
Safer deployment of streaming applications
The Flink framework has gained popularity as a real-time stateful stream processing solution for distributed stream and batch data processing. Flink also provides data distribution, communication, and fault tolerance for distributed computations over data streams. To fully leverage Flink’s features, Coban, Grab’s real-time data platform team, has adopted Flink as part of our service offerings.
In this article, we explore how we ensure that deploying Flink applications remain safe as we incorporate the lessons learned through our journey to continuous delivery.
Background
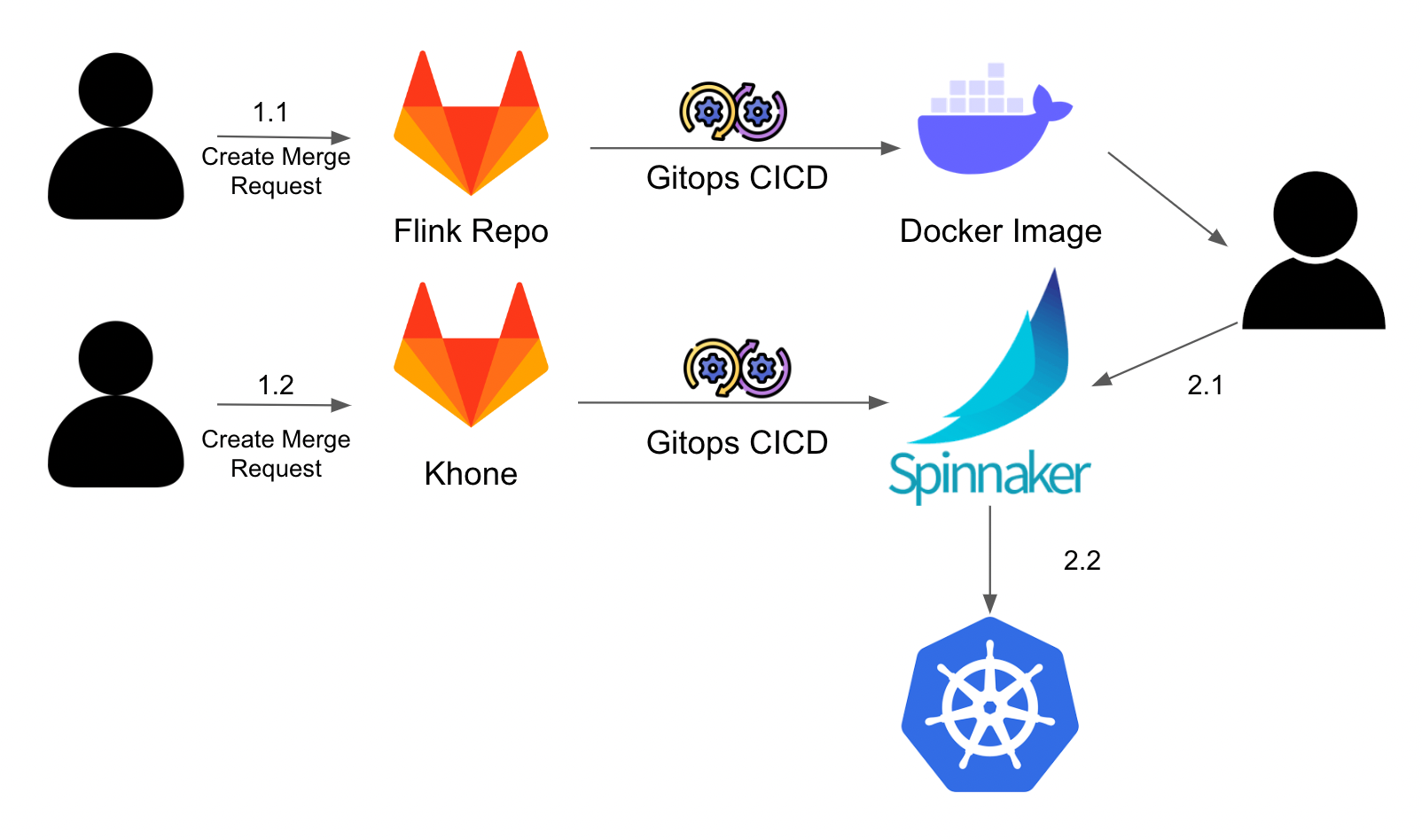
Users interact with our systems to develop and deploy Flink applications in three different ways.
