
Scaling out Distroless adoption With AI
Distroless adoption at Grab
Grab is migrating from heavy base images to Distroless images to reduce security risks. By limiting each container to the application and its runtime dependencies, we shed non-essential binaries and associated Common Vulnerabilities and Exposures (CVEs).
This migration is more than a compliance mandate; it is a strategic security decision to build a more resilient environment.
Why Distroless requires rigorous testing
Distroless adoption risk: Runtime failure
Shifting to Distroless images introduces a critical technical risk: Runtime Failure. A service might build perfectly in Continuous Integration (CI), but fail at the deployment stage due to:
- Missing shared objects: Binaries might require specific libraries (.so files) present in Ubuntu but absent in Distroless.
- Implicit links: Third-party tools might expect specific system utilities or directory structures.
Testing is required to ensure two things:
- The service spins up with the correct configuration.
- All runtime dependencies remain intact.
Scaling this verification across thousands of services manually? That would take years, unless we found a way to automate the trust.
The testing methodology
As we perform changes to the Dockerfile definition of our services, it is important for us to include the corresponding test strategy to ensure that the changes that we make do not introduce a regression to our running services. Assessing the change introduced to our services, the lowest possible testing boundary would be that of what we define as medium tests in Grab.
Medium tests in Grab
At Grab, we categorize our test suites into 3 main sizes: small, medium and large. Small tests refer to functional tests whereby mocks are introduced via dependency injection. Large tests refer to end-to-end tests that run on actual services in our staging environment where nothing is mocked.
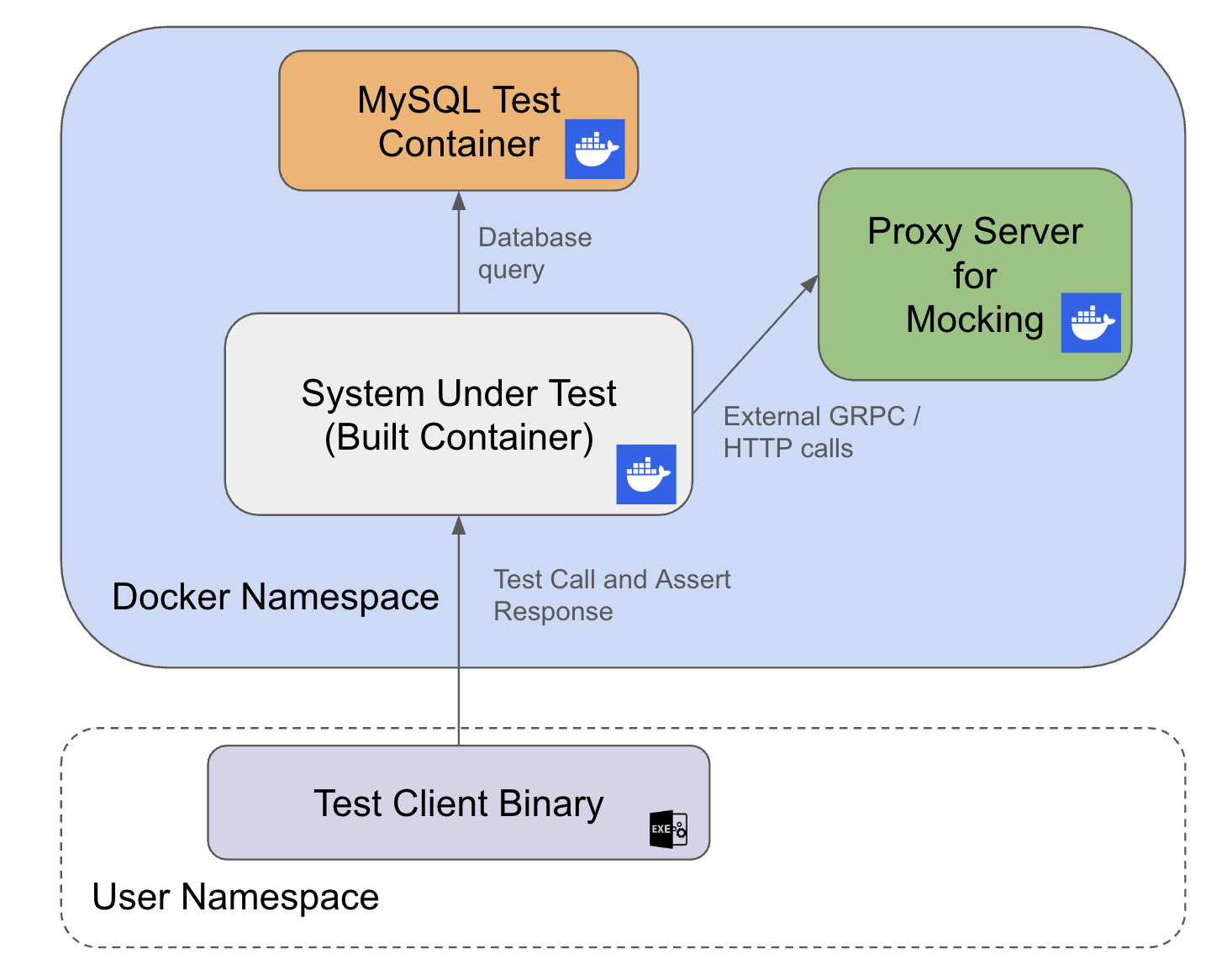
Medium tests sit between the small and large tests. External dependencies (such as service-to-service dependencies) are mocked with a network proxy layer similar to WireMock, while internal dependencies like MySQL are left unmocked and are started instead with Testcontainers. The system under test is built into a Docker image, run as a container, and exercised through its endpoints; the tests then assert on the responses. That setup lets us catch Dockerfile changes that would break the service in production. A further benefit is that the whole flow can run inside Continuous Integration (CI) so that problems surface before anything reaches Continuous Deployment (CD).
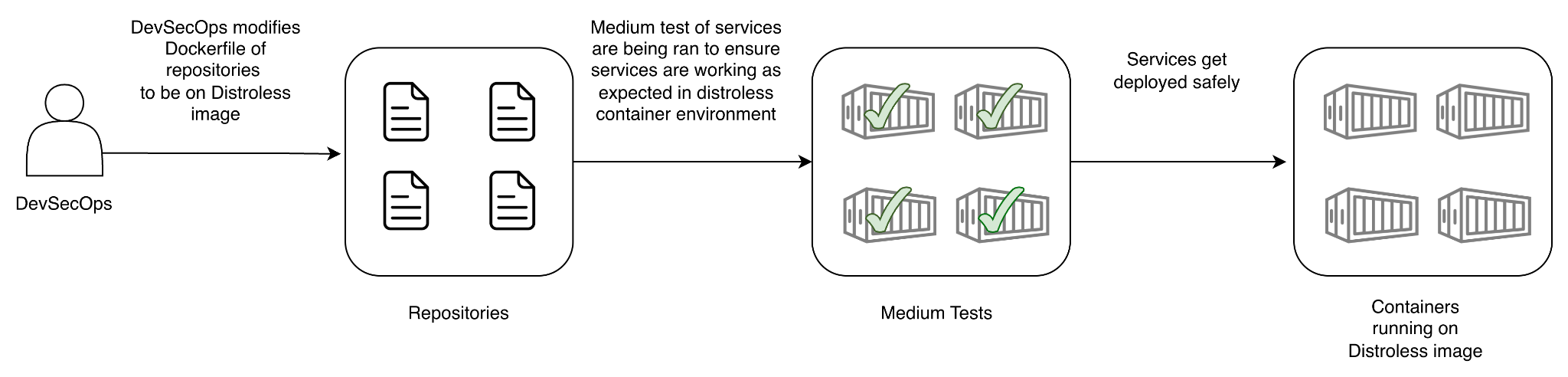
This makes medium tests effective and efficient for testing changes to the services associated with Distroless adoption. We could now largely scale up our adoption process by:
- Raising batch Merge Requests to dockerfile definitions for Distroless adoption.
- Running medium tests in CI.
- Upon passing the medium tests, automatically merge the changes and trigger CD.
