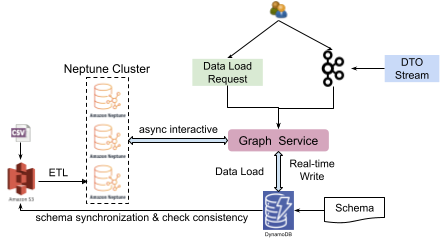
Graph service also supports data injection features, including data load by request (task with a type of data load) and real-time stream write by Kafka.
When connected to GrabDefence’s infrastructure, Confluent with Kafka is used as the streaming engine. The purpose of using Kafka as a streaming write engine is two-fold: to provide primary user authentication and to relieve the pressure on Neptune.
Impact
Graph service supports data management of Labelled Property Graphs and provides the capability to add, delete, update, and get vertices, edges, and properties for some graph models. Graph traversal and searching relationships with RESTful APIs are also more convenient with graph service.
Businesses usually do not need to focus on the underlying data storage, just designing graph schemas for model definition according to their needs. With the graph service platform, platforms or systems can be built for personalised search, intelligent Q&A, financial fraud, etc.
For big organisations, extensive graph algorithms provide the power to mine various entity connectivity relationships in massive amounts of data. The growth and expansion of new businesses is driven by discovering the value of data.
What’s next?
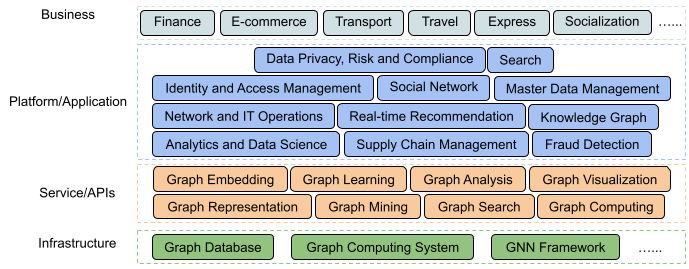
We are building an integrated graph ecosystem inside and outside Grab. The infrastructure and service, or APIs are key components in graph-centric ecosystems; they provide graph arithmetic and basic capabilities of graphs in relation to search, computing, analysis etc. Besides that, we will also consider incorporating applications such as risk prediction and fraud detection in order to serve our current business needs.
Speak to us
GrabDefence is a proprietary fraud prevention platform built by Grab, Southeast Asia’s leading superapp. Since 2019, the GrabDefence team has shared its fraud management capabilities and platform with enterprises and startups to leverage Grab’s advanced AI/ML models, hyper local insights and patented device intelligence technologies.
To learn more about GrabDefence or to speak to our fraud management experts, contact us at gd.contact@grabtaxi.com.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!