Firstly, users create a Merge Request (MR) to develop their Flink applications on our Flink Scala repository, according to business requirements. After the MR is merged, GitOps Continuous Integration/Continuous Deployment (CI/CD) automatically runs and dockerises the application, allowing the containerised applications to be deployed easily.
Secondly, users create another MR to our infrastructure as a code repository. The GitOps CI/CD that is integrated with Terraform runs and configures the created Spinnaker application. This process configures the Flink application that will be deployed.
Finally, users trigger the actual deployment of the Flink applications on Spinnaker, which orchestrates the deployment of the Docker image onto our Kubernetes cluster. Flink applications are deployed as standalone clusters in Grab to ensure resource isolation.
Problem
The main issue we noticed with streaming pipelines like these, is that they are often interconnected, where application A depends on application B’s output. This makes it hard to find a solution that perfectly includes integration tests and ensures that propagated changes do not affect downstream applications.
However, this problem statement is too large to solve with a single solution. As such, we are narrowing the problem statement to focus on ensuring safety of our applications, where engineers can deploy Flink applications that will be rolled back if they fail health checks. In our case, the definition of a Flink application’s health is limited to the uptime of the Flink application itself.
It is worth noting that Flink applications are designed to be stateful streaming applications, meaning a “state” is shared between events (stream entities) and thus, past events can influence the way current events are processed. This also implies that traditional deployment strategies do not apply to the deployment of Flink applications.
Current strategy

In Figure 2, our current deployment stages are split into three parts:
- Delete current deployment: Remove current configurations (if applicable) to allow applications to pick up the new configurations.
- Bake (Manifest): Bake the Helm charts with the provided configurations.
- Deploy (Manifest): Deploy the charts onto Kubernetes.
Over time, we learnt that this strategy can be risky. Part 2 can result in a loss of Flink application states due to how internal CI/CD processes are set up. There is also no easy way to rollback if an issue arises. Engineers will need to revert all config changes and rollback the deployment manually by re-deploying the older Docker image – which results in slower operation recovery.
Lastly, there are no in-built monitoring mechanisms that perform regular health probes. Engineers need to manually monitor their applications to see if their deployment was successful or if they need to perform a rollback.
With all these issues, deploying Flink applications for engineers are often stressful and fraught with uncertainty. Common mitigation strategies are canary and blue-green deployments, which we cover in the next section.
Canary deployments

In canary deployments, you gradually roll out new versions of the application in parallel with the production version, while serving a percentage of total traffic before promoting it gradually.
This does not work for Flink deployments due to the nature of stream processing. Applications are frequently required to do streaming operations like stream joining, which involves matching related events in different Kafka topics. So, if a Flink application is only receiving a portion of the total traffic, the data generated will be considered inaccurate due to incomplete data inputs.