Introduction of toil
The above methodology works well for services that already have medium tests. However, we soon ran into a blocker when rolling it out to services that do not yet have a medium test setup. Inherently, scaffolding medium tests for a service is a tedious task. Most of the toil comes from first identifying internal dependencies, then bringing up the corresponding test containers during tests, and then connecting those dependencies to the service under test by updating the test environment configuration.

These tasks are not challenging but are generally tedious to set up. They also cannot be fully automated because every service combines internal dependencies differently, and because configuration is defined and used in different ways across codebases. Roughly 400 services in scope still lack a medium test setup, which became a major obstacle to our Distroless migration campaign.
Since each step needs flexible execution and is only moderately complex, artificial intelligence (AI) is a natural way to accelerate Distroless adoption.
AI: The toil buster
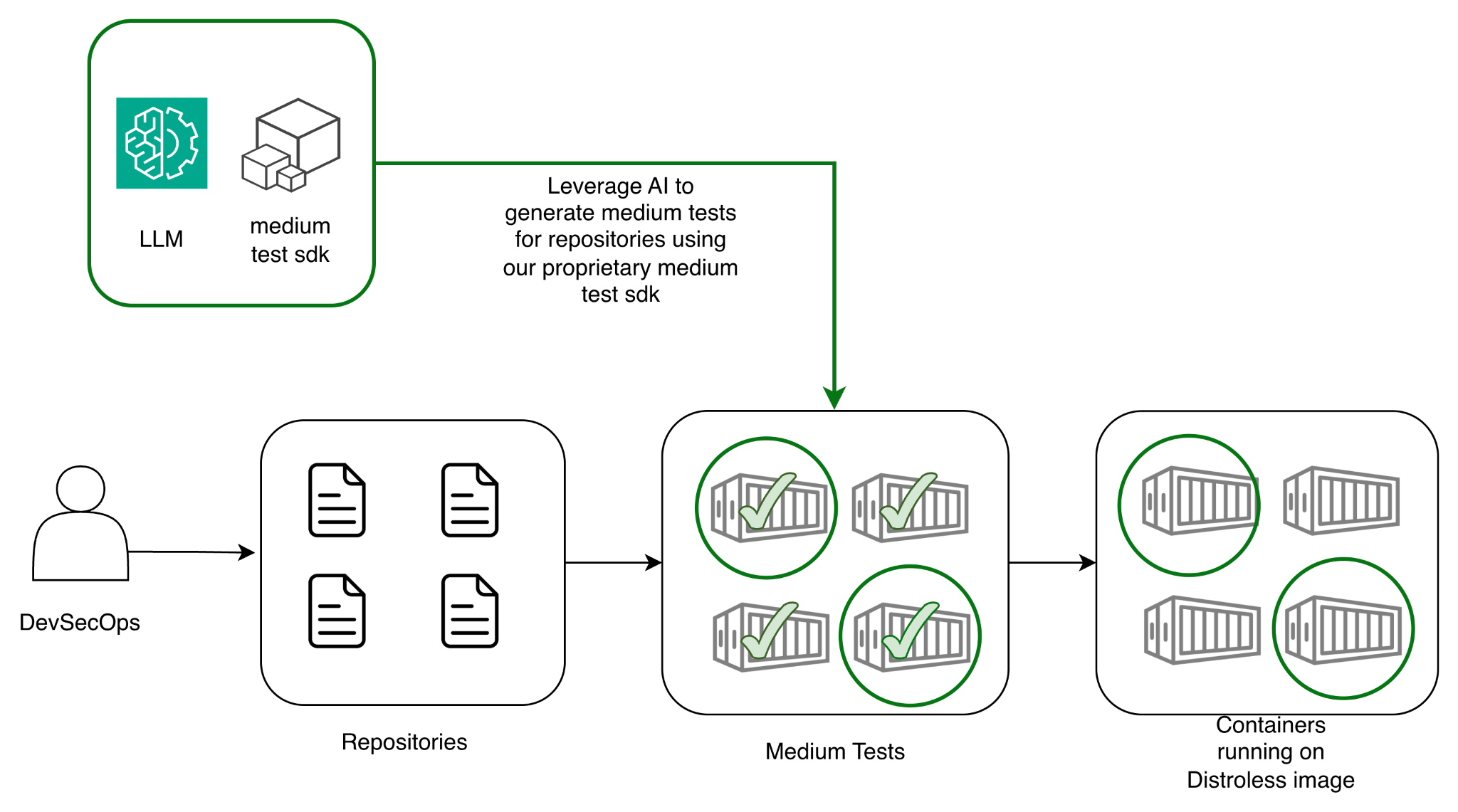
AI was a good fit because the work we needed to automate produced a clear deliverable and we could tell in a deterministic way whether it had succeeded. Success was straightforward: the CI pipeline would turn green after running the basic health-check medium tests. With a measurable end goal and a reliable success signal, we pursued an agentic workflow rather than a one-off generation attempt.
