How We Scaled Our Cache and Got a Good Night's Sleep

Caching is arguably the most important and widely used technique in computer industry, from CPU to Facebook live videos, cache is everywhere.
Problem
Our CDS (Common Data Service) relies heavily on caching too. It helps us reduce database load and generate faster responses to our consumers. But as our business grows, the load on our cache system grows too and it might eventually become a bottleneck.
To solve this potential problem, we need to be able to horizontally scale our cache system. Why horizontally?
- We want to have more caching space in order to accommodate more caches in future.
- The caching system we are using is single-threaded (Redis provided by ElasticCache) which would only use one core even in a multicore system. Vertically scaling by adding more cores to one machine simply doesn’t help.
The options available to us are as follow:
- Use Redis master-slave model and make all writes go through master, all reads through multiple slaves.
- Use Twemproxy as a middle layer of distributing caches to multiple backend ElasticCache machines.
- Custom sharding the cache keys across multiple ElasticCache machines.
There are a few known drawbacks of the first approach, especially when there is some trickiness that comes with replication and master fail-over scenarios, as described in this post.
Moreover, the first approach doesn’t solve our first problem - to have more memory space in order to accommodate more caches. Naturally, we gave it up.
The second approach of using Twemproxy isn’t a good solution either. It has been proven before that under a heavy load, Twemproxy will become the bottleneck as all the cache I/O will be going through there.
Design
Finally, we decided to implement a custom sharding mechanism for our caches. Each CDS instance will hash each of the keys it needs to read or write, and based on the hashed value it will figure out which shard the key is possibly in and then access that shard for the interested key. This approach is essentially what Twemproxy does to CDS instances, thus distributing the load.
Twemproxy
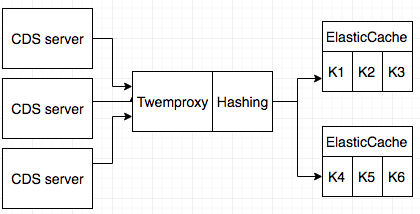
CDS Hashing
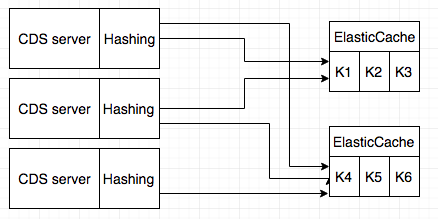
We wrote an internal Golang package to implement consistent hashing already and we have a fairly clean abstraction, so the work becomes pretty easy - wrap the components!
Implementation
Coming to the topic of implementation, the first thing we considered is that even though the logic of cache read / write is different in this sharding model, it’s still a cache from our server’s point of view. So we added an interface called ShardedCache which is composited with the original Cache interface (so it has the same exposed methods with Cache) that allows us to easily swap implementations where cache is used.
The second thing we made sure of is that ShardedCache is only a thin wrapper on top of Cache. The core caching I/O features still happens in Cache implementation and what ShardedCache provides is hashing capability so it will be much easier for these 2 implementations evolve in parallel with minimum impact on each other.
Furthermore, although we are using ketama as default hashing method, users can still inject their own hashing functions if needed. This facilitates tests and future extensions.
Deployment
Shipping a new software to production always comes with risk. Especially with such a critical system as caching.
When switching to a new cache mechanism, some cache misses are inevitable, so we chose to deploy during the relatively peaceful hours at night, so that we can have some cache warm up time before the morning peak.
Also, we have a cron job to populate caches for some heavy requests every 12 hours, so we need to make the cron job double write cache to the new systems beforehand in order to prevent high volume DB reads and possible data inconsistencies.
Therefore, the steps are:
- Configure cron job double writing to the new cache system – Need to deploy CDS because cron job is running within CDS.
- Verify the populated caches in new system and configure CDS to read from there – Need to deploy CDS again for the configuration changes.
This process took 2 days to finish, a little tedious but worth doing for a max degree of reliability.
Outcome
With everything is in place, we deployed it and here’s what happened:
As you can see from the graphs below, although we are experiencing more load, after a period of warmup. The sharded caching solution offers much better P99 latency comparing to the old single system.