Blue-green deployments
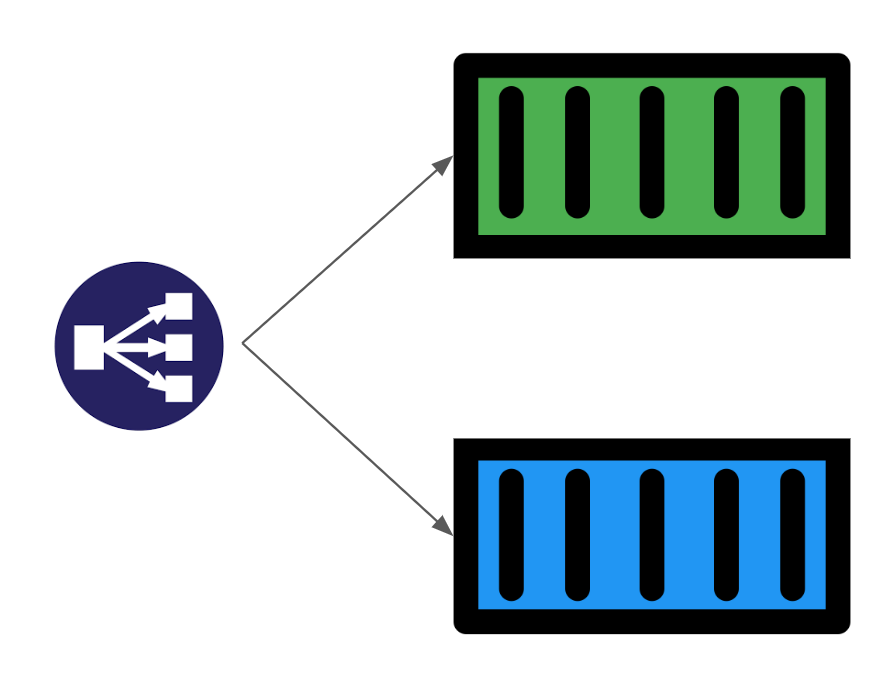
Blue-green deployments work by running two versions of the application with a Load Balancer that acts as a traffic switch, which determines which version traffic is directed to.
This method might work for Flink applications if we only allow one version of the application to consume Kafka messages at any point in time. However, we noticed some issues when switching traffic to another version. For example, the state of both versions will be inconsistent because of the different data traffic each version receives, which complicates the process of switching Kafka consumption traffic.
So if there’s a failure and we need to rollback from Green to Blue deployment, or vice versa, we will need to take an extra step and ensure that before the failure, the data traffic received is exactly the same for both deployments.
Solution
As previously mentioned, it is crucial for streaming applications to ensure that at any point in time, only one application is receiving data traffic to ensure data completeness and accuracy. Although employing blue-green deployments can technically fulfil this requirement, the process must be modified to handle state consistency such that both versions have the same starting internal state and receive the same data traffic as each other, if a rollback is needed.
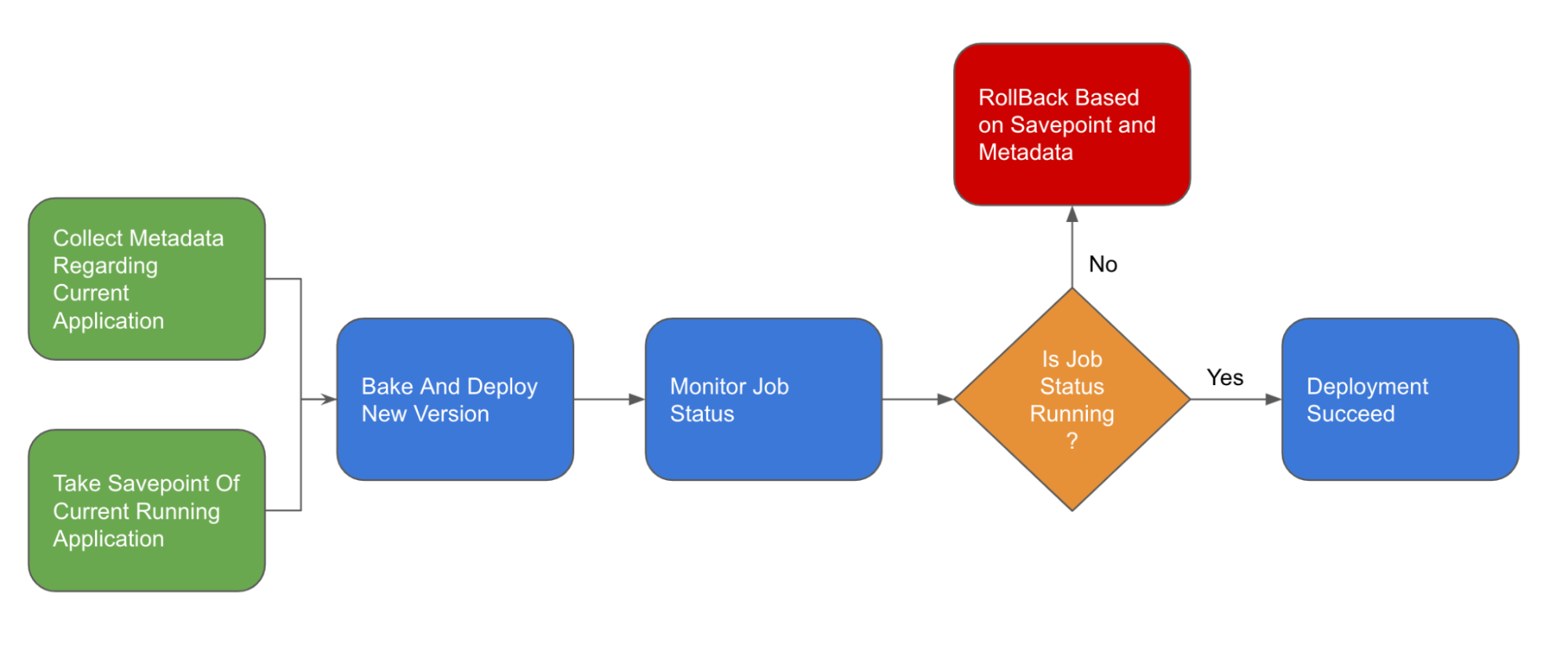
This deployment flow will operate in the following way:
- Collect metadata regarding current application
- Take savepoint and stop the current application
- Clear up high availability configurations
- Bake and deploy the new application
- Monitor application and rollback if the health check fails
Let’s elaborate on the key changes implemented in this new process.
Savepointing
Flink’s savepointing feature helps address the issue of state consistency and ensures safer deployments.
A savepoint in Flink is a snapshot of a Flink application’s state at the point in time. This savepoint allows us to pause the Flink application and restore the application to this snapshot state, if there’s an issue.
Before deploying a Flink application, we perform a savepoint via the Flink API before killing the current application. This would enable us to save the current state of the Flink application and rollback if our deployment fails – just like how you would do a quick save before attempting a difficult level when playing games. This mechanism ensures that both deployment versions have the same internal state during deployment as they both start from the same savepoint.