The starting point
We started by adopting skills to guide the agent on how to carry out the medium-test work and how to get past repo-specific blockers. These skills gave context for scaffolding basic medium tests, setting up internal dependencies, and debugging issues in the code. Once those foundations were in place, we rolled the approach out to a batch of 20 services, completed by the AI in about two working days. That run confirmed our core hypothesis: the agent could scaffold medium tests first, then rely on those tests to show that our Dockerfile change (using distroless image as a base image) had not introduced regressions.
Teaching an agent to test
By then, the real shift was turning “can do the task” into “can repeat the behavior.” We captured the medium-test knowledge as a list of skills, which were grounded in Grab’s internal medium test SDK.
Next, DevSecOps wrapped those skills into an Entrypoint Skill, an orchestrator that runs a multi-phase workflow across services. The result is a single agent loop that moves from candidate detection to scaffolding, fixing failures, and CI verification, without treating each service as a brand-new, one-off problem.
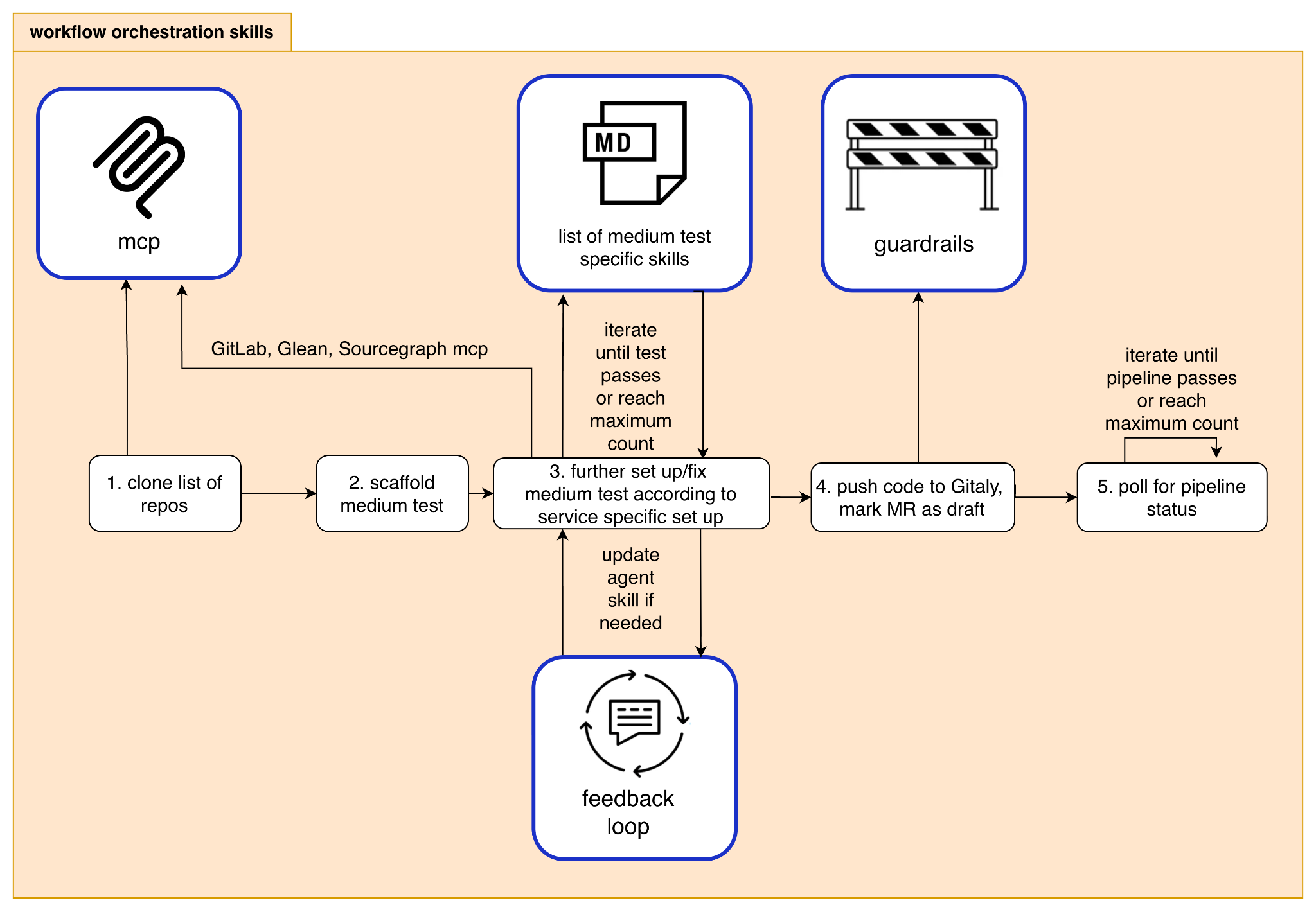
Leveraging the skills we have acquired, we utilized Claude Code, Anthropic’s agentic coding tool. This tool takes a list of services and processes them in a batch.
- Detect: Is this a deployable service or a library? Is it still maintained? The agent skips anything that does not qualify, so human time is only spent on real candidates.
- Scaffold: Using Grab’s scaffolding tool, the agent generates the medium test boilerplate.
- Fix: The scaffold rarely works on the first try due to the unique setup of each repository. This includes missing environment variables, database dependencies at startup, and port mismatches. The agent reviews its knowledge base to pattern-match errors against known fixes.
- Raise MR: Once the medium test passes locally, the agent creates a draft merge request on GitLab with a description explaining the service-specific changes and the rationale behind them.
- Monitor CI: The agent polls the pipeline, reads job logs on failure, and attempts CI-specific fixes. If the same error persists after two attempts, it flags the issue for human review.