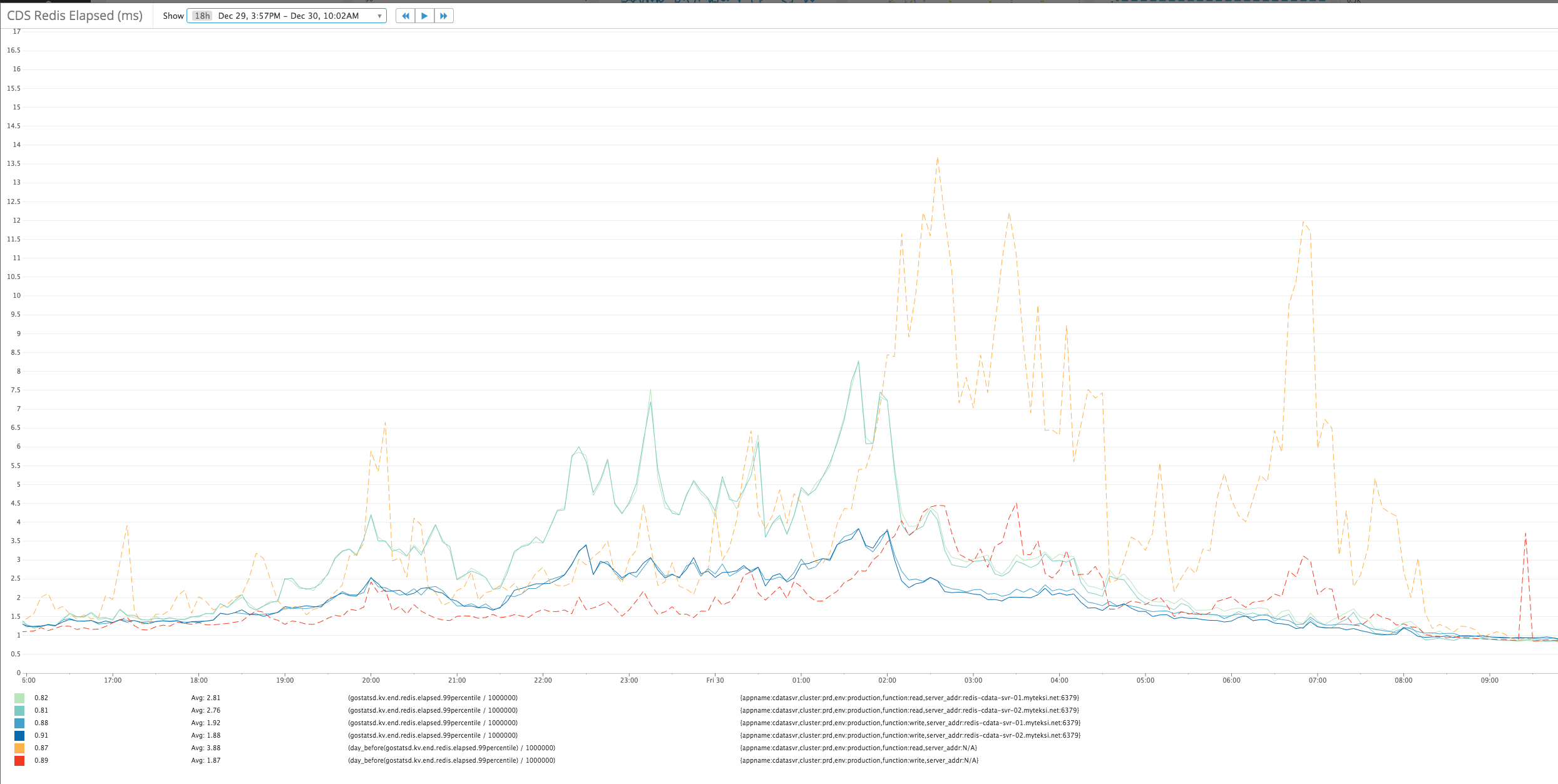
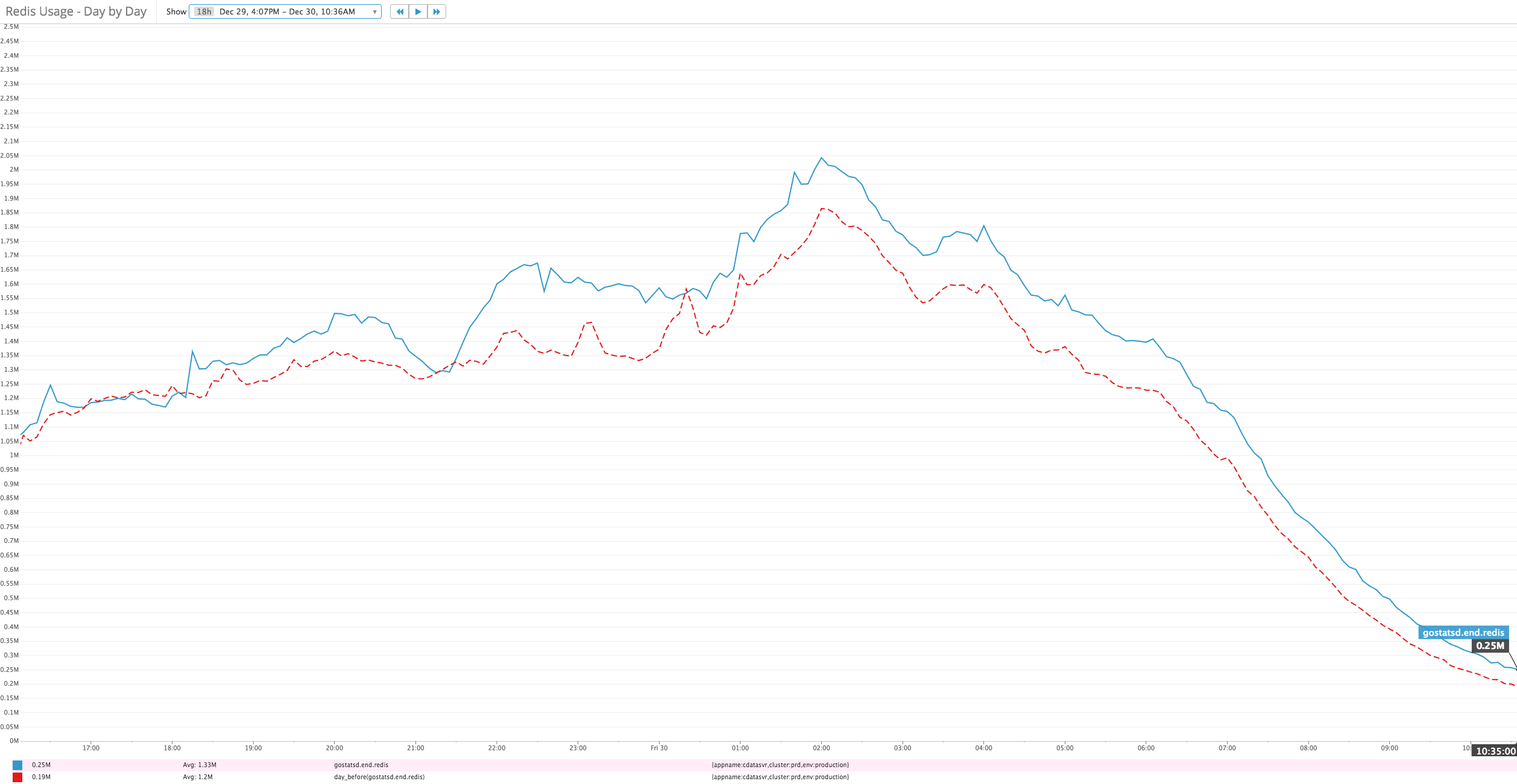
Many thanks to Jason Xu for his awesome consistent hashing package and Nguyen Qui Hieu for his discussion of this solution and help in setting up new ElasticCache nodes.
P.S. If you or your friends are interested in the work we are doing in Engineering Data and want to explore more, you are welcome to talk to us! We are eagerly looking for good engineers to grow our team!