Additionally, this feature allows us to easily handle Kafka offsets since these consumed offsets are stored as part of the savepoint. As Flink manages their own state, they don’t need to rely on Kafka’s consumer offset management. With this savepoint feature, we can ensure that the application receives the same data traffic post rollback and that no messages are lost due to processing on the failed version.
Monitoring
To consistently monitor Flink applications, we can conduct health probes to the respective API endpoints to check if the application is stuck in a restart state or if it is running healthily.
We also configured our monitoring jobs to wait for a few minutes for the deployment to stabilise before probing it over a defined duration, to ensure that the application is in a stable running state.
Rollback
If the health checks fail, we then perform an automatic rollback. Typically, Flink applications are deployed as a standalone cluster and a rollback involves changes in one of the following:
- Application and Flink configurations
- Taskmanager or Jobmanager resource provision
Application and Flink configuration changes
For configuration changes, we leverage the fact that Spinnaker performs versioned deployment of configmap resources. In this case, a rollback simply involves mounting the old configmap back onto the Kubernetes deployment.
To retrieve the old version of the configmap mount, we can simply utilise Kubernetes’ rollback mechanisms – Kubernetes updates a deployment by creating a new replicaset with an incremental version before attaching it to the current deployment and scaling the previous replicaset to 0. To retrieve previous deployment specs, we just need to list all replicasets related to the deployment and find the previous deployed version, before updating the current deployment to mimic the previous template specifications.
However, this deployment does not contain the number of replicas of previously configured task managers. Kubernetes does not register the number of replicas as part of deployment configuration as this is a dynamic configuration and might be changed during processing due to auto scaling operations.
Our Flink applications are deployed as standalone clusters and do not use native or yarn resource providers. Coupled with the fact that Flink has strict resource provision, we realised that we do not have enough information to perform rollbacks, without the exact number of replicas created.