- Repeat: It pushes the fix and moves to the next service while the pipeline runs. The agent does not sit idle waiting for CI. It starts scaffolding the next service in parallel and checks earlier pipelines as results arrive.
What made it work
Getting the workflow to function was the easy part. Getting it to function reliably across hundreds of services required deliberate design choices.
- MCP: The agent never leaves Claude Code. GitLab interactions such as creating branches, raising MRs and reading pipeline error logs happen through a Model Context Protocol (MCP) server. When it needs Grab-specific context (what a service does, who owns it), it queries Glean, Grab’s enterprise search tool, via MCP instead of guessing. For code-level context (how a service is structured and how dependencies are wired across repos), it queries Sourcegraph through its own MCP integration.
- Guardrails over autonomy: The agent can only touch test files and CI configurations; application code is off-limits, enforced before every commit. It might not hollow out tests to force a pass. If it cannot fix an issue, it escalates.
- Knowledge that compounds: We maintain a feedback loop for scaffolding, mocking, and known failure patterns. After each batch, we review what blocked the agent and fold recurring fixes back into the skill. The agent’s improvement is driven primarily by the iterative refinement of its instructions, rather than changes to the underlying model.
- Integrating Scripts with skills: For deterministic tasks like boilerplate generation, scripts are far more reliable than raw AI logic. By integrating these scripts as “skills,” we also optimize the agent’s performance in context window management. During test execution, standard output often produces hundreds of lines of repetitive logs that could exhaust token limits or distract the model. Using a script as an intermediary allows us to programmatically filter logs, extracting only the specific error messages or stack traces required for debugging. This ensures the AI receives a clean, actionable summary rather than being overwhelmed by noisy data.