Taskmanager or Jobmanager resource provision changes
To gather information about resource provision changes, we can simply include the previously configured number of replicas as part of our metadata annotation. This allows us to retrieve it in future during rollback.
Making this change involves creating an additional step of metadata retrieval to retrieve and store previous deployment states as annotations of the new deployment.
Impact
With this solution, the deployment flow on Spinnaker looks like this:
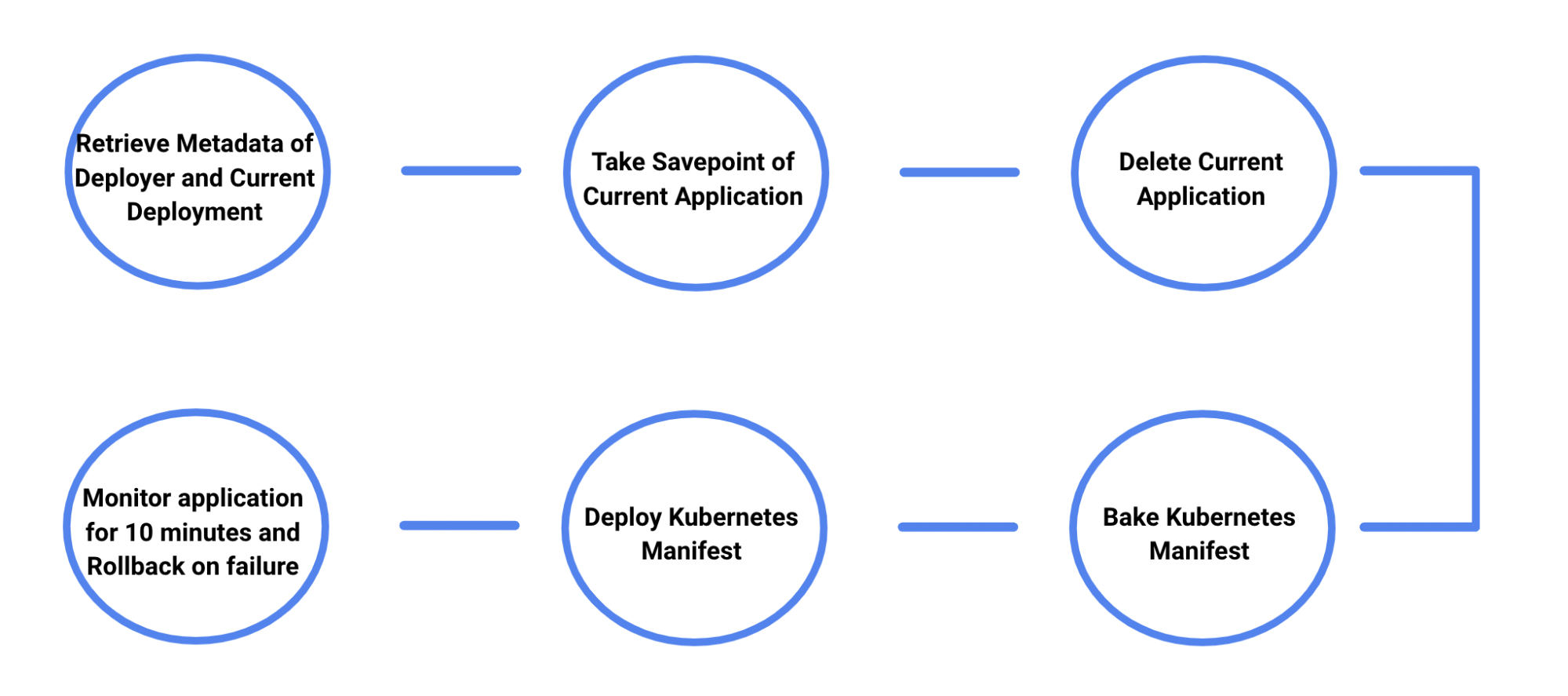
Engineers no longer need to monitor the deployment pipeline as closely as they get notified of their application’s deployment status via Slack. They only need to interact or take action when they get notified that the different stages of the deployment pipeline are completed.
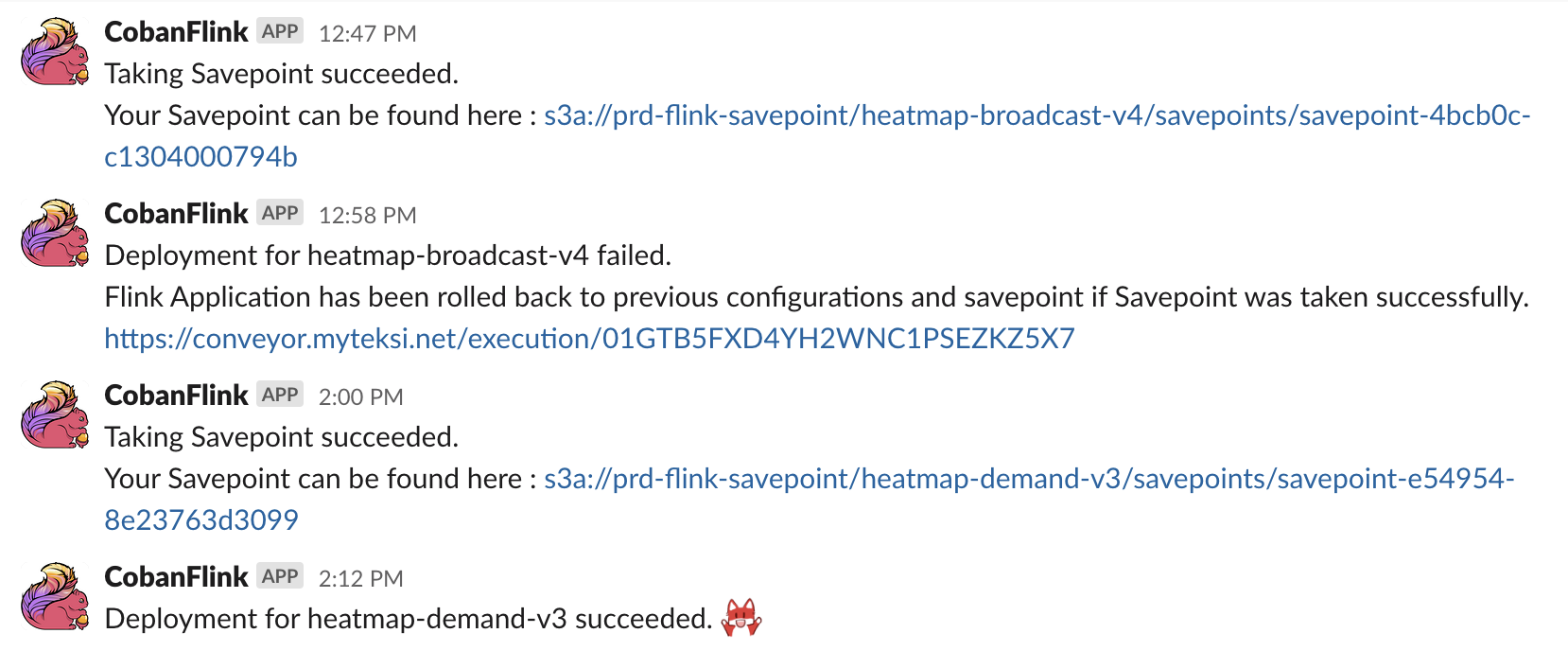
It is also easier to deploy Flink applications since failures and rollbacks are handled automatically. Furthermore, application state management is also automated, which reduces the amount of uncertainties.
What’s next?
As we work to further improve our deployment pipeline, we will look into extending the capabilities at our monitoring stage to allow engineers to define and configure their own health probes, allowing our deployment configurations to be more extendable.
Another interesting improvement will be to make this deployment flow seamlessly, ensuring as little downtime as possible by minimising cold start duration.
Coban also looks forward to pushing more features on our Flink platform to enable our engineers to explore more use cases that utilises real-time data to allow our operations to become auto adaptive and make data-driven decisions.
References
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!