- Token efficiency: Batches across many services burn tokens quickly. We use a compressed communication style that cuts model output by about 75% while keeping technical detail and dropping filler. Proper communication is reserved for MR descriptions and messages to service owners.
- Isolated execution: Each service gets its own context window (sub-agents). Long sessions processing dozens of services do not bloat the main conversation, keeping the agent focused and responsive.
- Human-in-the-loop: Every MR is a draft: a human reviews before anything merges. Humans also decide which learnings become permanent knowledge. The agent proposes; people approve.
From tests to migration at scale
With medium tests in place across our service fleet, we had the safety net we needed. The next step was automating the Distroless migration itself.
The Patch-Test-Compare loop
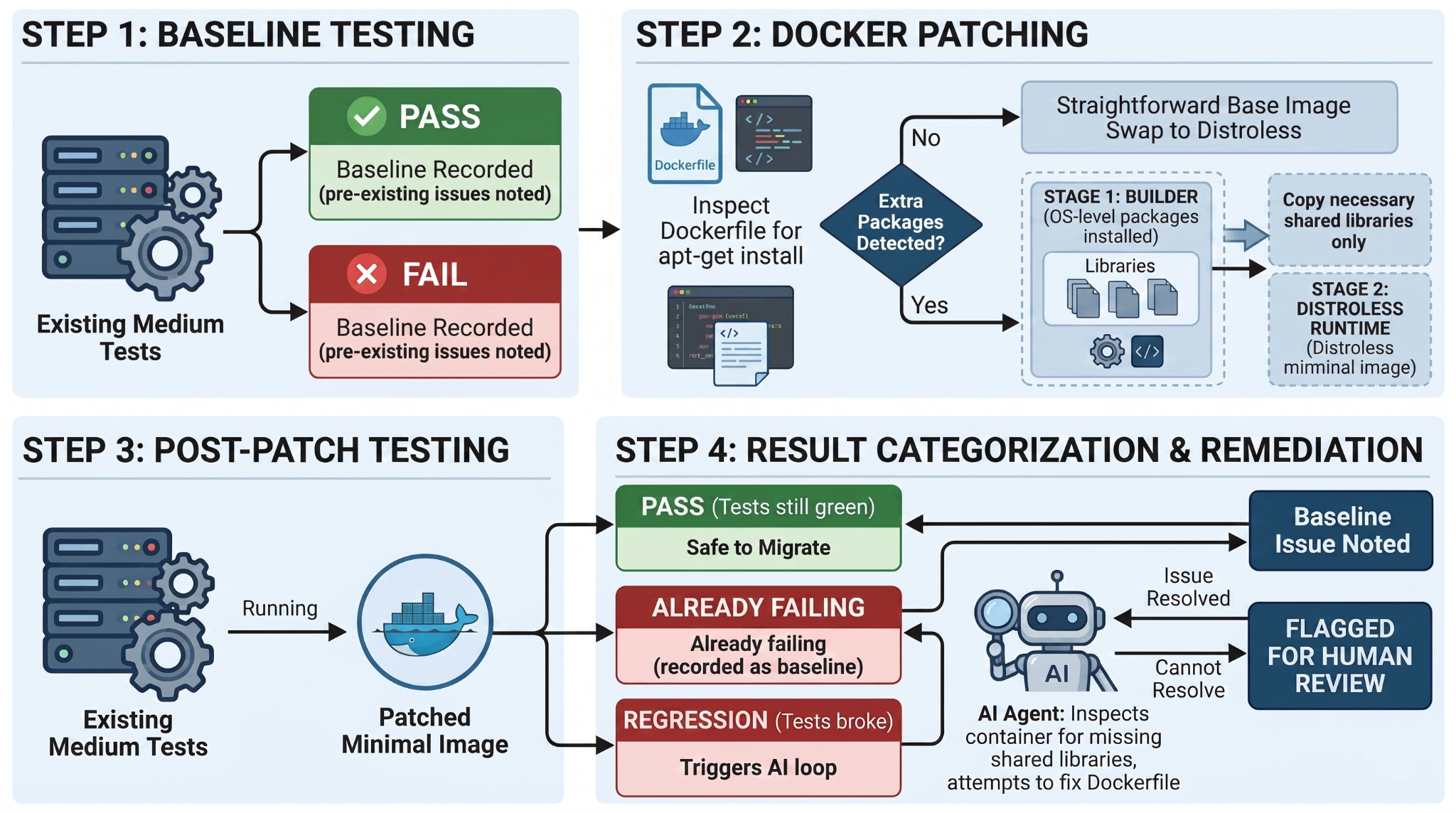
Before any Dockerfile changes, the system runs the service’s existing medium tests to establish a baseline. Pre-existing test failures are baselined, allowing for a clear distinction between legacy issues and new regressions introduced by the Distroless patch.
Next comes Distroless patching. The system inspects each service’s Dockerfile for OS-level package dependencies; scanning apt-get install lines and filtering out packages already included in the distroless base image. Two scenarios to consider here:
- If no extra packages are needed, it is a straightforward base image swap.
- If packages are detected, the system generates a multi-stage build: a builder stage installs the required packages, then copies only the necessary shared libraries into the Distroless runtime stage. The result is a minimal image that still contains everything the service needs to run.
After patching, the same medium tests run again. Results fall into clear categories: pass (tests still green - safe to migrate), regression (tests fail - the patch introduced a problem), or already failing (the suite was failing before we changed anything). Regressions trigger an automated remediation step: a separate AI agent inspects the container for missing shared libraries and attempts to fix the Dockerfile. If it cannot resolve the issue, the service is flagged for human review.
Scaling with batch changes
The previous section explains the patch-test-compare loop; this section addresses how we apply patching changes to more than one service simultaneously. To migrate at scale, we use batch change tooling that applies the Dockerfile transformation across dozens of repositories simultaneously, creating merge requests automatically. The system handles both standalone GitLab repositories and Grab’s shared Go monorepo, adapting the patching and MR strategy to each.
Impact on our services
Medium test generation at zcale
With medium tests in place, regressions are more likely to be caught before code reaches staging, which provides the safety guarantee we needed. Each generated test also becomes a lasting safety net for the service, not just for the Distroless migration but for future changes as well. Over roughly 1.5 months, the agent raised more than 100 medium test MRs across repositories, bringing more services into compliance with Grab’s “shift-left” testing initiative.
Distroless adoption
The campaign moved the needle across our service fleet: overall distroless adoption within our scope has grown substantially since we began using AI to drive the work.
Autonomous with oversight
For typical cases, the agent autonomously handles the majority of medium test generation and Dockerfile migration work with little human intervention. Engineers remain in the loop, reviewing every draft MR and making the final call on what merges.
Engineering bandwidth reclaimed
Manually generating a basic medium test requires familiarity with Grab’s internal SDK, typically taking one to three days per repository for developers new to the framework. For approximately 400 services lacking these tests, this equates to 400-1,200 engineer-days. By leveraging AI, we reduced the effort to roughly 0.1 days per service, compressing over a year’s worth of work into a fraction of the time. This allowed the team to focus on higher-leverage tasks, such as improving migration tooling, handling edge cases, and advancing the roadmap beyond Distroless.
Conclusion
The integration of Distroless images and enhanced medium test coverage significantly strengthens the security and verifiability of Grab’s services. This initiative demonstrates AI’s capacity to handle the heavy lifting required for large-scale migrations.
Join us
Grab is Southeast Asia’s leading superapp, serving over 900 cities across eight countries (Cambodia, Indonesia, Malaysia, Myanmar, the Philippines, Singapore, Thailand, and Vietnam). Through a single platform, millions of users access mobility, delivery, and digital financial services, including ride-hailing, food delivery, payments, lending, and digital banking via GXS Bank and GXBank. Founded in 2012, Grab’s mission is to drive Southeast Asia forward by creating economic empowerment for everyone while delivering sustainable financial performance and positive social impact.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!